
File size: 3,700 Bytes
bd11536 190bd83 bd11536 190bd83 bd11536 190bd83 7eb3e22 bd11536 45ea391 2e78e4b 1c3de2e e06c224 5239ff3 45ea391 5239ff3 45ea391 5239ff3 0ad19d7 5239ff3 0ad19d7 5239ff3 45ea391 e06c224 45ea391 e06c224 45ea391 e06c224 45ea391 e06c224 d403f06 e06c224 45ea391 e06c224 45ea391 e06c224 55166e2 bac9cde 45ea391 dc65c61 45ea391 00f3e9e cb5de8f 45ea391 9a16aaf b12b003 9a16aaf 45ea391 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 |
---
license: apache-2.0
datasets:
- hadyelsahar/ar_res_reviews
language:
- ar
metrics:
- accuracy
- precision
- recall
- f1
base_model:
- aubmindlab/bert-base-arabertv02
pipeline_tag: text-classification
tags:
- arabic
- sentiment-analysis
- transformers
- huggingface
- bert
- restaurants
- fine-tuning
- nlp
inference: true
---
# 🍽️ Arabic Restaurant Review Sentiment Analysis 🚀
## 📌 Overview
This **fine-tuned AraBERT model** classifies **Arabic restaurant reviews** as **Positive** or **Negative**.
It is based on **aubmindlab/bert-base-arabertv2** and fine-tuned using **Hugging Face Transformers**.
### **🔥 Why This Model?**
✅ **Trained on Real Restaurant Reviews** from the **Hugging Face Dataset**.
✅ **Fine-tuned with Full Training** (not LoRA or Adapters).
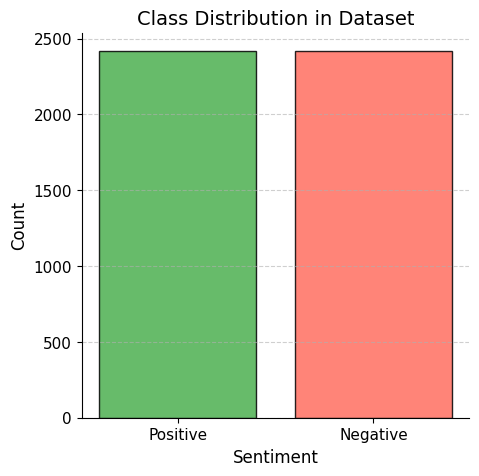
✅ **Balanced Dataset** (2418 Positive vs. 2418 Negative Reviews).
✅ **High Accuracy & Performance** for Sentiment Analysis in Arabic.
---
## 🚀 **Try the Model Now!**
**Run inference directly from the Hugging Face Space:**
<p align="center">
<a href="https://huggingface.co/spaces/Abduuu/Arabic-Reviews-Sentiment-Analysis">
<img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/open-in-hf-spaces-lg-dark.svg" alt="Open in HF Spaces" width="280px">
</a>
</p>
---
## **📥 Dataset & Preprocessing**
- **Dataset Source**: [`hadyelsahar/ar_res_reviews`](https://huggingface.co/datasets/hadyelsahar/ar_res_reviews)
- **Text Cleaning**:
- Removed **non-Arabic text**, special characters, and extra spaces.
- Normalized Arabic characters (`إ, أ, آ → ا`, `ة → ه`).
- Balanced **Positive & Negative** sentiment distribution.
- **Tokenization**:
- Used **AraBERT tokenizer** (`aubmindlab/bert-base-arabertv2`).
- **Train-Test Split**:
- **80% Training** | **20% Testing**.
---
## **🏋️ Training & Performance**
The model was fine-tuned using **Hugging Face Transformers** with the following hyperparameters:
### **📊 Final Model Results**
| Metric | Score |
|-------------|--------|
| **Eval Loss** | `0.354245` |
| **Accuracy** | `87.40%` |
| **Precision** | `85.28%` |
| **Recall** | `86.33%` |
| **F1-score** | `85.81%` |
### **⚙️ Training Configuration**
```python
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
save_strategy="epoch",
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=4,
weight_decay=1,
learning_rate=1e-5,
lr_scheduler_type="cosine",
warmup_ratio=0.1,
fp16=True,
save_total_limit=2,
gradient_accumulation_steps=2,
load_best_model_at_end=True,
max_grad_norm=1.0,
metric_for_best_model="eval_loss",
greater_is_better=False,
)
```
---
## **💡 Usage**
### **1️⃣ Quick Inference using `pipeline()`**
```python
from transformers import pipeline
model_name = "Abduuu/ArabReview-Sentiment"
sentiment_pipeline = pipeline("text-classification", model=model_name)
review = "الطعام كان رائعًا والخدمة ممتازة!"
result = sentiment_pipeline(review)
print(result)
```
✅ **Example Output:**
```json
[{'label': 'Positive', 'score': 0.91551274061203}]
```
---
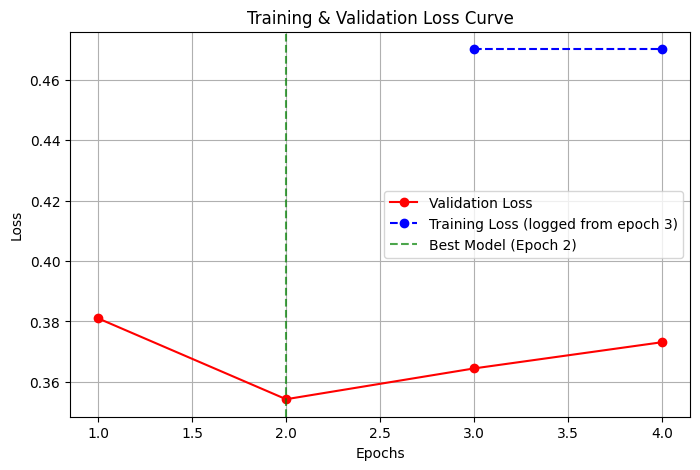
## 📉 Training & Validation Loss Curve
The model was trained for **4 epochs**, and the **best model** was selected at **Epoch 2** (lowest validation loss).
---
## 📊 Dataset Class Distribution
---
For questions or collaborations, feel free to reach out! 🚀
--- |