
Upload 71 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +2 -0
- .gitignore +162 -0
- Dockerfile +9 -0
- INSTALL.md +128 -0
- README.md +91 -0
- assets/cat.gif +0 -0
- assets/custom/face1.png +0 -0
- assets/custom/face2.png +0 -0
- assets/demo.png +0 -0
- assets/horse.gif +3 -0
- assets/mouse.gif +0 -0
- assets/nose.gif +3 -0
- assets/paper.png +0 -0
- colab.ipynb +76 -0
- draggan/__init__.py +3 -0
- draggan/deprecated/__init__.py +3 -0
- draggan/deprecated/api.py +244 -0
- draggan/deprecated/stylegan2/__init__.py +0 -0
- draggan/deprecated/stylegan2/inversion.py +209 -0
- draggan/deprecated/stylegan2/lpips/__init__.py +5 -0
- draggan/deprecated/stylegan2/lpips/base_model.py +58 -0
- draggan/deprecated/stylegan2/lpips/dist_model.py +314 -0
- draggan/deprecated/stylegan2/lpips/networks_basic.py +188 -0
- draggan/deprecated/stylegan2/lpips/pretrained_networks.py +181 -0
- draggan/deprecated/stylegan2/lpips/util.py +160 -0
- draggan/deprecated/stylegan2/model.py +713 -0
- draggan/deprecated/stylegan2/op/__init__.py +2 -0
- draggan/deprecated/stylegan2/op/conv2d_gradfix.py +229 -0
- draggan/deprecated/stylegan2/op/fused_act.py +157 -0
- draggan/deprecated/stylegan2/op/fused_bias_act.cpp +32 -0
- draggan/deprecated/stylegan2/op/fused_bias_act_kernel.cu +105 -0
- draggan/deprecated/stylegan2/op/upfirdn2d.cpp +31 -0
- draggan/deprecated/stylegan2/op/upfirdn2d.py +232 -0
- draggan/deprecated/stylegan2/op/upfirdn2d_kernel.cu +369 -0
- draggan/deprecated/utils.py +216 -0
- draggan/deprecated/web.py +319 -0
- draggan/draggan.py +355 -0
- draggan/stylegan2/LICENSE.txt +97 -0
- draggan/stylegan2/__init__.py +0 -0
- draggan/stylegan2/dnnlib/__init__.py +9 -0
- draggan/stylegan2/dnnlib/util.py +477 -0
- draggan/stylegan2/legacy.py +320 -0
- draggan/stylegan2/torch_utils/__init__.py +9 -0
- draggan/stylegan2/torch_utils/custom_ops.py +126 -0
- draggan/stylegan2/torch_utils/misc.py +262 -0
- draggan/stylegan2/torch_utils/ops/__init__.py +9 -0
- draggan/stylegan2/torch_utils/ops/bias_act.cpp +99 -0
- draggan/stylegan2/torch_utils/ops/bias_act.cu +173 -0
- draggan/stylegan2/torch_utils/ops/bias_act.h +38 -0
- draggan/stylegan2/torch_utils/ops/bias_act.py +212 -0
.gitattributes
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
assets/horse.gif filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
assets/nose.gif filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,162 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
share/python-wheels/
|
| 24 |
+
*.egg-info/
|
| 25 |
+
.installed.cfg
|
| 26 |
+
*.egg
|
| 27 |
+
MANIFEST
|
| 28 |
+
|
| 29 |
+
# PyInstaller
|
| 30 |
+
# Usually these files are written by a python script from a template
|
| 31 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 32 |
+
*.manifest
|
| 33 |
+
*.spec
|
| 34 |
+
|
| 35 |
+
# Installer logs
|
| 36 |
+
pip-log.txt
|
| 37 |
+
pip-delete-this-directory.txt
|
| 38 |
+
|
| 39 |
+
# Unit test / coverage reports
|
| 40 |
+
htmlcov/
|
| 41 |
+
.tox/
|
| 42 |
+
.nox/
|
| 43 |
+
.coverage
|
| 44 |
+
.coverage.*
|
| 45 |
+
.cache
|
| 46 |
+
nosetests.xml
|
| 47 |
+
coverage.xml
|
| 48 |
+
*.cover
|
| 49 |
+
*.py,cover
|
| 50 |
+
.hypothesis/
|
| 51 |
+
.pytest_cache/
|
| 52 |
+
cover/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
.pybuilder/
|
| 76 |
+
target/
|
| 77 |
+
|
| 78 |
+
# Jupyter Notebook
|
| 79 |
+
.ipynb_checkpoints
|
| 80 |
+
|
| 81 |
+
# IPython
|
| 82 |
+
profile_default/
|
| 83 |
+
ipython_config.py
|
| 84 |
+
|
| 85 |
+
# pyenv
|
| 86 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 87 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 88 |
+
# .python-version
|
| 89 |
+
|
| 90 |
+
# pipenv
|
| 91 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 92 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 93 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 94 |
+
# install all needed dependencies.
|
| 95 |
+
#Pipfile.lock
|
| 96 |
+
|
| 97 |
+
# poetry
|
| 98 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 99 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 100 |
+
# commonly ignored for libraries.
|
| 101 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 102 |
+
#poetry.lock
|
| 103 |
+
|
| 104 |
+
# pdm
|
| 105 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 106 |
+
#pdm.lock
|
| 107 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 108 |
+
# in version control.
|
| 109 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 110 |
+
.pdm.toml
|
| 111 |
+
|
| 112 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 113 |
+
__pypackages__/
|
| 114 |
+
|
| 115 |
+
# Celery stuff
|
| 116 |
+
celerybeat-schedule
|
| 117 |
+
celerybeat.pid
|
| 118 |
+
|
| 119 |
+
# SageMath parsed files
|
| 120 |
+
*.sage.py
|
| 121 |
+
|
| 122 |
+
# Environments
|
| 123 |
+
.env
|
| 124 |
+
.venv
|
| 125 |
+
env/
|
| 126 |
+
venv/
|
| 127 |
+
ENV/
|
| 128 |
+
env.bak/
|
| 129 |
+
venv.bak/
|
| 130 |
+
|
| 131 |
+
# Spyder project settings
|
| 132 |
+
.spyderproject
|
| 133 |
+
.spyproject
|
| 134 |
+
|
| 135 |
+
# Rope project settings
|
| 136 |
+
.ropeproject
|
| 137 |
+
|
| 138 |
+
# mkdocs documentation
|
| 139 |
+
/site
|
| 140 |
+
|
| 141 |
+
# mypy
|
| 142 |
+
.mypy_cache/
|
| 143 |
+
.dmypy.json
|
| 144 |
+
dmypy.json
|
| 145 |
+
|
| 146 |
+
# Pyre type checker
|
| 147 |
+
.pyre/
|
| 148 |
+
|
| 149 |
+
# pytype static type analyzer
|
| 150 |
+
.pytype/
|
| 151 |
+
|
| 152 |
+
# Cython debug symbols
|
| 153 |
+
cython_debug/
|
| 154 |
+
|
| 155 |
+
# PyCharm
|
| 156 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 157 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 158 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 159 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 160 |
+
.idea/
|
| 161 |
+
checkpoints/
|
| 162 |
+
tmp/
|
Dockerfile
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM python:3.7
|
| 2 |
+
|
| 3 |
+
WORKDIR /app
|
| 4 |
+
COPY . .
|
| 5 |
+
EXPOSE 7860
|
| 6 |
+
|
| 7 |
+
RUN pip install --no-cache-dir -r requirements.txt
|
| 8 |
+
|
| 9 |
+
ENTRYPOINT [ "python", "-m", "draggan.web", "--ip", "0.0.0.0"]
|
INSTALL.md
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Installation
|
| 2 |
+
|
| 3 |
+
- [System Requirements](#system-requirements)
|
| 4 |
+
- [Install with PyPI](#install-with-pypi)
|
| 5 |
+
- [Install Manually](#install-manually)
|
| 6 |
+
- [Install with Docker](#install-with-docker)
|
| 7 |
+
|
| 8 |
+
## System requirements
|
| 9 |
+
|
| 10 |
+
- This implementation support running on CPU, Nvidia GPU, and Apple's m1/m2 chips.
|
| 11 |
+
- When using with GPU, 8 GB memory is required for 1024 models. 6 GB is recommended for 512 models.
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
## Install with PyPI
|
| 15 |
+
|
| 16 |
+
📑 [Step by Step Tutorial](https://zeqiang-lai.github.io/blog/en/posts/drag_gan/) | [中文部署教程](https://zeqiang-lai.github.io/blog/posts/ai/drag_gan/)
|
| 17 |
+
|
| 18 |
+
We recommend to use Conda to install requirements.
|
| 19 |
+
|
| 20 |
+
```bash
|
| 21 |
+
conda create -n draggan python=3.7
|
| 22 |
+
conda activate draggan
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
Install PyTorch following the [official instructions](https://pytorch.org/get-started/locally/)
|
| 26 |
+
```bash
|
| 27 |
+
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
Install DragGAN
|
| 31 |
+
```bash
|
| 32 |
+
pip install draggan
|
| 33 |
+
# If you meet ERROR: Could not find a version that satisfies the requirement draggan (from versions: none), use
|
| 34 |
+
pip install draggan -i https://pypi.org/simple/
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
Launch the Gradio demo
|
| 38 |
+
|
| 39 |
+
```bash
|
| 40 |
+
# if you have a Nvidia GPU
|
| 41 |
+
python -m draggan.web
|
| 42 |
+
# if you use m1/m2 mac
|
| 43 |
+
python -m draggan.web --device mps
|
| 44 |
+
# otherwise
|
| 45 |
+
python -m draggan.web --device cpu
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
## Install Manually
|
| 49 |
+
|
| 50 |
+
Ensure you have a GPU and CUDA installed. We use Python 3.7 for testing, other versions (>= 3.7) of Python should work too, but not tested. We recommend to use [Conda](https://conda.io/projects/conda/en/stable/user-guide/install/download.html) to prepare all the requirements.
|
| 51 |
+
|
| 52 |
+
For Windows users, you might encounter some issues caused by StyleGAN custom ops, youd could find some solutions from the [issues pannel](https://github.com/Zeqiang-Lai/DragGAN/issues). We are also working on a more friendly package without setup.
|
| 53 |
+
|
| 54 |
+
```bash
|
| 55 |
+
git clone https://github.com/Zeqiang-Lai/DragGAN.git
|
| 56 |
+
cd DragGAN
|
| 57 |
+
conda create -n draggan python=3.7
|
| 58 |
+
conda activate draggan
|
| 59 |
+
pip install -r requirements.txt
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
Launch the Gradio demo
|
| 63 |
+
|
| 64 |
+
```bash
|
| 65 |
+
# if you have a Nvidia GPU
|
| 66 |
+
python gradio_app.py
|
| 67 |
+
# if you use m1/m2 mac
|
| 68 |
+
python gradio_app.py --device mps
|
| 69 |
+
# otherwise
|
| 70 |
+
python gradio_app.py --device cpu
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
> If you have any issue for downloading the checkpoint, you could manually download it from [here](https://huggingface.co/aaronb/StyleGAN2/tree/main) and put it into the folder `checkpoints`.
|
| 74 |
+
|
| 75 |
+
## Install with Docker
|
| 76 |
+
|
| 77 |
+
Follow these steps to run DragGAN using Docker:
|
| 78 |
+
|
| 79 |
+
### Prerequisites
|
| 80 |
+
|
| 81 |
+
1. Install Docker on your system from the [official Docker website](https://www.docker.com/).
|
| 82 |
+
2. Ensure that your system has [NVIDIA Docker support](https://github.com/NVIDIA/nvidia-docker) if you are using GPUs.
|
| 83 |
+
|
| 84 |
+
### Run using docker Hub image
|
| 85 |
+
|
| 86 |
+
```bash
|
| 87 |
+
# For GPU
|
| 88 |
+
docker run -t -p 7860:7860 --gpus all baydarov/draggan
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
```bash
|
| 92 |
+
# For CPU only (not recommended)
|
| 93 |
+
docker run -t -p 7860:7860 baydarov/draggan --device cpu
|
| 94 |
+
```
|
| 95 |
+
|
| 96 |
+
### Step-by-step Guide with building image locally
|
| 97 |
+
|
| 98 |
+
1. Clone the DragGAN repository and build the Docker image:
|
| 99 |
+
|
| 100 |
+
```bash
|
| 101 |
+
git clone https://github.com/Zeqiang-Lai/DragGAN.git # clone repo
|
| 102 |
+
cd DragGAN # change into the repo directory
|
| 103 |
+
docker build -t draggan . # build image
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
2. Run the DragGAN Docker container:
|
| 107 |
+
|
| 108 |
+
```bash
|
| 109 |
+
# For GPU
|
| 110 |
+
docker run -t -p 7860:7860 --gpus all draggan
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
```bash
|
| 114 |
+
# For CPU (not recommended)
|
| 115 |
+
docker run -t -p 7860:7860 draggan --device cpu
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
3. The DragGAN Web UI will be accessible once you see the following output in your console:
|
| 119 |
+
|
| 120 |
+
```
|
| 121 |
+
...
|
| 122 |
+
Running on local URL: http://0.0.0.0:7860
|
| 123 |
+
...
|
| 124 |
+
```
|
| 125 |
+
|
| 126 |
+
Visit [http://localhost:7860](http://localhost:7860/) to access the Web UI.
|
| 127 |
+
|
| 128 |
+
That's it! You're now running DragGAN in a Docker container.
|
README.md
ADDED
|
@@ -0,0 +1,91 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# DragGAN
|
| 2 |
+
[](https://pypi.org/project/draggan/)
|
| 3 |
+
[](#running-locally)
|
| 4 |
+
|
| 5 |
+
:boom: [`Colab Demo`](https://colab.research.google.com/github/Zeqiang-Lai/DragGAN/blob/master/colab.ipynb) [`Awesome-DragGAN`](https://github.com/OpenGVLab/Awesome-DragGAN) [`InternGPT Demo`](https://github.com/OpenGVLab/InternGPT) [`Local Deployment`](#running-locally)
|
| 6 |
+
|
| 7 |
+
> **Note for Colab, remember to select a GPU via `Runtime/Change runtime type` (`代码执行程序/更改运行时类型`).**
|
| 8 |
+
>
|
| 9 |
+
> If you want to upload custom image, please install 1.1.0 via `pip install draggan==1.1.0`.
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
Unofficial implementation of [Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold](https://vcai.mpi-inf.mpg.de/projects/DragGAN/)
|
| 13 |
+
|
| 14 |
+
<p float="left">
|
| 15 |
+
<img src="assets/mouse.gif" width="200" />
|
| 16 |
+
<img src="assets/nose.gif" width="200" />
|
| 17 |
+
<img src="assets/cat.gif" width="200" />
|
| 18 |
+
<img src="assets/horse.gif" width="200" />
|
| 19 |
+
</p>
|
| 20 |
+
|
| 21 |
+
## How it Work ?
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
Here is a simple tutorial video showing how to use our implementation.
|
| 25 |
+
|
| 26 |
+
https://github.com/Zeqiang-Lai/DragGAN/assets/26198430/f1516101-5667-4f73-9330-57fc45754283
|
| 27 |
+
|
| 28 |
+
Check out the original [paper](https://vcai.mpi-inf.mpg.de/projects/DragGAN/) for the backend algorithm and math.
|
| 29 |
+
|
| 30 |
+

|
| 31 |
+
|
| 32 |
+
## News
|
| 33 |
+
|
| 34 |
+
:star2: **What's New**
|
| 35 |
+
|
| 36 |
+
- [2023/6/25] Relase version 1.1.1, it includes a major bug fix and speed improvement.
|
| 37 |
+
- [2023/6/25] [Official Code](https://github.com/XingangPan/DragGAN) is released, check it out.
|
| 38 |
+
- [2023/5/29] A new version is in beta, install via `pip install draggan==1.1.0b2`, includes speed improvement and more models.
|
| 39 |
+
- [2023/5/25] DragGAN is on PyPI, simple install via `pip install draggan`. Also addressed the common CUDA problems https://github.com/Zeqiang-Lai/DragGAN/issues/38 https://github.com/Zeqiang-Lai/DragGAN/issues/12
|
| 40 |
+
- [2023/5/25] We now support StyleGAN2-ada with much higher quality and more types of images. Try it by selecting models started with "ada".
|
| 41 |
+
- [2023/5/24] An out-of-box online demo is integrated in [InternGPT](https://github.com/OpenGVLab/InternGPT) - a super cool pointing-language-driven visual interactive system. Enjoy for free.:lollipop:
|
| 42 |
+
- [2023/5/24] Custom Image with GAN inversion is supported, but it is possible that your custom images are distorted due to the limitation of GAN inversion. Besides, it is also possible the manipulations fail due to the limitation of our implementation.
|
| 43 |
+
|
| 44 |
+
:star2: **Changelog**
|
| 45 |
+
|
| 46 |
+
- [x] Add a docker image, thanks [@egbaydarov](https://github.com/egbaydarov).
|
| 47 |
+
- [ ] PTI GAN inversion https://github.com/Zeqiang-Lai/DragGAN/issues/71#issuecomment-1573461314
|
| 48 |
+
- [x] Tweak performance, See [v2](https://github.com/Zeqiang-Lai/DragGAN/tree/v2).
|
| 49 |
+
- [x] Improving installation experience, DragGAN is now on [PyPI](https://pypi.org/project/draggan).
|
| 50 |
+
- [x] Automatically determining the number of iterations, See [v2](https://github.com/Zeqiang-Lai/DragGAN/tree/v2).
|
| 51 |
+
- [ ] Allow to save video without point annotations, custom image size.
|
| 52 |
+
- [x] Support StyleGAN2-ada.
|
| 53 |
+
- [x] Integrate into [InternGPT](https://github.com/OpenGVLab/InternGPT)
|
| 54 |
+
- [x] Custom Image with GAN inversion.
|
| 55 |
+
- [x] Download generated image and generation trajectory.
|
| 56 |
+
- [x] Controlling generation process with GUI.
|
| 57 |
+
- [x] Automatically download stylegan2 checkpoint.
|
| 58 |
+
- [x] Support movable region, multiple handle points.
|
| 59 |
+
- [x] Gradio and Colab Demo.
|
| 60 |
+
|
| 61 |
+
> This project is now a sub-project of [InternGPT](https://github.com/OpenGVLab/InternGPT) for interactive image editing. Future updates of more cool tools beyond DragGAN would be added in [InternGPT](https://github.com/OpenGVLab/InternGPT).
|
| 62 |
+
|
| 63 |
+
## Running Locally
|
| 64 |
+
|
| 65 |
+
Please refer to [INSTALL.md](INSTALL.md).
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
## Citation
|
| 69 |
+
|
| 70 |
+
```bibtex
|
| 71 |
+
@inproceedings{pan2023draggan,
|
| 72 |
+
title={Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold},
|
| 73 |
+
author={Pan, Xingang and Tewari, Ayush, and Leimk{\"u}hler, Thomas and Liu, Lingjie and Meka, Abhimitra and Theobalt, Christian},
|
| 74 |
+
booktitle = {ACM SIGGRAPH 2023 Conference Proceedings},
|
| 75 |
+
year={2023}
|
| 76 |
+
}
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
## Acknowledgement
|
| 81 |
+
|
| 82 |
+
[Official DragGAN](https://github.com/XingangPan/DragGAN)   [DragGAN-Streamlit](https://github.com/skimai/DragGAN)   [StyleGAN2](https://github.com/NVlabs/stylegan2)   [StyleGAN2-pytorch](https://github.com/rosinality/stylegan2-pytorch)   [StyleGAN2-Ada](https://github.com/NVlabs/stylegan2-ada-pytorch)   [StyleGAN-Human](https://github.com/stylegan-human/StyleGAN-Human)   [Self-Distilled-StyleGAN](https://github.com/self-distilled-stylegan/self-distilled-internet-photos)
|
| 83 |
+
|
| 84 |
+
Welcome to discuss with us and continuously improve the user experience of DragGAN.
|
| 85 |
+
Reach us with this WeChat QR Code.
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
<p align="left"><img width="300" alt="image" src="https://github.com/OpenGVLab/DragGAN/assets/26198430/885cb87a-4acc-490d-8a45-96f3ab870611"><img width="300" alt="image" src="https://github.com/OpenGVLab/DragGAN/assets/26198430/e3f0807f-956a-474e-8fd2-1f7c22d73997"></p>
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
|
assets/cat.gif
ADDED

|
assets/custom/face1.png
ADDED

|
assets/custom/face2.png
ADDED

|
assets/demo.png
ADDED

|
assets/horse.gif
ADDED

|
Git LFS Details
|
assets/mouse.gif
ADDED

|
assets/nose.gif
ADDED

|
Git LFS Details
|
assets/paper.png
ADDED
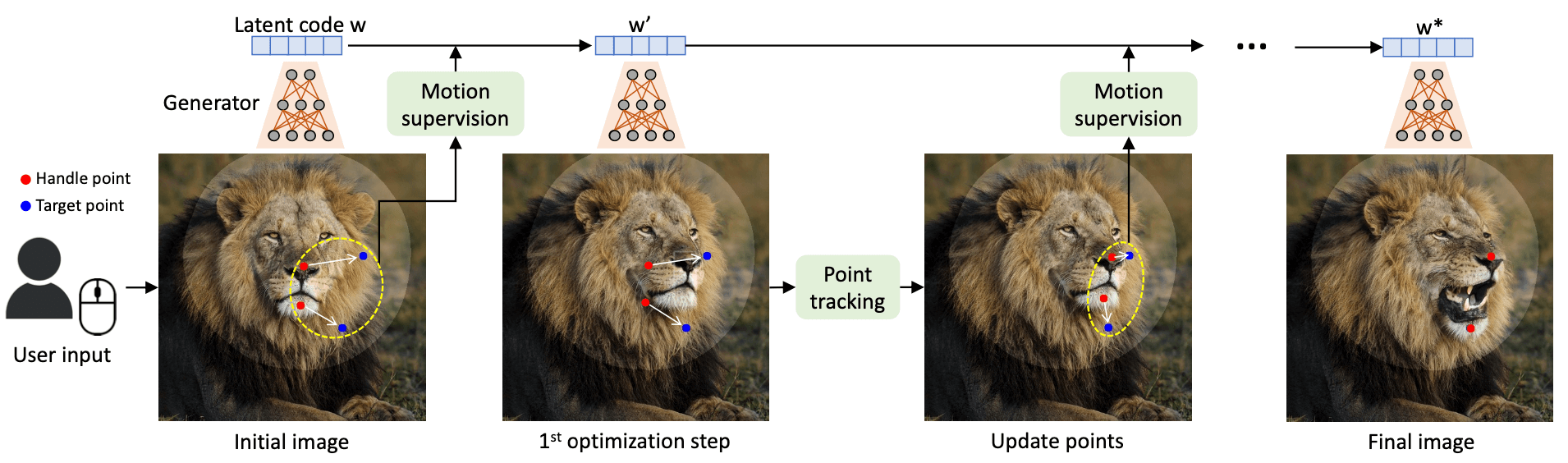
|
colab.ipynb
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"attachments": {},
|
| 5 |
+
"cell_type": "markdown",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# DragGAN Colab Demo\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"Wild implementation of [Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold](https://vcai.mpi-inf.mpg.de/projects/DragGAN/)\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"**Note for Colab, remember to select a GPU via `Runtime/Change runtime type` (`代码执行程序/更改运行时类型`).**"
|
| 13 |
+
]
|
| 14 |
+
},
|
| 15 |
+
{
|
| 16 |
+
"cell_type": "code",
|
| 17 |
+
"execution_count": null,
|
| 18 |
+
"metadata": {},
|
| 19 |
+
"outputs": [],
|
| 20 |
+
"source": [
|
| 21 |
+
"#@title Installation\n",
|
| 22 |
+
"!git clone https://github.com/Zeqiang-Lai/DragGAN.git\n",
|
| 23 |
+
"\n",
|
| 24 |
+
"import sys\n",
|
| 25 |
+
"sys.path.append(\".\")\n",
|
| 26 |
+
"sys.path.append('./DragGAN')\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"!pip install -r DragGAN/requirements.txt\n",
|
| 29 |
+
"\n",
|
| 30 |
+
"from gradio_app import main"
|
| 31 |
+
]
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
"attachments": {},
|
| 35 |
+
"cell_type": "markdown",
|
| 36 |
+
"metadata": {},
|
| 37 |
+
"source": [
|
| 38 |
+
"**If you have problem in the following demo, such as the incorrected image, or facing errors. Please try to run the following block again.**\n",
|
| 39 |
+
"\n",
|
| 40 |
+
"If the errors still exist, you could fire an issue on [Github](https://github.com/Zeqiang-Lai/DragGAN)."
|
| 41 |
+
]
|
| 42 |
+
},
|
| 43 |
+
{
|
| 44 |
+
"cell_type": "code",
|
| 45 |
+
"execution_count": null,
|
| 46 |
+
"metadata": {},
|
| 47 |
+
"outputs": [],
|
| 48 |
+
"source": [
|
| 49 |
+
"demo = main()\n",
|
| 50 |
+
"demo.queue(concurrency_count=1, max_size=20).launch()"
|
| 51 |
+
]
|
| 52 |
+
}
|
| 53 |
+
],
|
| 54 |
+
"metadata": {
|
| 55 |
+
"kernelspec": {
|
| 56 |
+
"display_name": "torch1.10",
|
| 57 |
+
"language": "python",
|
| 58 |
+
"name": "python3"
|
| 59 |
+
},
|
| 60 |
+
"language_info": {
|
| 61 |
+
"codemirror_mode": {
|
| 62 |
+
"name": "ipython",
|
| 63 |
+
"version": 3
|
| 64 |
+
},
|
| 65 |
+
"file_extension": ".py",
|
| 66 |
+
"mimetype": "text/x-python",
|
| 67 |
+
"name": "python",
|
| 68 |
+
"nbconvert_exporter": "python",
|
| 69 |
+
"pygments_lexer": "ipython3",
|
| 70 |
+
"version": "3.7.12"
|
| 71 |
+
},
|
| 72 |
+
"orig_nbformat": 4
|
| 73 |
+
},
|
| 74 |
+
"nbformat": 4,
|
| 75 |
+
"nbformat_minor": 2
|
| 76 |
+
}
|
draggan/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .utils import BASE_DIR
|
| 2 |
+
|
| 3 |
+
home = BASE_DIR
|
draggan/deprecated/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .utils import BASE_DIR
|
| 2 |
+
|
| 3 |
+
home = BASE_DIR
|
draggan/deprecated/api.py
ADDED
|
@@ -0,0 +1,244 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import random
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn.functional as FF
|
| 6 |
+
import torch.optim
|
| 7 |
+
|
| 8 |
+
from . import utils
|
| 9 |
+
from .stylegan2.model import Generator
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class CustomGenerator(Generator):
|
| 13 |
+
def prepare(
|
| 14 |
+
self,
|
| 15 |
+
styles,
|
| 16 |
+
inject_index=None,
|
| 17 |
+
truncation=1,
|
| 18 |
+
truncation_latent=None,
|
| 19 |
+
input_is_latent=False,
|
| 20 |
+
noise=None,
|
| 21 |
+
randomize_noise=True,
|
| 22 |
+
):
|
| 23 |
+
if not input_is_latent:
|
| 24 |
+
styles = [self.style(s) for s in styles]
|
| 25 |
+
|
| 26 |
+
if noise is None:
|
| 27 |
+
if randomize_noise:
|
| 28 |
+
noise = [None] * self.num_layers
|
| 29 |
+
else:
|
| 30 |
+
noise = [
|
| 31 |
+
getattr(self.noises, f"noise_{i}") for i in range(self.num_layers)
|
| 32 |
+
]
|
| 33 |
+
|
| 34 |
+
if truncation < 1:
|
| 35 |
+
style_t = []
|
| 36 |
+
|
| 37 |
+
for style in styles:
|
| 38 |
+
style_t.append(
|
| 39 |
+
truncation_latent + truncation * (style - truncation_latent)
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
styles = style_t
|
| 43 |
+
|
| 44 |
+
if len(styles) < 2:
|
| 45 |
+
inject_index = self.n_latent
|
| 46 |
+
|
| 47 |
+
if styles[0].ndim < 3:
|
| 48 |
+
latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
|
| 49 |
+
|
| 50 |
+
else:
|
| 51 |
+
latent = styles[0]
|
| 52 |
+
|
| 53 |
+
else:
|
| 54 |
+
if inject_index is None:
|
| 55 |
+
inject_index = random.randint(1, self.n_latent - 1)
|
| 56 |
+
|
| 57 |
+
latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
|
| 58 |
+
latent2 = styles[1].unsqueeze(1).repeat(1, self.n_latent - inject_index, 1)
|
| 59 |
+
|
| 60 |
+
latent = torch.cat([latent, latent2], 1)
|
| 61 |
+
|
| 62 |
+
return latent, noise
|
| 63 |
+
|
| 64 |
+
def generate(
|
| 65 |
+
self,
|
| 66 |
+
latent,
|
| 67 |
+
noise,
|
| 68 |
+
):
|
| 69 |
+
out = self.input(latent)
|
| 70 |
+
out = self.conv1(out, latent[:, 0], noise=noise[0])
|
| 71 |
+
|
| 72 |
+
skip = self.to_rgb1(out, latent[:, 1])
|
| 73 |
+
i = 1
|
| 74 |
+
for conv1, conv2, noise1, noise2, to_rgb in zip(
|
| 75 |
+
self.convs[::2], self.convs[1::2], noise[1::2], noise[2::2], self.to_rgbs
|
| 76 |
+
):
|
| 77 |
+
out = conv1(out, latent[:, i], noise=noise1)
|
| 78 |
+
out = conv2(out, latent[:, i + 1], noise=noise2)
|
| 79 |
+
skip = to_rgb(out, latent[:, i + 2], skip)
|
| 80 |
+
if out.shape[-1] == 256: F = out
|
| 81 |
+
i += 2
|
| 82 |
+
|
| 83 |
+
image = skip
|
| 84 |
+
F = FF.interpolate(F, image.shape[-2:], mode='bilinear')
|
| 85 |
+
return image, F
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def stylegan2(
|
| 89 |
+
size=1024,
|
| 90 |
+
channel_multiplier=2,
|
| 91 |
+
latent=512,
|
| 92 |
+
n_mlp=8,
|
| 93 |
+
ckpt='stylegan2-ffhq-config-f.pt'
|
| 94 |
+
):
|
| 95 |
+
g_ema = CustomGenerator(size, latent, n_mlp, channel_multiplier=channel_multiplier, human='human' in ckpt)
|
| 96 |
+
checkpoint = torch.load(utils.get_path(ckpt))
|
| 97 |
+
g_ema.load_state_dict(checkpoint["g_ema"], strict=False)
|
| 98 |
+
g_ema.requires_grad_(False)
|
| 99 |
+
g_ema.eval()
|
| 100 |
+
return g_ema
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def drag_gan(
|
| 104 |
+
g_ema,
|
| 105 |
+
latent: torch.Tensor,
|
| 106 |
+
noise,
|
| 107 |
+
F,
|
| 108 |
+
handle_points,
|
| 109 |
+
target_points,
|
| 110 |
+
mask,
|
| 111 |
+
max_iters=1000,
|
| 112 |
+
r1=3,
|
| 113 |
+
r2=12,
|
| 114 |
+
lam=20,
|
| 115 |
+
d=2,
|
| 116 |
+
lr=2e-3,
|
| 117 |
+
):
|
| 118 |
+
handle_points0 = copy.deepcopy(handle_points)
|
| 119 |
+
handle_points = torch.stack(handle_points)
|
| 120 |
+
handle_points0 = torch.stack(handle_points0)
|
| 121 |
+
target_points = torch.stack(target_points)
|
| 122 |
+
|
| 123 |
+
F0 = F.detach().clone()
|
| 124 |
+
device = latent.device
|
| 125 |
+
|
| 126 |
+
latent_trainable = latent[:, :6, :].detach().clone().requires_grad_(True)
|
| 127 |
+
latent_untrainable = latent[:, 6:, :].detach().clone().requires_grad_(False)
|
| 128 |
+
optimizer = torch.optim.Adam([latent_trainable], lr=lr)
|
| 129 |
+
for _ in range(max_iters):
|
| 130 |
+
if torch.allclose(handle_points, target_points, atol=d):
|
| 131 |
+
break
|
| 132 |
+
|
| 133 |
+
optimizer.zero_grad()
|
| 134 |
+
latent = torch.cat([latent_trainable, latent_untrainable], dim=1)
|
| 135 |
+
sample2, F2 = g_ema.generate(latent, noise)
|
| 136 |
+
|
| 137 |
+
# motion supervision
|
| 138 |
+
loss = motion_supervison(handle_points, target_points, F2, r1, device)
|
| 139 |
+
|
| 140 |
+
if mask is not None:
|
| 141 |
+
loss += ((F2 - F0) * (1 - mask)).abs().mean() * lam
|
| 142 |
+
|
| 143 |
+
loss.backward()
|
| 144 |
+
optimizer.step()
|
| 145 |
+
|
| 146 |
+
with torch.no_grad():
|
| 147 |
+
latent = torch.cat([latent_trainable, latent_untrainable], dim=1)
|
| 148 |
+
sample2, F2 = g_ema.generate(latent, noise)
|
| 149 |
+
handle_points = point_tracking(F2, F0, handle_points, handle_points0, r2, device)
|
| 150 |
+
|
| 151 |
+
F = F2.detach().clone()
|
| 152 |
+
# if iter % 1 == 0:
|
| 153 |
+
# print(iter, loss.item(), handle_points, target_points)
|
| 154 |
+
|
| 155 |
+
yield sample2, latent, F2, handle_points
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
def motion_supervison(handle_points, target_points, F2, r1, device):
|
| 159 |
+
loss = 0
|
| 160 |
+
n = len(handle_points)
|
| 161 |
+
for i in range(n):
|
| 162 |
+
target2handle = target_points[i] - handle_points[i]
|
| 163 |
+
d_i = target2handle / (torch.norm(target2handle) + 1e-7)
|
| 164 |
+
if torch.norm(d_i) > torch.norm(target2handle):
|
| 165 |
+
d_i = target2handle
|
| 166 |
+
|
| 167 |
+
mask = utils.create_circular_mask(
|
| 168 |
+
F2.shape[2], F2.shape[3], center=handle_points[i].tolist(), radius=r1
|
| 169 |
+
).to(device)
|
| 170 |
+
|
| 171 |
+
coordinates = torch.nonzero(mask).float() # shape [num_points, 2]
|
| 172 |
+
|
| 173 |
+
# Shift the coordinates in the direction d_i
|
| 174 |
+
shifted_coordinates = coordinates + d_i[None]
|
| 175 |
+
|
| 176 |
+
h, w = F2.shape[2], F2.shape[3]
|
| 177 |
+
|
| 178 |
+
# Extract features in the mask region and compute the loss
|
| 179 |
+
F_qi = F2[:, :, mask] # shape: [C, H*W]
|
| 180 |
+
|
| 181 |
+
# Sample shifted patch from F
|
| 182 |
+
normalized_shifted_coordinates = shifted_coordinates.clone()
|
| 183 |
+
normalized_shifted_coordinates[:, 0] = (
|
| 184 |
+
2.0 * shifted_coordinates[:, 0] / (h - 1)
|
| 185 |
+
) - 1 # for height
|
| 186 |
+
normalized_shifted_coordinates[:, 1] = (
|
| 187 |
+
2.0 * shifted_coordinates[:, 1] / (w - 1)
|
| 188 |
+
) - 1 # for width
|
| 189 |
+
# Add extra dimensions for batch and channels (required by grid_sample)
|
| 190 |
+
normalized_shifted_coordinates = normalized_shifted_coordinates.unsqueeze(
|
| 191 |
+
0
|
| 192 |
+
).unsqueeze(
|
| 193 |
+
0
|
| 194 |
+
) # shape [1, 1, num_points, 2]
|
| 195 |
+
normalized_shifted_coordinates = normalized_shifted_coordinates.flip(
|
| 196 |
+
-1
|
| 197 |
+
) # grid_sample expects [x, y] instead of [y, x]
|
| 198 |
+
normalized_shifted_coordinates = normalized_shifted_coordinates.clamp(-1, 1)
|
| 199 |
+
|
| 200 |
+
# Use grid_sample to interpolate the feature map F at the shifted patch coordinates
|
| 201 |
+
F_qi_plus_di = torch.nn.functional.grid_sample(
|
| 202 |
+
F2, normalized_shifted_coordinates, mode="bilinear", align_corners=True
|
| 203 |
+
)
|
| 204 |
+
# Output has shape [1, C, 1, num_points] so squeeze it
|
| 205 |
+
F_qi_plus_di = F_qi_plus_di.squeeze(2) # shape [1, C, num_points]
|
| 206 |
+
|
| 207 |
+
loss += torch.nn.functional.l1_loss(F_qi.detach(), F_qi_plus_di)
|
| 208 |
+
return loss
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
def point_tracking(
|
| 212 |
+
F: torch.Tensor,
|
| 213 |
+
F0: torch.Tensor,
|
| 214 |
+
handle_points: torch.Tensor,
|
| 215 |
+
handle_points0: torch.Tensor,
|
| 216 |
+
r2: int = 3,
|
| 217 |
+
device: torch.device = torch.device("cuda"),
|
| 218 |
+
) -> torch.Tensor:
|
| 219 |
+
|
| 220 |
+
n = handle_points.shape[0] # Number of handle points
|
| 221 |
+
new_handle_points = torch.zeros_like(handle_points)
|
| 222 |
+
|
| 223 |
+
for i in range(n):
|
| 224 |
+
# Compute the patch around the handle point
|
| 225 |
+
patch = utils.create_square_mask(
|
| 226 |
+
F.shape[2], F.shape[3], center=handle_points[i].tolist(), radius=r2
|
| 227 |
+
).to(device)
|
| 228 |
+
|
| 229 |
+
# Find indices where the patch is True
|
| 230 |
+
patch_coordinates = torch.nonzero(patch) # shape [num_points, 2]
|
| 231 |
+
|
| 232 |
+
# Extract features in the patch
|
| 233 |
+
F_qi = F[:, :, patch_coordinates[:, 0], patch_coordinates[:, 1]]
|
| 234 |
+
# Extract feature of the initial handle point
|
| 235 |
+
f_i = F0[:, :, handle_points0[i][0].long(), handle_points0[i][1].long()]
|
| 236 |
+
|
| 237 |
+
# Compute the L1 distance between the patch features and the initial handle point feature
|
| 238 |
+
distances = torch.norm(F_qi - f_i[:, :, None], p=1, dim=1)
|
| 239 |
+
|
| 240 |
+
# Find the new handle point as the one with minimum distance
|
| 241 |
+
min_index = torch.argmin(distances)
|
| 242 |
+
new_handle_points[i] = patch_coordinates[min_index]
|
| 243 |
+
|
| 244 |
+
return new_handle_points
|
draggan/deprecated/stylegan2/__init__.py
ADDED
|
File without changes
|
draggan/deprecated/stylegan2/inversion.py
ADDED
|
@@ -0,0 +1,209 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch import optim
|
| 6 |
+
from torch.nn import functional as FF
|
| 7 |
+
from torchvision import transforms
|
| 8 |
+
from PIL import Image
|
| 9 |
+
from tqdm import tqdm
|
| 10 |
+
import dataclasses
|
| 11 |
+
|
| 12 |
+
from .lpips import util
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def noise_regularize(noises):
|
| 16 |
+
loss = 0
|
| 17 |
+
|
| 18 |
+
for noise in noises:
|
| 19 |
+
size = noise.shape[2]
|
| 20 |
+
|
| 21 |
+
while True:
|
| 22 |
+
loss = (
|
| 23 |
+
loss
|
| 24 |
+
+ (noise * torch.roll(noise, shifts=1, dims=3)).mean().pow(2)
|
| 25 |
+
+ (noise * torch.roll(noise, shifts=1, dims=2)).mean().pow(2)
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
if size <= 8:
|
| 29 |
+
break
|
| 30 |
+
|
| 31 |
+
noise = noise.reshape([-1, 1, size // 2, 2, size // 2, 2])
|
| 32 |
+
noise = noise.mean([3, 5])
|
| 33 |
+
size //= 2
|
| 34 |
+
|
| 35 |
+
return loss
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def noise_normalize_(noises):
|
| 39 |
+
for noise in noises:
|
| 40 |
+
mean = noise.mean()
|
| 41 |
+
std = noise.std()
|
| 42 |
+
|
| 43 |
+
noise.data.add_(-mean).div_(std)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def get_lr(t, initial_lr, rampdown=0.25, rampup=0.05):
|
| 47 |
+
lr_ramp = min(1, (1 - t) / rampdown)
|
| 48 |
+
lr_ramp = 0.5 - 0.5 * math.cos(lr_ramp * math.pi)
|
| 49 |
+
lr_ramp = lr_ramp * min(1, t / rampup)
|
| 50 |
+
|
| 51 |
+
return initial_lr * lr_ramp
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def latent_noise(latent, strength):
|
| 55 |
+
noise = torch.randn_like(latent) * strength
|
| 56 |
+
|
| 57 |
+
return latent + noise
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def make_image(tensor):
|
| 61 |
+
return (
|
| 62 |
+
tensor.detach()
|
| 63 |
+
.clamp_(min=-1, max=1)
|
| 64 |
+
.add(1)
|
| 65 |
+
.div_(2)
|
| 66 |
+
.mul(255)
|
| 67 |
+
.type(torch.uint8)
|
| 68 |
+
.permute(0, 2, 3, 1)
|
| 69 |
+
.to("cpu")
|
| 70 |
+
.numpy()
|
| 71 |
+
)
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
@dataclasses.dataclass
|
| 75 |
+
class InverseConfig:
|
| 76 |
+
lr_warmup = 0.05
|
| 77 |
+
lr_decay = 0.25
|
| 78 |
+
lr = 0.1
|
| 79 |
+
noise = 0.05
|
| 80 |
+
noise_decay = 0.75
|
| 81 |
+
step = 1000
|
| 82 |
+
noise_regularize = 1e5
|
| 83 |
+
mse = 0
|
| 84 |
+
w_plus = False,
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def inverse_image(
|
| 88 |
+
g_ema,
|
| 89 |
+
image,
|
| 90 |
+
image_size=256,
|
| 91 |
+
config=InverseConfig()
|
| 92 |
+
):
|
| 93 |
+
device = "cuda"
|
| 94 |
+
args = config
|
| 95 |
+
|
| 96 |
+
n_mean_latent = 10000
|
| 97 |
+
|
| 98 |
+
resize = min(image_size, 256)
|
| 99 |
+
|
| 100 |
+
transform = transforms.Compose(
|
| 101 |
+
[
|
| 102 |
+
transforms.Resize(resize),
|
| 103 |
+
transforms.CenterCrop(resize),
|
| 104 |
+
transforms.ToTensor(),
|
| 105 |
+
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]),
|
| 106 |
+
]
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
imgs = []
|
| 110 |
+
img = transform(image)
|
| 111 |
+
imgs.append(img)
|
| 112 |
+
|
| 113 |
+
imgs = torch.stack(imgs, 0).to(device)
|
| 114 |
+
|
| 115 |
+
with torch.no_grad():
|
| 116 |
+
noise_sample = torch.randn(n_mean_latent, 512, device=device)
|
| 117 |
+
latent_out = g_ema.style(noise_sample)
|
| 118 |
+
|
| 119 |
+
latent_mean = latent_out.mean(0)
|
| 120 |
+
latent_std = ((latent_out - latent_mean).pow(2).sum() / n_mean_latent) ** 0.5
|
| 121 |
+
|
| 122 |
+
percept = util.PerceptualLoss(
|
| 123 |
+
model="net-lin", net="vgg", use_gpu=device.startswith("cuda")
|
| 124 |
+
)
|
| 125 |
+
|
| 126 |
+
noises_single = g_ema.make_noise()
|
| 127 |
+
noises = []
|
| 128 |
+
for noise in noises_single:
|
| 129 |
+
noises.append(noise.repeat(imgs.shape[0], 1, 1, 1).normal_())
|
| 130 |
+
|
| 131 |
+
latent_in = latent_mean.detach().clone().unsqueeze(0).repeat(imgs.shape[0], 1)
|
| 132 |
+
|
| 133 |
+
if args.w_plus:
|
| 134 |
+
latent_in = latent_in.unsqueeze(1).repeat(1, g_ema.n_latent, 1)
|
| 135 |
+
|
| 136 |
+
latent_in.requires_grad = True
|
| 137 |
+
|
| 138 |
+
for noise in noises:
|
| 139 |
+
noise.requires_grad = True
|
| 140 |
+
|
| 141 |
+
optimizer = optim.Adam([latent_in] + noises, lr=args.lr)
|
| 142 |
+
|
| 143 |
+
pbar = tqdm(range(args.step))
|
| 144 |
+
latent_path = []
|
| 145 |
+
|
| 146 |
+
for i in pbar:
|
| 147 |
+
t = i / args.step
|
| 148 |
+
lr = get_lr(t, args.lr)
|
| 149 |
+
optimizer.param_groups[0]["lr"] = lr
|
| 150 |
+
noise_strength = latent_std * args.noise * max(0, 1 - t / args.noise_decay) ** 2
|
| 151 |
+
latent_n = latent_noise(latent_in, noise_strength.item())
|
| 152 |
+
|
| 153 |
+
latent, noise = g_ema.prepare([latent_n], input_is_latent=True, noise=noises)
|
| 154 |
+
img_gen, F = g_ema.generate(latent, noise)
|
| 155 |
+
|
| 156 |
+
batch, channel, height, width = img_gen.shape
|
| 157 |
+
|
| 158 |
+
if height > 256:
|
| 159 |
+
factor = height // 256
|
| 160 |
+
|
| 161 |
+
img_gen = img_gen.reshape(
|
| 162 |
+
batch, channel, height // factor, factor, width // factor, factor
|
| 163 |
+
)
|
| 164 |
+
img_gen = img_gen.mean([3, 5])
|
| 165 |
+
|
| 166 |
+
p_loss = percept(img_gen, imgs).sum()
|
| 167 |
+
n_loss = noise_regularize(noises)
|
| 168 |
+
mse_loss = FF.mse_loss(img_gen, imgs)
|
| 169 |
+
|
| 170 |
+
loss = p_loss + args.noise_regularize * n_loss + args.mse * mse_loss
|
| 171 |
+
|
| 172 |
+
optimizer.zero_grad()
|
| 173 |
+
loss.backward()
|
| 174 |
+
optimizer.step()
|
| 175 |
+
|
| 176 |
+
noise_normalize_(noises)
|
| 177 |
+
|
| 178 |
+
if (i + 1) % 100 == 0:
|
| 179 |
+
latent_path.append(latent_in.detach().clone())
|
| 180 |
+
|
| 181 |
+
pbar.set_description(
|
| 182 |
+
(
|
| 183 |
+
f"perceptual: {p_loss.item():.4f}; noise regularize: {n_loss.item():.4f};"
|
| 184 |
+
f" mse: {mse_loss.item():.4f}; lr: {lr:.4f}"
|
| 185 |
+
)
|
| 186 |
+
)
|
| 187 |
+
|
| 188 |
+
latent, noise = g_ema.prepare([latent_path[-1]], input_is_latent=True, noise=noises)
|
| 189 |
+
img_gen, F = g_ema.generate(latent, noise)
|
| 190 |
+
|
| 191 |
+
img_ar = make_image(img_gen)
|
| 192 |
+
|
| 193 |
+
i = 0
|
| 194 |
+
|
| 195 |
+
noise_single = []
|
| 196 |
+
for noise in noises:
|
| 197 |
+
noise_single.append(noise[i: i + 1])
|
| 198 |
+
|
| 199 |
+
result = {
|
| 200 |
+
"latent": latent,
|
| 201 |
+
"noise": noise_single,
|
| 202 |
+
'F': F,
|
| 203 |
+
"sample": img_gen,
|
| 204 |
+
}
|
| 205 |
+
|
| 206 |
+
pil_img = Image.fromarray(img_ar[i])
|
| 207 |
+
pil_img.save('project.png')
|
| 208 |
+
|
| 209 |
+
return result
|
draggan/deprecated/stylegan2/lpips/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from __future__ import absolute_import
|
| 3 |
+
from __future__ import division
|
| 4 |
+
from __future__ import print_function
|
| 5 |
+
|
draggan/deprecated/stylegan2/lpips/base_model.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch
|
| 4 |
+
from torch.autograd import Variable
|
| 5 |
+
from pdb import set_trace as st
|
| 6 |
+
from IPython import embed
|
| 7 |
+
|
| 8 |
+
class BaseModel():
|
| 9 |
+
def __init__(self):
|
| 10 |
+
pass;
|
| 11 |
+
|
| 12 |
+
def name(self):
|
| 13 |
+
return 'BaseModel'
|
| 14 |
+
|
| 15 |
+
def initialize(self, use_gpu=True, gpu_ids=[0]):
|
| 16 |
+
self.use_gpu = use_gpu
|
| 17 |
+
self.gpu_ids = gpu_ids
|
| 18 |
+
|
| 19 |
+
def forward(self):
|
| 20 |
+
pass
|
| 21 |
+
|
| 22 |
+
def get_image_paths(self):
|
| 23 |
+
pass
|
| 24 |
+
|
| 25 |
+
def optimize_parameters(self):
|
| 26 |
+
pass
|
| 27 |
+
|
| 28 |
+
def get_current_visuals(self):
|
| 29 |
+
return self.input
|
| 30 |
+
|
| 31 |
+
def get_current_errors(self):
|
| 32 |
+
return {}
|
| 33 |
+
|
| 34 |
+
def save(self, label):
|
| 35 |
+
pass
|
| 36 |
+
|
| 37 |
+
# helper saving function that can be used by subclasses
|
| 38 |
+
def save_network(self, network, path, network_label, epoch_label):
|
| 39 |
+
save_filename = '%s_net_%s.pth' % (epoch_label, network_label)
|
| 40 |
+
save_path = os.path.join(path, save_filename)
|
| 41 |
+
torch.save(network.state_dict(), save_path)
|
| 42 |
+
|
| 43 |
+
# helper loading function that can be used by subclasses
|
| 44 |
+
def load_network(self, network, network_label, epoch_label):
|
| 45 |
+
save_filename = '%s_net_%s.pth' % (epoch_label, network_label)
|
| 46 |
+
save_path = os.path.join(self.save_dir, save_filename)
|
| 47 |
+
print('Loading network from %s'%save_path)
|
| 48 |
+
network.load_state_dict(torch.load(save_path))
|
| 49 |
+
|
| 50 |
+
def update_learning_rate():
|
| 51 |
+
pass
|
| 52 |
+
|
| 53 |
+
def get_image_paths(self):
|
| 54 |
+
return self.image_paths
|
| 55 |
+
|
| 56 |
+
def save_done(self, flag=False):
|
| 57 |
+
np.save(os.path.join(self.save_dir, 'done_flag'),flag)
|
| 58 |
+
np.savetxt(os.path.join(self.save_dir, 'done_flag'),[flag,],fmt='%i')
|
draggan/deprecated/stylegan2/lpips/dist_model.py
ADDED
|
@@ -0,0 +1,314 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from __future__ import absolute_import
|
| 3 |
+
|
| 4 |
+
import sys
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch
|
| 7 |
+
from torch import nn
|
| 8 |
+
import os
|
| 9 |
+
from collections import OrderedDict
|
| 10 |
+
from torch.autograd import Variable
|
| 11 |
+
import itertools
|
| 12 |
+
from .base_model import BaseModel
|
| 13 |
+
from scipy.ndimage import zoom
|
| 14 |
+
import fractions
|
| 15 |
+
import functools
|
| 16 |
+
import skimage.transform
|
| 17 |
+
from tqdm import tqdm
|
| 18 |
+
import urllib
|
| 19 |
+
|
| 20 |
+
from IPython import embed
|
| 21 |
+
|
| 22 |
+
from . import networks_basic as networks
|
| 23 |
+
from . import util
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class DownloadProgressBar(tqdm):
|
| 27 |
+
def update_to(self, b=1, bsize=1, tsize=None):
|
| 28 |
+
if tsize is not None:
|
| 29 |
+
self.total = tsize
|
| 30 |
+
self.update(b * bsize - self.n)
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def get_path(base_path):
|
| 34 |
+
BASE_DIR = os.path.join('checkpoints')
|
| 35 |
+
|
| 36 |
+
save_path = os.path.join(BASE_DIR, base_path)
|
| 37 |
+
if not os.path.exists(save_path):
|
| 38 |
+
url = f"https://huggingface.co/aaronb/StyleGAN2/resolve/main/{base_path}"
|
| 39 |
+
print(f'{base_path} not found')
|
| 40 |
+
print('Try to download from huggingface: ', url)
|
| 41 |
+
os.makedirs(os.path.dirname(save_path), exist_ok=True)
|
| 42 |
+
download_url(url, save_path)
|
| 43 |
+
print('Downloaded to ', save_path)
|
| 44 |
+
return save_path
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def download_url(url, output_path):
|
| 48 |
+
with DownloadProgressBar(unit='B', unit_scale=True,
|
| 49 |
+
miniters=1, desc=url.split('/')[-1]) as t:
|
| 50 |
+
urllib.request.urlretrieve(url, filename=output_path, reporthook=t.update_to)
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
class DistModel(BaseModel):
|
| 54 |
+
def name(self):
|
| 55 |
+
return self.model_name
|
| 56 |
+
|
| 57 |
+
def initialize(self, model='net-lin', net='alex', colorspace='Lab', pnet_rand=False, pnet_tune=False, model_path=None,
|
| 58 |
+
use_gpu=True, printNet=False, spatial=False,
|
| 59 |
+
is_train=False, lr=.0001, beta1=0.5, version='0.1', gpu_ids=[0]):
|
| 60 |
+
'''
|
| 61 |
+
INPUTS
|
| 62 |
+
model - ['net-lin'] for linearly calibrated network
|
| 63 |
+
['net'] for off-the-shelf network
|
| 64 |
+
['L2'] for L2 distance in Lab colorspace
|
| 65 |
+
['SSIM'] for ssim in RGB colorspace
|
| 66 |
+
net - ['squeeze','alex','vgg']
|
| 67 |
+
model_path - if None, will look in weights/[NET_NAME].pth
|
| 68 |
+
colorspace - ['Lab','RGB'] colorspace to use for L2 and SSIM
|
| 69 |
+
use_gpu - bool - whether or not to use a GPU
|
| 70 |
+
printNet - bool - whether or not to print network architecture out
|
| 71 |
+
spatial - bool - whether to output an array containing varying distances across spatial dimensions
|
| 72 |
+
spatial_shape - if given, output spatial shape. if None then spatial shape is determined automatically via spatial_factor (see below).
|
| 73 |
+
spatial_factor - if given, specifies upsampling factor relative to the largest spatial extent of a convolutional layer. if None then resized to size of input images.
|
| 74 |
+
spatial_order - spline order of filter for upsampling in spatial mode, by default 1 (bilinear).
|
| 75 |
+
is_train - bool - [True] for training mode
|
| 76 |
+
lr - float - initial learning rate
|
| 77 |
+
beta1 - float - initial momentum term for adam
|
| 78 |
+
version - 0.1 for latest, 0.0 was original (with a bug)
|
| 79 |
+
gpu_ids - int array - [0] by default, gpus to use
|
| 80 |
+
'''
|
| 81 |
+
BaseModel.initialize(self, use_gpu=use_gpu, gpu_ids=gpu_ids)
|
| 82 |
+
|
| 83 |
+
self.model = model
|
| 84 |
+
self.net = net
|
| 85 |
+
self.is_train = is_train
|
| 86 |
+
self.spatial = spatial
|
| 87 |
+
self.gpu_ids = gpu_ids
|
| 88 |
+
self.model_name = '%s [%s]' % (model, net)
|
| 89 |
+
|
| 90 |
+
if(self.model == 'net-lin'): # pretrained net + linear layer
|
| 91 |
+
self.net = networks.PNetLin(pnet_rand=pnet_rand, pnet_tune=pnet_tune, pnet_type=net,
|
| 92 |
+
use_dropout=True, spatial=spatial, version=version, lpips=True)
|
| 93 |
+
kw = {}
|
| 94 |
+
if not use_gpu:
|
| 95 |
+
kw['map_location'] = 'cpu'
|
| 96 |
+
if(model_path is None):
|
| 97 |
+
model_path = get_path('weights/v%s/%s.pth' % (version, net))
|
| 98 |
+
|
| 99 |
+
if(not is_train):
|
| 100 |
+
print('Loading model from: %s' % model_path)
|
| 101 |
+
self.net.load_state_dict(torch.load(model_path, **kw), strict=False)
|
| 102 |
+
|
| 103 |
+
elif(self.model == 'net'): # pretrained network
|
| 104 |
+
self.net = networks.PNetLin(pnet_rand=pnet_rand, pnet_type=net, lpips=False)
|
| 105 |
+
elif(self.model in ['L2', 'l2']):
|
| 106 |
+
self.net = networks.L2(use_gpu=use_gpu, colorspace=colorspace) # not really a network, only for testing
|
| 107 |
+
self.model_name = 'L2'
|
| 108 |
+
elif(self.model in ['DSSIM', 'dssim', 'SSIM', 'ssim']):
|
| 109 |
+
self.net = networks.DSSIM(use_gpu=use_gpu, colorspace=colorspace)
|
| 110 |
+
self.model_name = 'SSIM'
|
| 111 |
+
else:
|
| 112 |
+
raise ValueError("Model [%s] not recognized." % self.model)
|
| 113 |
+
|
| 114 |
+
self.parameters = list(self.net.parameters())
|
| 115 |
+
|
| 116 |
+
if self.is_train: # training mode
|
| 117 |
+
# extra network on top to go from distances (d0,d1) => predicted human judgment (h*)
|
| 118 |
+
self.rankLoss = networks.BCERankingLoss()
|
| 119 |
+
self.parameters += list(self.rankLoss.net.parameters())
|
| 120 |
+
self.lr = lr
|
| 121 |
+
self.old_lr = lr
|
| 122 |
+
self.optimizer_net = torch.optim.Adam(self.parameters, lr=lr, betas=(beta1, 0.999))
|
| 123 |
+
else: # test mode
|
| 124 |
+
self.net.eval()
|
| 125 |
+
|
| 126 |
+
if(use_gpu):
|
| 127 |
+
self.net.to(gpu_ids[0])
|
| 128 |
+
self.net = torch.nn.DataParallel(self.net, device_ids=gpu_ids)
|
| 129 |
+
if(self.is_train):
|
| 130 |
+
self.rankLoss = self.rankLoss.to(device=gpu_ids[0]) # just put this on GPU0
|
| 131 |
+
|
| 132 |
+
if(printNet):
|
| 133 |
+
print('---------- Networks initialized -------------')
|
| 134 |
+
networks.print_network(self.net)
|
| 135 |
+
print('-----------------------------------------------')
|
| 136 |
+
|
| 137 |
+
def forward(self, in0, in1, retPerLayer=False):
|
| 138 |
+
''' Function computes the distance between image patches in0 and in1
|
| 139 |
+
INPUTS
|
| 140 |
+
in0, in1 - torch.Tensor object of shape Nx3xXxY - image patch scaled to [-1,1]
|
| 141 |
+
OUTPUT
|
| 142 |
+
computed distances between in0 and in1
|
| 143 |
+
'''
|
| 144 |
+
|
| 145 |
+
return self.net.forward(in0, in1, retPerLayer=retPerLayer)
|
| 146 |
+
|
| 147 |
+
# ***** TRAINING FUNCTIONS *****
|
| 148 |
+
def optimize_parameters(self):
|
| 149 |
+
self.forward_train()
|
| 150 |
+
self.optimizer_net.zero_grad()
|
| 151 |
+
self.backward_train()
|
| 152 |
+
self.optimizer_net.step()
|
| 153 |
+
self.clamp_weights()
|
| 154 |
+
|
| 155 |
+
def clamp_weights(self):
|
| 156 |
+
for module in self.net.modules():
|
| 157 |
+
if(hasattr(module, 'weight') and module.kernel_size == (1, 1)):
|
| 158 |
+
module.weight.data = torch.clamp(module.weight.data, min=0)
|
| 159 |
+
|
| 160 |
+
def set_input(self, data):
|
| 161 |
+
self.input_ref = data['ref']
|
| 162 |
+
self.input_p0 = data['p0']
|
| 163 |
+
self.input_p1 = data['p1']
|
| 164 |
+
self.input_judge = data['judge']
|
| 165 |
+
|
| 166 |
+
if(self.use_gpu):
|
| 167 |
+
self.input_ref = self.input_ref.to(device=self.gpu_ids[0])
|
| 168 |
+
self.input_p0 = self.input_p0.to(device=self.gpu_ids[0])
|
| 169 |
+
self.input_p1 = self.input_p1.to(device=self.gpu_ids[0])
|
| 170 |
+
self.input_judge = self.input_judge.to(device=self.gpu_ids[0])
|
| 171 |
+
|
| 172 |
+
self.var_ref = Variable(self.input_ref, requires_grad=True)
|
| 173 |
+
self.var_p0 = Variable(self.input_p0, requires_grad=True)
|
| 174 |
+
self.var_p1 = Variable(self.input_p1, requires_grad=True)
|
| 175 |
+
|
| 176 |
+
def forward_train(self): # run forward pass
|
| 177 |
+
# print(self.net.module.scaling_layer.shift)
|
| 178 |
+
# print(torch.norm(self.net.module.net.slice1[0].weight).item(), torch.norm(self.net.module.lin0.model[1].weight).item())
|
| 179 |
+
|
| 180 |
+
self.d0 = self.forward(self.var_ref, self.var_p0)
|
| 181 |
+
self.d1 = self.forward(self.var_ref, self.var_p1)
|
| 182 |
+
self.acc_r = self.compute_accuracy(self.d0, self.d1, self.input_judge)
|
| 183 |
+
|
| 184 |
+
self.var_judge = Variable(1. * self.input_judge).view(self.d0.size())
|
| 185 |
+
|
| 186 |
+
self.loss_total = self.rankLoss.forward(self.d0, self.d1, self.var_judge * 2. - 1.)
|
| 187 |
+
|
| 188 |
+
return self.loss_total
|
| 189 |
+
|
| 190 |
+
def backward_train(self):
|
| 191 |
+
torch.mean(self.loss_total).backward()
|
| 192 |
+
|
| 193 |
+
def compute_accuracy(self, d0, d1, judge):
|
| 194 |
+
''' d0, d1 are Variables, judge is a Tensor '''
|
| 195 |
+
d1_lt_d0 = (d1 < d0).cpu().data.numpy().flatten()
|
| 196 |
+
judge_per = judge.cpu().numpy().flatten()
|
| 197 |
+
return d1_lt_d0 * judge_per + (1 - d1_lt_d0) * (1 - judge_per)
|
| 198 |
+
|
| 199 |
+
def get_current_errors(self):
|
| 200 |
+
retDict = OrderedDict([('loss_total', self.loss_total.data.cpu().numpy()),
|
| 201 |
+
('acc_r', self.acc_r)])
|
| 202 |
+
|
| 203 |
+
for key in retDict.keys():
|
| 204 |
+
retDict[key] = np.mean(retDict[key])
|
| 205 |
+
|
| 206 |
+
return retDict
|
| 207 |
+
|
| 208 |
+
def get_current_visuals(self):
|
| 209 |
+
zoom_factor = 256 / self.var_ref.data.size()[2]
|
| 210 |
+
|
| 211 |
+
ref_img = util.tensor2im(self.var_ref.data)
|
| 212 |
+
p0_img = util.tensor2im(self.var_p0.data)
|
| 213 |
+
p1_img = util.tensor2im(self.var_p1.data)
|
| 214 |
+
|
| 215 |
+
ref_img_vis = zoom(ref_img, [zoom_factor, zoom_factor, 1], order=0)
|
| 216 |
+
p0_img_vis = zoom(p0_img, [zoom_factor, zoom_factor, 1], order=0)
|
| 217 |
+
p1_img_vis = zoom(p1_img, [zoom_factor, zoom_factor, 1], order=0)
|
| 218 |
+
|
| 219 |
+
return OrderedDict([('ref', ref_img_vis),
|
| 220 |
+
('p0', p0_img_vis),
|
| 221 |
+
('p1', p1_img_vis)])
|
| 222 |
+
|
| 223 |
+
def save(self, path, label):
|
| 224 |
+
if(self.use_gpu):
|
| 225 |
+
self.save_network(self.net.module, path, '', label)
|
| 226 |
+
else:
|
| 227 |
+
self.save_network(self.net, path, '', label)
|
| 228 |
+
self.save_network(self.rankLoss.net, path, 'rank', label)
|
| 229 |
+
|
| 230 |
+
def update_learning_rate(self, nepoch_decay):
|
| 231 |
+
lrd = self.lr / nepoch_decay
|
| 232 |
+
lr = self.old_lr - lrd
|
| 233 |
+
|
| 234 |
+
for param_group in self.optimizer_net.param_groups:
|
| 235 |
+
param_group['lr'] = lr
|
| 236 |
+
|
| 237 |
+
print('update lr [%s] decay: %f -> %f' % (type, self.old_lr, lr))
|
| 238 |
+
self.old_lr = lr
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
def score_2afc_dataset(data_loader, func, name=''):
|
| 242 |
+
''' Function computes Two Alternative Forced Choice (2AFC) score using
|
| 243 |
+
distance function 'func' in dataset 'data_loader'
|
| 244 |
+
INPUTS
|
| 245 |
+
data_loader - CustomDatasetDataLoader object - contains a TwoAFCDataset inside
|
| 246 |
+
func - callable distance function - calling d=func(in0,in1) should take 2
|
| 247 |
+
pytorch tensors with shape Nx3xXxY, and return numpy array of length N
|
| 248 |
+
OUTPUTS
|
| 249 |
+
[0] - 2AFC score in [0,1], fraction of time func agrees with human evaluators
|
| 250 |
+
[1] - dictionary with following elements
|
| 251 |
+
d0s,d1s - N arrays containing distances between reference patch to perturbed patches
|
| 252 |
+
gts - N array in [0,1], preferred patch selected by human evaluators
|
| 253 |
+
(closer to "0" for left patch p0, "1" for right patch p1,
|
| 254 |
+
"0.6" means 60pct people preferred right patch, 40pct preferred left)
|
| 255 |
+
scores - N array in [0,1], corresponding to what percentage function agreed with humans
|
| 256 |
+
CONSTS
|
| 257 |
+
N - number of test triplets in data_loader
|
| 258 |
+
'''
|
| 259 |
+
|
| 260 |
+
d0s = []
|
| 261 |
+
d1s = []
|
| 262 |
+
gts = []
|
| 263 |
+
|
| 264 |
+
for data in tqdm(data_loader.load_data(), desc=name):
|
| 265 |
+
d0s += func(data['ref'], data['p0']).data.cpu().numpy().flatten().tolist()
|
| 266 |
+
d1s += func(data['ref'], data['p1']).data.cpu().numpy().flatten().tolist()
|
| 267 |
+
gts += data['judge'].cpu().numpy().flatten().tolist()
|
| 268 |
+
|
| 269 |
+
d0s = np.array(d0s)
|
| 270 |
+
d1s = np.array(d1s)
|
| 271 |
+
gts = np.array(gts)
|
| 272 |
+
scores = (d0s < d1s) * (1. - gts) + (d1s < d0s) * gts + (d1s == d0s) * .5
|
| 273 |
+
|
| 274 |
+
return(np.mean(scores), dict(d0s=d0s, d1s=d1s, gts=gts, scores=scores))
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
def score_jnd_dataset(data_loader, func, name=''):
|
| 278 |
+
''' Function computes JND score using distance function 'func' in dataset 'data_loader'
|
| 279 |
+
INPUTS
|
| 280 |
+
data_loader - CustomDatasetDataLoader object - contains a JNDDataset inside
|
| 281 |
+
func - callable distance function - calling d=func(in0,in1) should take 2
|
| 282 |
+
pytorch tensors with shape Nx3xXxY, and return pytorch array of length N
|
| 283 |
+
OUTPUTS
|
| 284 |
+
[0] - JND score in [0,1], mAP score (area under precision-recall curve)
|
| 285 |
+
[1] - dictionary with following elements
|
| 286 |
+
ds - N array containing distances between two patches shown to human evaluator
|
| 287 |
+
sames - N array containing fraction of people who thought the two patches were identical
|
| 288 |
+
CONSTS
|
| 289 |
+
N - number of test triplets in data_loader
|
| 290 |
+
'''
|
| 291 |
+
|
| 292 |
+
ds = []
|
| 293 |
+
gts = []
|
| 294 |
+
|
| 295 |
+
for data in tqdm(data_loader.load_data(), desc=name):
|
| 296 |
+
ds += func(data['p0'], data['p1']).data.cpu().numpy().tolist()
|
| 297 |
+
gts += data['same'].cpu().numpy().flatten().tolist()
|
| 298 |
+
|
| 299 |
+
sames = np.array(gts)
|
| 300 |
+
ds = np.array(ds)
|
| 301 |
+
|
| 302 |
+
sorted_inds = np.argsort(ds)
|
| 303 |
+
ds_sorted = ds[sorted_inds]
|
| 304 |
+
sames_sorted = sames[sorted_inds]
|
| 305 |
+
|
| 306 |
+
TPs = np.cumsum(sames_sorted)
|
| 307 |
+
FPs = np.cumsum(1 - sames_sorted)
|
| 308 |
+
FNs = np.sum(sames_sorted) - TPs
|
| 309 |
+
|
| 310 |
+
precs = TPs / (TPs + FPs)
|
| 311 |
+
recs = TPs / (TPs + FNs)
|
| 312 |
+
score = util.voc_ap(recs, precs)
|
| 313 |
+
|
| 314 |
+
return(score, dict(ds=ds, sames=sames))
|
draggan/deprecated/stylegan2/lpips/networks_basic.py
ADDED
|
@@ -0,0 +1,188 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from __future__ import absolute_import
|
| 3 |
+
|
| 4 |
+
import sys
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import torch.nn.init as init
|
| 8 |
+
from torch.autograd import Variable
|
| 9 |
+
import numpy as np
|
| 10 |
+
from pdb import set_trace as st
|
| 11 |
+
from skimage import color
|
| 12 |
+
from IPython import embed
|
| 13 |
+
from . import pretrained_networks as pn
|
| 14 |
+
|
| 15 |
+
from . import util
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def spatial_average(in_tens, keepdim=True):
|
| 19 |
+
return in_tens.mean([2,3],keepdim=keepdim)
|
| 20 |
+
|
| 21 |
+
def upsample(in_tens, out_H=64): # assumes scale factor is same for H and W
|
| 22 |
+
in_H = in_tens.shape[2]
|
| 23 |
+
scale_factor = 1.*out_H/in_H
|
| 24 |
+
|
| 25 |
+
return nn.Upsample(scale_factor=scale_factor, mode='bilinear', align_corners=False)(in_tens)
|
| 26 |
+
|
| 27 |
+
# Learned perceptual metric
|
| 28 |
+
class PNetLin(nn.Module):
|
| 29 |
+
def __init__(self, pnet_type='vgg', pnet_rand=False, pnet_tune=False, use_dropout=True, spatial=False, version='0.1', lpips=True):
|
| 30 |
+
super(PNetLin, self).__init__()
|
| 31 |
+
|
| 32 |
+
self.pnet_type = pnet_type
|
| 33 |
+
self.pnet_tune = pnet_tune
|
| 34 |
+
self.pnet_rand = pnet_rand
|
| 35 |
+
self.spatial = spatial
|
| 36 |
+
self.lpips = lpips
|
| 37 |
+
self.version = version
|
| 38 |
+
self.scaling_layer = ScalingLayer()
|
| 39 |
+
|
| 40 |
+
if(self.pnet_type in ['vgg','vgg16']):
|
| 41 |
+
net_type = pn.vgg16
|
| 42 |
+
self.chns = [64,128,256,512,512]
|
| 43 |
+
elif(self.pnet_type=='alex'):
|
| 44 |
+
net_type = pn.alexnet
|
| 45 |
+
self.chns = [64,192,384,256,256]
|
| 46 |
+
elif(self.pnet_type=='squeeze'):
|
| 47 |
+
net_type = pn.squeezenet
|
| 48 |
+
self.chns = [64,128,256,384,384,512,512]
|
| 49 |
+
self.L = len(self.chns)
|
| 50 |
+
|
| 51 |
+
self.net = net_type(pretrained=not self.pnet_rand, requires_grad=self.pnet_tune)
|
| 52 |
+
|
| 53 |
+
if(lpips):
|
| 54 |
+
self.lin0 = NetLinLayer(self.chns[0], use_dropout=use_dropout)
|
| 55 |
+
self.lin1 = NetLinLayer(self.chns[1], use_dropout=use_dropout)
|
| 56 |
+
self.lin2 = NetLinLayer(self.chns[2], use_dropout=use_dropout)
|
| 57 |
+
self.lin3 = NetLinLayer(self.chns[3], use_dropout=use_dropout)
|
| 58 |
+
self.lin4 = NetLinLayer(self.chns[4], use_dropout=use_dropout)
|
| 59 |
+
self.lins = [self.lin0,self.lin1,self.lin2,self.lin3,self.lin4]
|
| 60 |
+
if(self.pnet_type=='squeeze'): # 7 layers for squeezenet
|
| 61 |
+
self.lin5 = NetLinLayer(self.chns[5], use_dropout=use_dropout)
|
| 62 |
+
self.lin6 = NetLinLayer(self.chns[6], use_dropout=use_dropout)
|
| 63 |
+
self.lins+=[self.lin5,self.lin6]
|
| 64 |
+
|
| 65 |
+
def forward(self, in0, in1, retPerLayer=False):
|
| 66 |
+
# v0.0 - original release had a bug, where input was not scaled
|
| 67 |
+
in0_input, in1_input = (self.scaling_layer(in0), self.scaling_layer(in1)) if self.version=='0.1' else (in0, in1)
|
| 68 |
+
outs0, outs1 = self.net.forward(in0_input), self.net.forward(in1_input)
|
| 69 |
+
feats0, feats1, diffs = {}, {}, {}
|
| 70 |
+
|
| 71 |
+
for kk in range(self.L):
|
| 72 |
+
feats0[kk], feats1[kk] = util.normalize_tensor(outs0[kk]), util.normalize_tensor(outs1[kk])
|
| 73 |
+
diffs[kk] = (feats0[kk]-feats1[kk])**2
|
| 74 |
+
|
| 75 |
+
if(self.lpips):
|
| 76 |
+
if(self.spatial):
|
| 77 |
+
res = [upsample(self.lins[kk].model(diffs[kk]), out_H=in0.shape[2]) for kk in range(self.L)]
|
| 78 |
+
else:
|
| 79 |
+
res = [spatial_average(self.lins[kk].model(diffs[kk]), keepdim=True) for kk in range(self.L)]
|
| 80 |
+
else:
|
| 81 |
+
if(self.spatial):
|
| 82 |
+
res = [upsample(diffs[kk].sum(dim=1,keepdim=True), out_H=in0.shape[2]) for kk in range(self.L)]
|
| 83 |
+
else:
|
| 84 |
+
res = [spatial_average(diffs[kk].sum(dim=1,keepdim=True), keepdim=True) for kk in range(self.L)]
|
| 85 |
+
|
| 86 |
+
val = res[0]
|
| 87 |
+
for l in range(1,self.L):
|
| 88 |
+
val += res[l]
|
| 89 |
+
|
| 90 |
+
if(retPerLayer):
|
| 91 |
+
return (val, res)
|
| 92 |
+
else:
|
| 93 |
+
return val
|
| 94 |
+
|
| 95 |
+
class ScalingLayer(nn.Module):
|
| 96 |
+
def __init__(self):
|
| 97 |
+
super(ScalingLayer, self).__init__()
|
| 98 |
+
self.register_buffer('shift', torch.Tensor([-.030,-.088,-.188])[None,:,None,None])
|
| 99 |
+
self.register_buffer('scale', torch.Tensor([.458,.448,.450])[None,:,None,None])
|
| 100 |
+
|
| 101 |
+
def forward(self, inp):
|
| 102 |
+
return (inp - self.shift) / self.scale
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
class NetLinLayer(nn.Module):
|
| 106 |
+
''' A single linear layer which does a 1x1 conv '''
|
| 107 |
+
def __init__(self, chn_in, chn_out=1, use_dropout=False):
|
| 108 |
+
super(NetLinLayer, self).__init__()
|
| 109 |
+
|
| 110 |
+
layers = [nn.Dropout(),] if(use_dropout) else []
|
| 111 |
+
layers += [nn.Conv2d(chn_in, chn_out, 1, stride=1, padding=0, bias=False),]
|
| 112 |
+
self.model = nn.Sequential(*layers)
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
class Dist2LogitLayer(nn.Module):
|
| 116 |
+
''' takes 2 distances, puts through fc layers, spits out value between [0,1] (if use_sigmoid is True) '''
|
| 117 |
+
def __init__(self, chn_mid=32, use_sigmoid=True):
|
| 118 |
+
super(Dist2LogitLayer, self).__init__()
|
| 119 |
+
|
| 120 |
+
layers = [nn.Conv2d(5, chn_mid, 1, stride=1, padding=0, bias=True),]
|
| 121 |
+
layers += [nn.LeakyReLU(0.2,True),]
|
| 122 |
+
layers += [nn.Conv2d(chn_mid, chn_mid, 1, stride=1, padding=0, bias=True),]
|
| 123 |
+
layers += [nn.LeakyReLU(0.2,True),]
|
| 124 |
+
layers += [nn.Conv2d(chn_mid, 1, 1, stride=1, padding=0, bias=True),]
|
| 125 |
+
if(use_sigmoid):
|
| 126 |
+
layers += [nn.Sigmoid(),]
|
| 127 |
+
self.model = nn.Sequential(*layers)
|
| 128 |
+
|
| 129 |
+
def forward(self,d0,d1,eps=0.1):
|
| 130 |
+
return self.model.forward(torch.cat((d0,d1,d0-d1,d0/(d1+eps),d1/(d0+eps)),dim=1))
|
| 131 |
+
|
| 132 |
+
class BCERankingLoss(nn.Module):
|
| 133 |
+
def __init__(self, chn_mid=32):
|
| 134 |
+
super(BCERankingLoss, self).__init__()
|
| 135 |
+
self.net = Dist2LogitLayer(chn_mid=chn_mid)
|
| 136 |
+
# self.parameters = list(self.net.parameters())
|
| 137 |
+
self.loss = torch.nn.BCELoss()
|
| 138 |
+
|
| 139 |
+
def forward(self, d0, d1, judge):
|
| 140 |
+
per = (judge+1.)/2.
|
| 141 |
+
self.logit = self.net.forward(d0,d1)
|
| 142 |
+
return self.loss(self.logit, per)
|
| 143 |
+
|
| 144 |
+
# L2, DSSIM metrics
|
| 145 |
+
class FakeNet(nn.Module):
|
| 146 |
+
def __init__(self, use_gpu=True, colorspace='Lab'):
|
| 147 |
+
super(FakeNet, self).__init__()
|
| 148 |
+
self.use_gpu = use_gpu
|
| 149 |
+
self.colorspace=colorspace
|
| 150 |
+
|
| 151 |
+
class L2(FakeNet):
|
| 152 |
+
|
| 153 |
+
def forward(self, in0, in1, retPerLayer=None):
|
| 154 |
+
assert(in0.size()[0]==1) # currently only supports batchSize 1
|
| 155 |
+
|
| 156 |
+
if(self.colorspace=='RGB'):
|
| 157 |
+
(N,C,X,Y) = in0.size()
|
| 158 |
+
value = torch.mean(torch.mean(torch.mean((in0-in1)**2,dim=1).view(N,1,X,Y),dim=2).view(N,1,1,Y),dim=3).view(N)
|
| 159 |
+
return value
|
| 160 |
+
elif(self.colorspace=='Lab'):
|
| 161 |
+
value = util.l2(util.tensor2np(util.tensor2tensorlab(in0.data,to_norm=False)),
|
| 162 |
+
util.tensor2np(util.tensor2tensorlab(in1.data,to_norm=False)), range=100.).astype('float')
|
| 163 |
+
ret_var = Variable( torch.Tensor((value,) ) )
|
| 164 |
+
if(self.use_gpu):
|
| 165 |
+
ret_var = ret_var.cuda()
|
| 166 |
+
return ret_var
|
| 167 |
+
|
| 168 |
+
class DSSIM(FakeNet):
|
| 169 |
+
|
| 170 |
+
def forward(self, in0, in1, retPerLayer=None):
|
| 171 |
+
assert(in0.size()[0]==1) # currently only supports batchSize 1
|
| 172 |
+
|
| 173 |
+
if(self.colorspace=='RGB'):
|
| 174 |
+
value = util.dssim(1.*util.tensor2im(in0.data), 1.*util.tensor2im(in1.data), range=255.).astype('float')
|
| 175 |
+
elif(self.colorspace=='Lab'):
|
| 176 |
+
value = util.dssim(util.tensor2np(util.tensor2tensorlab(in0.data,to_norm=False)),
|
| 177 |
+
util.tensor2np(util.tensor2tensorlab(in1.data,to_norm=False)), range=100.).astype('float')
|
| 178 |
+
ret_var = Variable( torch.Tensor((value,) ) )
|
| 179 |
+
if(self.use_gpu):
|
| 180 |
+
ret_var = ret_var.cuda()
|
| 181 |
+
return ret_var
|
| 182 |
+
|
| 183 |
+
def print_network(net):
|
| 184 |
+
num_params = 0
|
| 185 |
+
for param in net.parameters():
|
| 186 |
+
num_params += param.numel()
|
| 187 |
+
print('Network',net)
|
| 188 |
+
print('Total number of parameters: %d' % num_params)
|
draggan/deprecated/stylegan2/lpips/pretrained_networks.py
ADDED
|
@@ -0,0 +1,181 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import namedtuple
|
| 2 |
+
import torch
|
| 3 |
+
from torchvision import models as tv
|
| 4 |
+
from IPython import embed
|
| 5 |
+
|
| 6 |
+
class squeezenet(torch.nn.Module):
|
| 7 |
+
def __init__(self, requires_grad=False, pretrained=True):
|
| 8 |
+
super(squeezenet, self).__init__()
|
| 9 |
+
pretrained_features = tv.squeezenet1_1(pretrained=pretrained).features
|
| 10 |
+
self.slice1 = torch.nn.Sequential()
|
| 11 |
+
self.slice2 = torch.nn.Sequential()
|
| 12 |
+
self.slice3 = torch.nn.Sequential()
|
| 13 |
+
self.slice4 = torch.nn.Sequential()
|
| 14 |
+
self.slice5 = torch.nn.Sequential()
|
| 15 |
+
self.slice6 = torch.nn.Sequential()
|
| 16 |
+
self.slice7 = torch.nn.Sequential()
|
| 17 |
+
self.N_slices = 7
|
| 18 |
+
for x in range(2):
|
| 19 |
+
self.slice1.add_module(str(x), pretrained_features[x])
|
| 20 |
+
for x in range(2,5):
|
| 21 |
+
self.slice2.add_module(str(x), pretrained_features[x])
|
| 22 |
+
for x in range(5, 8):
|
| 23 |
+
self.slice3.add_module(str(x), pretrained_features[x])
|
| 24 |
+
for x in range(8, 10):
|
| 25 |
+
self.slice4.add_module(str(x), pretrained_features[x])
|
| 26 |
+
for x in range(10, 11):
|
| 27 |
+
self.slice5.add_module(str(x), pretrained_features[x])
|
| 28 |
+
for x in range(11, 12):
|
| 29 |
+
self.slice6.add_module(str(x), pretrained_features[x])
|
| 30 |
+
for x in range(12, 13):
|
| 31 |
+
self.slice7.add_module(str(x), pretrained_features[x])
|
| 32 |
+
if not requires_grad:
|
| 33 |
+
for param in self.parameters():
|
| 34 |
+
param.requires_grad = False
|
| 35 |
+
|
| 36 |
+
def forward(self, X):
|
| 37 |
+
h = self.slice1(X)
|
| 38 |
+
h_relu1 = h
|
| 39 |
+
h = self.slice2(h)
|
| 40 |
+
h_relu2 = h
|
| 41 |
+
h = self.slice3(h)
|
| 42 |
+
h_relu3 = h
|
| 43 |
+
h = self.slice4(h)
|
| 44 |
+
h_relu4 = h
|
| 45 |
+
h = self.slice5(h)
|
| 46 |
+
h_relu5 = h
|
| 47 |
+
h = self.slice6(h)
|
| 48 |
+
h_relu6 = h
|
| 49 |
+
h = self.slice7(h)
|
| 50 |
+
h_relu7 = h
|
| 51 |
+
vgg_outputs = namedtuple("SqueezeOutputs", ['relu1','relu2','relu3','relu4','relu5','relu6','relu7'])
|
| 52 |
+
out = vgg_outputs(h_relu1,h_relu2,h_relu3,h_relu4,h_relu5,h_relu6,h_relu7)
|
| 53 |
+
|
| 54 |
+
return out
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class alexnet(torch.nn.Module):
|
| 58 |
+
def __init__(self, requires_grad=False, pretrained=True):
|
| 59 |
+
super(alexnet, self).__init__()
|
| 60 |
+
alexnet_pretrained_features = tv.alexnet(pretrained=pretrained).features
|
| 61 |
+
self.slice1 = torch.nn.Sequential()
|
| 62 |
+
self.slice2 = torch.nn.Sequential()
|
| 63 |
+
self.slice3 = torch.nn.Sequential()
|
| 64 |
+
self.slice4 = torch.nn.Sequential()
|
| 65 |
+
self.slice5 = torch.nn.Sequential()
|
| 66 |
+
self.N_slices = 5
|
| 67 |
+
for x in range(2):
|
| 68 |
+
self.slice1.add_module(str(x), alexnet_pretrained_features[x])
|
| 69 |
+
for x in range(2, 5):
|
| 70 |
+
self.slice2.add_module(str(x), alexnet_pretrained_features[x])
|
| 71 |
+
for x in range(5, 8):
|
| 72 |
+
self.slice3.add_module(str(x), alexnet_pretrained_features[x])
|
| 73 |
+
for x in range(8, 10):
|
| 74 |
+
self.slice4.add_module(str(x), alexnet_pretrained_features[x])
|
| 75 |
+
for x in range(10, 12):
|
| 76 |
+
self.slice5.add_module(str(x), alexnet_pretrained_features[x])
|
| 77 |
+
if not requires_grad:
|
| 78 |
+
for param in self.parameters():
|
| 79 |
+
param.requires_grad = False
|
| 80 |
+
|
| 81 |
+
def forward(self, X):
|
| 82 |
+
h = self.slice1(X)
|
| 83 |
+
h_relu1 = h
|
| 84 |
+
h = self.slice2(h)
|
| 85 |
+
h_relu2 = h
|
| 86 |
+
h = self.slice3(h)
|
| 87 |
+
h_relu3 = h
|
| 88 |
+
h = self.slice4(h)
|
| 89 |
+
h_relu4 = h
|
| 90 |
+
h = self.slice5(h)
|
| 91 |
+
h_relu5 = h
|
| 92 |
+
alexnet_outputs = namedtuple("AlexnetOutputs", ['relu1', 'relu2', 'relu3', 'relu4', 'relu5'])
|
| 93 |
+
out = alexnet_outputs(h_relu1, h_relu2, h_relu3, h_relu4, h_relu5)
|
| 94 |
+
|
| 95 |
+
return out
|
| 96 |
+
|
| 97 |
+
class vgg16(torch.nn.Module):
|
| 98 |
+
def __init__(self, requires_grad=False, pretrained=True):
|
| 99 |
+
super(vgg16, self).__init__()
|
| 100 |
+
vgg_pretrained_features = tv.vgg16(pretrained=pretrained).features
|
| 101 |
+
self.slice1 = torch.nn.Sequential()
|
| 102 |
+
self.slice2 = torch.nn.Sequential()
|
| 103 |
+
self.slice3 = torch.nn.Sequential()
|
| 104 |
+
self.slice4 = torch.nn.Sequential()
|
| 105 |
+
self.slice5 = torch.nn.Sequential()
|
| 106 |
+
self.N_slices = 5
|
| 107 |
+
for x in range(4):
|
| 108 |
+
self.slice1.add_module(str(x), vgg_pretrained_features[x])
|
| 109 |
+
for x in range(4, 9):
|
| 110 |
+
self.slice2.add_module(str(x), vgg_pretrained_features[x])
|
| 111 |
+
for x in range(9, 16):
|
| 112 |
+
self.slice3.add_module(str(x), vgg_pretrained_features[x])
|
| 113 |
+
for x in range(16, 23):
|
| 114 |
+
self.slice4.add_module(str(x), vgg_pretrained_features[x])
|
| 115 |
+
for x in range(23, 30):
|
| 116 |
+
self.slice5.add_module(str(x), vgg_pretrained_features[x])
|
| 117 |
+
if not requires_grad:
|
| 118 |
+
for param in self.parameters():
|
| 119 |
+
param.requires_grad = False
|
| 120 |
+
|
| 121 |
+
def forward(self, X):
|
| 122 |
+
h = self.slice1(X)
|
| 123 |
+
h_relu1_2 = h
|
| 124 |
+
h = self.slice2(h)
|
| 125 |
+
h_relu2_2 = h
|
| 126 |
+
h = self.slice3(h)
|
| 127 |
+
h_relu3_3 = h
|
| 128 |
+
h = self.slice4(h)
|
| 129 |
+
h_relu4_3 = h
|
| 130 |
+
h = self.slice5(h)
|
| 131 |
+
h_relu5_3 = h
|
| 132 |
+
vgg_outputs = namedtuple("VggOutputs", ['relu1_2', 'relu2_2', 'relu3_3', 'relu4_3', 'relu5_3'])
|
| 133 |
+
out = vgg_outputs(h_relu1_2, h_relu2_2, h_relu3_3, h_relu4_3, h_relu5_3)
|
| 134 |
+
|
| 135 |
+
return out
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
class resnet(torch.nn.Module):
|
| 140 |
+
def __init__(self, requires_grad=False, pretrained=True, num=18):
|
| 141 |
+
super(resnet, self).__init__()
|
| 142 |
+
if(num==18):
|
| 143 |
+
self.net = tv.resnet18(pretrained=pretrained)
|
| 144 |
+
elif(num==34):
|
| 145 |
+
self.net = tv.resnet34(pretrained=pretrained)
|
| 146 |
+
elif(num==50):
|
| 147 |
+
self.net = tv.resnet50(pretrained=pretrained)
|
| 148 |
+
elif(num==101):
|
| 149 |
+
self.net = tv.resnet101(pretrained=pretrained)
|
| 150 |
+
elif(num==152):
|
| 151 |
+
self.net = tv.resnet152(pretrained=pretrained)
|
| 152 |
+
self.N_slices = 5
|
| 153 |
+
|
| 154 |
+
self.conv1 = self.net.conv1
|
| 155 |
+
self.bn1 = self.net.bn1
|
| 156 |
+
self.relu = self.net.relu
|
| 157 |
+
self.maxpool = self.net.maxpool
|
| 158 |
+
self.layer1 = self.net.layer1
|
| 159 |
+
self.layer2 = self.net.layer2
|
| 160 |
+
self.layer3 = self.net.layer3
|
| 161 |
+
self.layer4 = self.net.layer4
|
| 162 |
+
|
| 163 |
+
def forward(self, X):
|
| 164 |
+
h = self.conv1(X)
|
| 165 |
+
h = self.bn1(h)
|
| 166 |
+
h = self.relu(h)
|
| 167 |
+
h_relu1 = h
|
| 168 |
+
h = self.maxpool(h)
|
| 169 |
+
h = self.layer1(h)
|
| 170 |
+
h_conv2 = h
|
| 171 |
+
h = self.layer2(h)
|
| 172 |
+
h_conv3 = h
|
| 173 |
+
h = self.layer3(h)
|
| 174 |
+
h_conv4 = h
|
| 175 |
+
h = self.layer4(h)
|
| 176 |
+
h_conv5 = h
|
| 177 |
+
|
| 178 |
+
outputs = namedtuple("Outputs", ['relu1','conv2','conv3','conv4','conv5'])
|
| 179 |
+
out = outputs(h_relu1, h_conv2, h_conv3, h_conv4, h_conv5)
|
| 180 |
+
|
| 181 |
+
return out
|
draggan/deprecated/stylegan2/lpips/util.py
ADDED
|
@@ -0,0 +1,160 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from __future__ import absolute_import
|
| 3 |
+
from __future__ import division
|
| 4 |
+
from __future__ import print_function
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
from skimage.metrics import structural_similarity
|
| 8 |
+
import torch
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
from . import dist_model
|
| 12 |
+
|
| 13 |
+
class PerceptualLoss(torch.nn.Module):
|
| 14 |
+
def __init__(self, model='net-lin', net='alex', colorspace='rgb', spatial=False, use_gpu=True, gpu_ids=[0]): # VGG using our perceptually-learned weights (LPIPS metric)
|
| 15 |
+
# def __init__(self, model='net', net='vgg', use_gpu=True): # "default" way of using VGG as a perceptual loss
|
| 16 |
+
super(PerceptualLoss, self).__init__()
|
| 17 |
+
print('Setting up Perceptual loss...')
|
| 18 |
+
self.use_gpu = use_gpu
|
| 19 |
+
self.spatial = spatial
|
| 20 |
+
self.gpu_ids = gpu_ids
|
| 21 |
+
self.model = dist_model.DistModel()
|
| 22 |
+
self.model.initialize(model=model, net=net, use_gpu=use_gpu, colorspace=colorspace, spatial=self.spatial, gpu_ids=gpu_ids)
|
| 23 |
+
print('...[%s] initialized'%self.model.name())
|
| 24 |
+
print('...Done')
|
| 25 |
+
|
| 26 |
+
def forward(self, pred, target, normalize=False):
|
| 27 |
+
"""
|
| 28 |
+
Pred and target are Variables.
|
| 29 |
+
If normalize is True, assumes the images are between [0,1] and then scales them between [-1,+1]
|
| 30 |
+
If normalize is False, assumes the images are already between [-1,+1]
|
| 31 |
+
|
| 32 |
+
Inputs pred and target are Nx3xHxW
|
| 33 |
+
Output pytorch Variable N long
|
| 34 |
+
"""
|
| 35 |
+
|
| 36 |
+
if normalize:
|
| 37 |
+
target = 2 * target - 1
|
| 38 |
+
pred = 2 * pred - 1
|
| 39 |
+
|
| 40 |
+
return self.model.forward(target, pred)
|
| 41 |
+
|
| 42 |
+
def normalize_tensor(in_feat,eps=1e-10):
|
| 43 |
+
norm_factor = torch.sqrt(torch.sum(in_feat**2,dim=1,keepdim=True))
|
| 44 |
+
return in_feat/(norm_factor+eps)
|
| 45 |
+
|
| 46 |
+
def l2(p0, p1, range=255.):
|
| 47 |
+
return .5*np.mean((p0 / range - p1 / range)**2)
|
| 48 |
+
|
| 49 |
+
def psnr(p0, p1, peak=255.):
|
| 50 |
+
return 10*np.log10(peak**2/np.mean((1.*p0-1.*p1)**2))
|
| 51 |
+
|
| 52 |
+
def dssim(p0, p1, range=255.):
|
| 53 |
+
return (1 - structural_similarity(p0, p1, data_range=range, multichannel=True)) / 2.
|
| 54 |
+
|
| 55 |
+
def rgb2lab(in_img,mean_cent=False):
|
| 56 |
+
from skimage import color
|
| 57 |
+
img_lab = color.rgb2lab(in_img)
|
| 58 |
+
if(mean_cent):
|
| 59 |
+
img_lab[:,:,0] = img_lab[:,:,0]-50
|
| 60 |
+
return img_lab
|
| 61 |
+
|
| 62 |
+
def tensor2np(tensor_obj):
|
| 63 |
+
# change dimension of a tensor object into a numpy array
|
| 64 |
+
return tensor_obj[0].cpu().float().numpy().transpose((1,2,0))
|
| 65 |
+
|
| 66 |
+
def np2tensor(np_obj):
|
| 67 |
+
# change dimenion of np array into tensor array
|
| 68 |
+
return torch.Tensor(np_obj[:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
|
| 69 |
+
|
| 70 |
+
def tensor2tensorlab(image_tensor,to_norm=True,mc_only=False):
|
| 71 |
+
# image tensor to lab tensor
|
| 72 |
+
from skimage import color
|
| 73 |
+
|
| 74 |
+
img = tensor2im(image_tensor)
|
| 75 |
+
img_lab = color.rgb2lab(img)
|
| 76 |
+
if(mc_only):
|
| 77 |
+
img_lab[:,:,0] = img_lab[:,:,0]-50
|
| 78 |
+
if(to_norm and not mc_only):
|
| 79 |
+
img_lab[:,:,0] = img_lab[:,:,0]-50
|
| 80 |
+
img_lab = img_lab/100.
|
| 81 |
+
|
| 82 |
+
return np2tensor(img_lab)
|
| 83 |
+
|
| 84 |
+
def tensorlab2tensor(lab_tensor,return_inbnd=False):
|
| 85 |
+
from skimage import color
|
| 86 |
+
import warnings
|
| 87 |
+
warnings.filterwarnings("ignore")
|
| 88 |
+
|
| 89 |
+
lab = tensor2np(lab_tensor)*100.
|
| 90 |
+
lab[:,:,0] = lab[:,:,0]+50
|
| 91 |
+
|
| 92 |
+
rgb_back = 255.*np.clip(color.lab2rgb(lab.astype('float')),0,1)
|
| 93 |
+
if(return_inbnd):
|
| 94 |
+
# convert back to lab, see if we match
|
| 95 |
+
lab_back = color.rgb2lab(rgb_back.astype('uint8'))
|
| 96 |
+
mask = 1.*np.isclose(lab_back,lab,atol=2.)
|
| 97 |
+
mask = np2tensor(np.prod(mask,axis=2)[:,:,np.newaxis])
|
| 98 |
+
return (im2tensor(rgb_back),mask)
|
| 99 |
+
else:
|
| 100 |
+
return im2tensor(rgb_back)
|
| 101 |
+
|
| 102 |
+
def rgb2lab(input):
|
| 103 |
+
from skimage import color
|
| 104 |
+
return color.rgb2lab(input / 255.)
|
| 105 |
+
|
| 106 |
+
def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=255./2.):
|
| 107 |
+
image_numpy = image_tensor[0].cpu().float().numpy()
|
| 108 |
+
image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
|
| 109 |
+
return image_numpy.astype(imtype)
|
| 110 |
+
|
| 111 |
+
def im2tensor(image, imtype=np.uint8, cent=1., factor=255./2.):
|
| 112 |
+
return torch.Tensor((image / factor - cent)
|
| 113 |
+
[:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
|
| 114 |
+
|
| 115 |
+
def tensor2vec(vector_tensor):
|
| 116 |
+
return vector_tensor.data.cpu().numpy()[:, :, 0, 0]
|
| 117 |
+
|
| 118 |
+
def voc_ap(rec, prec, use_07_metric=False):
|
| 119 |
+
""" ap = voc_ap(rec, prec, [use_07_metric])
|
| 120 |
+
Compute VOC AP given precision and recall.
|
| 121 |
+
If use_07_metric is true, uses the
|
| 122 |
+
VOC 07 11 point method (default:False).
|
| 123 |
+
"""
|
| 124 |
+
if use_07_metric:
|
| 125 |
+
# 11 point metric
|
| 126 |
+
ap = 0.
|
| 127 |
+
for t in np.arange(0., 1.1, 0.1):
|
| 128 |
+
if np.sum(rec >= t) == 0:
|
| 129 |
+
p = 0
|
| 130 |
+
else:
|
| 131 |
+
p = np.max(prec[rec >= t])
|
| 132 |
+
ap = ap + p / 11.
|
| 133 |
+
else:
|
| 134 |
+
# correct AP calculation
|
| 135 |
+
# first append sentinel values at the end
|
| 136 |
+
mrec = np.concatenate(([0.], rec, [1.]))
|
| 137 |
+
mpre = np.concatenate(([0.], prec, [0.]))
|
| 138 |
+
|
| 139 |
+
# compute the precision envelope
|
| 140 |
+
for i in range(mpre.size - 1, 0, -1):
|
| 141 |
+
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
|
| 142 |
+
|
| 143 |
+
# to calculate area under PR curve, look for points
|
| 144 |
+
# where X axis (recall) changes value
|
| 145 |
+
i = np.where(mrec[1:] != mrec[:-1])[0]
|
| 146 |
+
|
| 147 |
+
# and sum (\Delta recall) * prec
|
| 148 |
+
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
|
| 149 |
+
return ap
|
| 150 |
+
|
| 151 |
+
def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=255./2.):
|
| 152 |
+
# def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=1.):
|
| 153 |
+
image_numpy = image_tensor[0].cpu().float().numpy()
|
| 154 |
+
image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
|
| 155 |
+
return image_numpy.astype(imtype)
|
| 156 |
+
|
| 157 |
+
def im2tensor(image, imtype=np.uint8, cent=1., factor=255./2.):
|
| 158 |
+
# def im2tensor(image, imtype=np.uint8, cent=1., factor=1.):
|
| 159 |
+
return torch.Tensor((image / factor - cent)
|
| 160 |
+
[:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
|
draggan/deprecated/stylegan2/model.py
ADDED
|
@@ -0,0 +1,713 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import random
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch import nn
|
| 6 |
+
from torch.nn import functional as F
|
| 7 |
+
|
| 8 |
+
from .op.fused_act import fused
|
| 9 |
+
|
| 10 |
+
if fused is not None:
|
| 11 |
+
from .op.fused_act import FusedLeakyReLU, fused_leaky_relu
|
| 12 |
+
else:
|
| 13 |
+
from .op import FusedLeakyReLU_Native as FusedLeakyReLU
|
| 14 |
+
from .op import fused_leaky_relu_native as fused_leaky_relu
|
| 15 |
+
|
| 16 |
+
from .op.upfirdn2d import upfirdn2d_op
|
| 17 |
+
|
| 18 |
+
if upfirdn2d_op is not None:
|
| 19 |
+
from .op.upfirdn2d import upfirdn2d
|
| 20 |
+
else:
|
| 21 |
+
from .op import upfirdn2d_native as upfirdn2d
|
| 22 |
+
|
| 23 |
+
from .op import conv2d_gradfix
|
| 24 |
+
|
| 25 |
+
# https://github.com/rosinality/stylegan2-pytorch/blob/master/op/upfirdn2d.py#L152
|
| 26 |
+
# https://github.com/rosinality/stylegan2-pytorch/issues/70
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class PixelNorm(nn.Module):
|
| 30 |
+
def __init__(self):
|
| 31 |
+
super().__init__()
|
| 32 |
+
|
| 33 |
+
def forward(self, input):
|
| 34 |
+
return input * torch.rsqrt(torch.mean(input ** 2, dim=1, keepdim=True) + 1e-8)
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def make_kernel(k):
|
| 38 |
+
k = torch.tensor(k, dtype=torch.float32)
|
| 39 |
+
|
| 40 |
+
if k.ndim == 1:
|
| 41 |
+
k = k[None, :] * k[:, None]
|
| 42 |
+
|
| 43 |
+
k /= k.sum()
|
| 44 |
+
|
| 45 |
+
return k
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class Upsample(nn.Module):
|
| 49 |
+
def __init__(self, kernel, factor=2):
|
| 50 |
+
super().__init__()
|
| 51 |
+
|
| 52 |
+
self.factor = factor
|
| 53 |
+
kernel = make_kernel(kernel) * (factor ** 2)
|
| 54 |
+
self.register_buffer("kernel", kernel)
|
| 55 |
+
|
| 56 |
+
p = kernel.shape[0] - factor
|
| 57 |
+
|
| 58 |
+
pad0 = (p + 1) // 2 + factor - 1
|
| 59 |
+
pad1 = p // 2
|
| 60 |
+
|
| 61 |
+
self.pad = (pad0, pad1)
|
| 62 |
+
|
| 63 |
+
def forward(self, input):
|
| 64 |
+
out = upfirdn2d(input, self.kernel, up=self.factor, down=1, pad=self.pad)
|
| 65 |
+
|
| 66 |
+
return out
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
class Downsample(nn.Module):
|
| 70 |
+
def __init__(self, kernel, factor=2):
|
| 71 |
+
super().__init__()
|
| 72 |
+
|
| 73 |
+
self.factor = factor
|
| 74 |
+
kernel = make_kernel(kernel)
|
| 75 |
+
self.register_buffer("kernel", kernel)
|
| 76 |
+
|
| 77 |
+
p = kernel.shape[0] - factor
|
| 78 |
+
|
| 79 |
+
pad0 = (p + 1) // 2
|
| 80 |
+
pad1 = p // 2
|
| 81 |
+
|
| 82 |
+
self.pad = (pad0, pad1)
|
| 83 |
+
|
| 84 |
+
def forward(self, input):
|
| 85 |
+
out = upfirdn2d(input, self.kernel, up=1, down=self.factor, pad=self.pad)
|
| 86 |
+
|
| 87 |
+
return out
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
class Blur(nn.Module):
|
| 91 |
+
def __init__(self, kernel, pad, upsample_factor=1):
|
| 92 |
+
super().__init__()
|
| 93 |
+
|
| 94 |
+
kernel = make_kernel(kernel)
|
| 95 |
+
|
| 96 |
+
if upsample_factor > 1:
|
| 97 |
+
kernel = kernel * (upsample_factor ** 2)
|
| 98 |
+
|
| 99 |
+
self.register_buffer("kernel", kernel)
|
| 100 |
+
|
| 101 |
+
self.pad = pad
|
| 102 |
+
|
| 103 |
+
def forward(self, input):
|
| 104 |
+
out = upfirdn2d(input, self.kernel, pad=self.pad)
|
| 105 |
+
|
| 106 |
+
return out
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
class EqualConv2d(nn.Module):
|
| 110 |
+
def __init__(
|
| 111 |
+
self, in_channel, out_channel, kernel_size, stride=1, padding=0, bias=True
|
| 112 |
+
):
|
| 113 |
+
super().__init__()
|
| 114 |
+
|
| 115 |
+
self.weight = nn.Parameter(
|
| 116 |
+
torch.randn(out_channel, in_channel, kernel_size, kernel_size)
|
| 117 |
+
)
|
| 118 |
+
self.scale = 1 / math.sqrt(in_channel * kernel_size ** 2)
|
| 119 |
+
|
| 120 |
+
self.stride = stride
|
| 121 |
+
self.padding = padding
|
| 122 |
+
|
| 123 |
+
if bias:
|
| 124 |
+
self.bias = nn.Parameter(torch.zeros(out_channel))
|
| 125 |
+
|
| 126 |
+
else:
|
| 127 |
+
self.bias = None
|
| 128 |
+
|
| 129 |
+
def forward(self, input):
|
| 130 |
+
out = conv2d_gradfix.conv2d(
|
| 131 |
+
input,
|
| 132 |
+
self.weight * self.scale,
|
| 133 |
+
bias=self.bias,
|
| 134 |
+
stride=self.stride,
|
| 135 |
+
padding=self.padding,
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
return out
|
| 139 |
+
|
| 140 |
+
def __repr__(self):
|
| 141 |
+
return (
|
| 142 |
+
f"{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]},"
|
| 143 |
+
f" {self.weight.shape[2]}, stride={self.stride}, padding={self.padding})"
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
class EqualLinear(nn.Module):
|
| 148 |
+
def __init__(
|
| 149 |
+
self, in_dim, out_dim, bias=True, bias_init=0, lr_mul=1, activation=None
|
| 150 |
+
):
|
| 151 |
+
super().__init__()
|
| 152 |
+
|
| 153 |
+
self.weight = nn.Parameter(torch.randn(out_dim, in_dim).div_(lr_mul))
|
| 154 |
+
|
| 155 |
+
if bias:
|
| 156 |
+
self.bias = nn.Parameter(torch.zeros(out_dim).fill_(bias_init))
|
| 157 |
+
|
| 158 |
+
else:
|
| 159 |
+
self.bias = None
|
| 160 |
+
|
| 161 |
+
self.activation = activation
|
| 162 |
+
|
| 163 |
+
self.scale = (1 / math.sqrt(in_dim)) * lr_mul
|
| 164 |
+
self.lr_mul = lr_mul
|
| 165 |
+
|
| 166 |
+
def forward(self, input):
|
| 167 |
+
if self.activation:
|
| 168 |
+
out = F.linear(input, self.weight * self.scale)
|
| 169 |
+
out = fused_leaky_relu(out, self.bias * self.lr_mul)
|
| 170 |
+
|
| 171 |
+
else:
|
| 172 |
+
out = F.linear(
|
| 173 |
+
input, self.weight * self.scale, bias=self.bias * self.lr_mul
|
| 174 |
+
)
|
| 175 |
+
|
| 176 |
+
return out
|
| 177 |
+
|
| 178 |
+
def __repr__(self):
|
| 179 |
+
return (
|
| 180 |
+
f"{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]})"
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
class ModulatedConv2d(nn.Module):
|
| 185 |
+
def __init__(
|
| 186 |
+
self,
|
| 187 |
+
in_channel,
|
| 188 |
+
out_channel,
|
| 189 |
+
kernel_size,
|
| 190 |
+
style_dim,
|
| 191 |
+
demodulate=True,
|
| 192 |
+
upsample=False,
|
| 193 |
+
downsample=False,
|
| 194 |
+
blur_kernel=[1, 3, 3, 1],
|
| 195 |
+
fused=True,
|
| 196 |
+
):
|
| 197 |
+
super().__init__()
|
| 198 |
+
|
| 199 |
+
self.eps = 1e-8
|
| 200 |
+
self.kernel_size = kernel_size
|
| 201 |
+
self.in_channel = in_channel
|
| 202 |
+
self.out_channel = out_channel
|
| 203 |
+
self.upsample = upsample
|
| 204 |
+
self.downsample = downsample
|
| 205 |
+
|
| 206 |
+
if upsample:
|
| 207 |
+
factor = 2
|
| 208 |
+
p = (len(blur_kernel) - factor) - (kernel_size - 1)
|
| 209 |
+
pad0 = (p + 1) // 2 + factor - 1
|
| 210 |
+
pad1 = p // 2 + 1
|
| 211 |
+
|
| 212 |
+
self.blur = Blur(blur_kernel, pad=(pad0, pad1), upsample_factor=factor)
|
| 213 |
+
|
| 214 |
+
if downsample:
|
| 215 |
+
factor = 2
|
| 216 |
+
p = (len(blur_kernel) - factor) + (kernel_size - 1)
|
| 217 |
+
pad0 = (p + 1) // 2
|
| 218 |
+
pad1 = p // 2
|
| 219 |
+
|
| 220 |
+
self.blur = Blur(blur_kernel, pad=(pad0, pad1))
|
| 221 |
+
|
| 222 |
+
fan_in = in_channel * kernel_size ** 2
|
| 223 |
+
self.scale = 1 / math.sqrt(fan_in)
|
| 224 |
+
self.padding = kernel_size // 2
|
| 225 |
+
|
| 226 |
+
self.weight = nn.Parameter(
|
| 227 |
+
torch.randn(1, out_channel, in_channel, kernel_size, kernel_size)
|
| 228 |
+
)
|
| 229 |
+
|
| 230 |
+
self.modulation = EqualLinear(style_dim, in_channel, bias_init=1)
|
| 231 |
+
|
| 232 |
+
self.demodulate = demodulate
|
| 233 |
+
self.fused = fused
|
| 234 |
+
|
| 235 |
+
def __repr__(self):
|
| 236 |
+
return (
|
| 237 |
+
f"{self.__class__.__name__}({self.in_channel}, {self.out_channel}, {self.kernel_size}, "
|
| 238 |
+
f"upsample={self.upsample}, downsample={self.downsample})"
|
| 239 |
+
)
|
| 240 |
+
|
| 241 |
+
def forward(self, input, style):
|
| 242 |
+
batch, in_channel, height, width = input.shape
|
| 243 |
+
|
| 244 |
+
if not self.fused:
|
| 245 |
+
weight = self.scale * self.weight.squeeze(0)
|
| 246 |
+
style = self.modulation(style)
|
| 247 |
+
|
| 248 |
+
if self.demodulate:
|
| 249 |
+
w = weight.unsqueeze(0) * style.view(batch, 1, in_channel, 1, 1)
|
| 250 |
+
dcoefs = (w.square().sum((2, 3, 4)) + 1e-8).rsqrt()
|
| 251 |
+
|
| 252 |
+
input = input * style.reshape(batch, in_channel, 1, 1)
|
| 253 |
+
|
| 254 |
+
if self.upsample:
|
| 255 |
+
weight = weight.transpose(0, 1)
|
| 256 |
+
out = conv2d_gradfix.conv_transpose2d(
|
| 257 |
+
input, weight, padding=0, stride=2
|
| 258 |
+
)
|
| 259 |
+
out = self.blur(out)
|
| 260 |
+
|
| 261 |
+
elif self.downsample:
|
| 262 |
+
input = self.blur(input)
|
| 263 |
+
out = conv2d_gradfix.conv2d(input, weight, padding=0, stride=2)
|
| 264 |
+
|
| 265 |
+
else:
|
| 266 |
+
out = conv2d_gradfix.conv2d(input, weight, padding=self.padding)
|
| 267 |
+
|
| 268 |
+
if self.demodulate:
|
| 269 |
+
out = out * dcoefs.view(batch, -1, 1, 1)
|
| 270 |
+
|
| 271 |
+
return out
|
| 272 |
+
|
| 273 |
+
style = self.modulation(style).view(batch, 1, in_channel, 1, 1)
|
| 274 |
+
weight = self.scale * self.weight * style
|
| 275 |
+
|
| 276 |
+
if self.demodulate:
|
| 277 |
+
demod = torch.rsqrt(weight.pow(2).sum([2, 3, 4]) + 1e-8)
|
| 278 |
+
weight = weight * demod.view(batch, self.out_channel, 1, 1, 1)
|
| 279 |
+
|
| 280 |
+
weight = weight.view(
|
| 281 |
+
batch * self.out_channel, in_channel, self.kernel_size, self.kernel_size
|
| 282 |
+
)
|
| 283 |
+
|
| 284 |
+
if self.upsample:
|
| 285 |
+
input = input.view(1, batch * in_channel, height, width)
|
| 286 |
+
weight = weight.view(
|
| 287 |
+
batch, self.out_channel, in_channel, self.kernel_size, self.kernel_size
|
| 288 |
+
)
|
| 289 |
+
weight = weight.transpose(1, 2).reshape(
|
| 290 |
+
batch * in_channel, self.out_channel, self.kernel_size, self.kernel_size
|
| 291 |
+
)
|
| 292 |
+
out = conv2d_gradfix.conv_transpose2d(
|
| 293 |
+
input, weight, padding=0, stride=2, groups=batch
|
| 294 |
+
)
|
| 295 |
+
_, _, height, width = out.shape
|
| 296 |
+
out = out.view(batch, self.out_channel, height, width)
|
| 297 |
+
out = self.blur(out)
|
| 298 |
+
|
| 299 |
+
elif self.downsample:
|
| 300 |
+
input = self.blur(input)
|
| 301 |
+
_, _, height, width = input.shape
|
| 302 |
+
input = input.view(1, batch * in_channel, height, width)
|
| 303 |
+
out = conv2d_gradfix.conv2d(
|
| 304 |
+
input, weight, padding=0, stride=2, groups=batch
|
| 305 |
+
)
|
| 306 |
+
_, _, height, width = out.shape
|
| 307 |
+
out = out.view(batch, self.out_channel, height, width)
|
| 308 |
+
|
| 309 |
+
else:
|
| 310 |
+
input = input.view(1, batch * in_channel, height, width)
|
| 311 |
+
out = conv2d_gradfix.conv2d(
|
| 312 |
+
input, weight, padding=self.padding, groups=batch
|
| 313 |
+
)
|
| 314 |
+
_, _, height, width = out.shape
|
| 315 |
+
out = out.view(batch, self.out_channel, height, width)
|
| 316 |
+
|
| 317 |
+
return out
|
| 318 |
+
|
| 319 |
+
|
| 320 |
+
class NoiseInjection(nn.Module):
|
| 321 |
+
def __init__(self):
|
| 322 |
+
super().__init__()
|
| 323 |
+
|
| 324 |
+
self.weight = nn.Parameter(torch.zeros(1))
|
| 325 |
+
|
| 326 |
+
def forward(self, image, noise=None):
|
| 327 |
+
if noise is None:
|
| 328 |
+
batch, _, height, width = image.shape
|
| 329 |
+
noise = image.new_empty(batch, 1, height, width).normal_()
|
| 330 |
+
|
| 331 |
+
return image + self.weight * noise
|
| 332 |
+
|
| 333 |
+
|
| 334 |
+
class ConstantInput(nn.Module):
|
| 335 |
+
def __init__(self, channel, size_in=4, size_out=4):
|
| 336 |
+
super().__init__()
|
| 337 |
+
|
| 338 |
+
self.input = nn.Parameter(torch.randn(1, channel, size_in, size_out))
|
| 339 |
+
|
| 340 |
+
def forward(self, input):
|
| 341 |
+
batch = input.shape[0]
|
| 342 |
+
out = self.input.repeat(batch, 1, 1, 1)
|
| 343 |
+
|
| 344 |
+
return out
|
| 345 |
+
|
| 346 |
+
|
| 347 |
+
class StyledConv(nn.Module):
|
| 348 |
+
def __init__(
|
| 349 |
+
self,
|
| 350 |
+
in_channel,
|
| 351 |
+
out_channel,
|
| 352 |
+
kernel_size,
|
| 353 |
+
style_dim,
|
| 354 |
+
upsample=False,
|
| 355 |
+
blur_kernel=[1, 3, 3, 1],
|
| 356 |
+
demodulate=True,
|
| 357 |
+
):
|
| 358 |
+
super().__init__()
|
| 359 |
+
|
| 360 |
+
self.conv = ModulatedConv2d(
|
| 361 |
+
in_channel,
|
| 362 |
+
out_channel,
|
| 363 |
+
kernel_size,
|
| 364 |
+
style_dim,
|
| 365 |
+
upsample=upsample,
|
| 366 |
+
blur_kernel=blur_kernel,
|
| 367 |
+
demodulate=demodulate,
|
| 368 |
+
)
|
| 369 |
+
|
| 370 |
+
self.noise = NoiseInjection()
|
| 371 |
+
# self.bias = nn.Parameter(torch.zeros(1, out_channel, 1, 1))
|
| 372 |
+
# self.activate = ScaledLeakyReLU(0.2)
|
| 373 |
+
self.activate = FusedLeakyReLU(out_channel)
|
| 374 |
+
|
| 375 |
+
def forward(self, input, style, noise=None):
|
| 376 |
+
out = self.conv(input, style)
|
| 377 |
+
out = self.noise(out, noise=noise)
|
| 378 |
+
# out = out + self.bias
|
| 379 |
+
out = self.activate(out)
|
| 380 |
+
|
| 381 |
+
return out
|
| 382 |
+
|
| 383 |
+
|
| 384 |
+
class ToRGB(nn.Module):
|
| 385 |
+
def __init__(self, in_channel, style_dim, upsample=True, blur_kernel=[1, 3, 3, 1]):
|
| 386 |
+
super().__init__()
|
| 387 |
+
|
| 388 |
+
if upsample:
|
| 389 |
+
self.upsample = Upsample(blur_kernel)
|
| 390 |
+
|
| 391 |
+
self.conv = ModulatedConv2d(in_channel, 3, 1, style_dim, demodulate=False)
|
| 392 |
+
self.bias = nn.Parameter(torch.zeros(1, 3, 1, 1))
|
| 393 |
+
|
| 394 |
+
def forward(self, input, style, skip=None):
|
| 395 |
+
out = self.conv(input, style)
|
| 396 |
+
out = out + self.bias
|
| 397 |
+
|
| 398 |
+
if skip is not None:
|
| 399 |
+
skip = self.upsample(skip)
|
| 400 |
+
|
| 401 |
+
out = out + skip
|
| 402 |
+
|
| 403 |
+
return out
|
| 404 |
+
|
| 405 |
+
|
| 406 |
+
class Generator(nn.Module):
|
| 407 |
+
def __init__(
|
| 408 |
+
self,
|
| 409 |
+
size,
|
| 410 |
+
style_dim,
|
| 411 |
+
n_mlp,
|
| 412 |
+
channel_multiplier=2,
|
| 413 |
+
blur_kernel=[1, 3, 3, 1],
|
| 414 |
+
lr_mlp=0.01,
|
| 415 |
+
human=False,
|
| 416 |
+
):
|
| 417 |
+
super().__init__()
|
| 418 |
+
|
| 419 |
+
self.size = size
|
| 420 |
+
|
| 421 |
+
self.style_dim = style_dim
|
| 422 |
+
|
| 423 |
+
layers = [PixelNorm()]
|
| 424 |
+
|
| 425 |
+
for i in range(n_mlp):
|
| 426 |
+
layers.append(
|
| 427 |
+
EqualLinear(
|
| 428 |
+
style_dim, style_dim, lr_mul=lr_mlp, activation="fused_lrelu"
|
| 429 |
+
)
|
| 430 |
+
)
|
| 431 |
+
|
| 432 |
+
self.style = nn.Sequential(*layers)
|
| 433 |
+
|
| 434 |
+
self.channels = {
|
| 435 |
+
4: 512,
|
| 436 |
+
8: 512,
|
| 437 |
+
16: 512,
|
| 438 |
+
32: 512,
|
| 439 |
+
64: 256 * channel_multiplier,
|
| 440 |
+
128: 128 * channel_multiplier,
|
| 441 |
+
256: 64 * channel_multiplier,
|
| 442 |
+
512: 32 * channel_multiplier,
|
| 443 |
+
1024: 16 * channel_multiplier,
|
| 444 |
+
}
|
| 445 |
+
|
| 446 |
+
self.input = ConstantInput(self.channels[4], size_in=4, size_out=4 if not human else 2)
|
| 447 |
+
self.conv1 = StyledConv(
|
| 448 |
+
self.channels[4], self.channels[4], 3, style_dim, blur_kernel=blur_kernel
|
| 449 |
+
)
|
| 450 |
+
self.to_rgb1 = ToRGB(self.channels[4], style_dim, upsample=False)
|
| 451 |
+
|
| 452 |
+
self.log_size = int(math.log(size, 2))
|
| 453 |
+
self.num_layers = (self.log_size - 2) * 2 + 1
|
| 454 |
+
|
| 455 |
+
self.convs = nn.ModuleList()
|
| 456 |
+
self.upsamples = nn.ModuleList()
|
| 457 |
+
self.to_rgbs = nn.ModuleList()
|
| 458 |
+
self.noises = nn.Module()
|
| 459 |
+
|
| 460 |
+
in_channel = self.channels[4]
|
| 461 |
+
|
| 462 |
+
for layer_idx in range(self.num_layers):
|
| 463 |
+
res = (layer_idx + 5) // 2
|
| 464 |
+
shape = [1, 1, 2 ** res, 2 ** (res-int(human))]
|
| 465 |
+
self.noises.register_buffer(f"noise_{layer_idx}", torch.randn(*shape))
|
| 466 |
+
|
| 467 |
+
for i in range(3, self.log_size + 1):
|
| 468 |
+
out_channel = self.channels[2 ** i]
|
| 469 |
+
|
| 470 |
+
self.convs.append(
|
| 471 |
+
StyledConv(
|
| 472 |
+
in_channel,
|
| 473 |
+
out_channel,
|
| 474 |
+
3,
|
| 475 |
+
style_dim,
|
| 476 |
+
upsample=True,
|
| 477 |
+
blur_kernel=blur_kernel,
|
| 478 |
+
)
|
| 479 |
+
)
|
| 480 |
+
|
| 481 |
+
self.convs.append(
|
| 482 |
+
StyledConv(
|
| 483 |
+
out_channel, out_channel, 3, style_dim, blur_kernel=blur_kernel
|
| 484 |
+
)
|
| 485 |
+
)
|
| 486 |
+
|
| 487 |
+
self.to_rgbs.append(ToRGB(out_channel, style_dim))
|
| 488 |
+
|
| 489 |
+
in_channel = out_channel
|
| 490 |
+
|
| 491 |
+
self.n_latent = self.log_size * 2 - 2
|
| 492 |
+
|
| 493 |
+
def make_noise(self):
|
| 494 |
+
device = self.input.input.device
|
| 495 |
+
|
| 496 |
+
noises = [torch.randn(1, 1, 2 ** 2, 2 ** 2, device=device)]
|
| 497 |
+
|
| 498 |
+
for i in range(3, self.log_size + 1):
|
| 499 |
+
for _ in range(2):
|
| 500 |
+
noises.append(torch.randn(1, 1, 2 ** i, 2 ** i, device=device))
|
| 501 |
+
|
| 502 |
+
return noises
|
| 503 |
+
|
| 504 |
+
def mean_latent(self, n_latent):
|
| 505 |
+
latent_in = torch.randn(
|
| 506 |
+
n_latent, self.style_dim, device=self.input.input.device
|
| 507 |
+
)
|
| 508 |
+
latent = self.style(latent_in).mean(0, keepdim=True)
|
| 509 |
+
|
| 510 |
+
return latent
|
| 511 |
+
|
| 512 |
+
def get_latent(self, input):
|
| 513 |
+
return self.style(input)
|
| 514 |
+
|
| 515 |
+
def forward(
|
| 516 |
+
self,
|
| 517 |
+
styles,
|
| 518 |
+
return_latents=False,
|
| 519 |
+
inject_index=None,
|
| 520 |
+
truncation=1,
|
| 521 |
+
truncation_latent=None,
|
| 522 |
+
input_is_latent=False,
|
| 523 |
+
noise=None,
|
| 524 |
+
randomize_noise=True,
|
| 525 |
+
):
|
| 526 |
+
if not input_is_latent:
|
| 527 |
+
styles = [self.style(s) for s in styles]
|
| 528 |
+
|
| 529 |
+
if noise is None:
|
| 530 |
+
if randomize_noise:
|
| 531 |
+
noise = [None] * self.num_layers
|
| 532 |
+
else:
|
| 533 |
+
noise = [
|
| 534 |
+
getattr(self.noises, f"noise_{i}") for i in range(self.num_layers)
|
| 535 |
+
]
|
| 536 |
+
|
| 537 |
+
if truncation < 1:
|
| 538 |
+
style_t = []
|
| 539 |
+
|
| 540 |
+
for style in styles:
|
| 541 |
+
style_t.append(
|
| 542 |
+
truncation_latent + truncation * (style - truncation_latent)
|
| 543 |
+
)
|
| 544 |
+
|
| 545 |
+
styles = style_t
|
| 546 |
+
|
| 547 |
+
if len(styles) < 2:
|
| 548 |
+
inject_index = self.n_latent
|
| 549 |
+
|
| 550 |
+
if styles[0].ndim < 3:
|
| 551 |
+
latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
|
| 552 |
+
|
| 553 |
+
else:
|
| 554 |
+
latent = styles[0]
|
| 555 |
+
|
| 556 |
+
else:
|
| 557 |
+
if inject_index is None:
|
| 558 |
+
inject_index = random.randint(1, self.n_latent - 1)
|
| 559 |
+
|
| 560 |
+
latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
|
| 561 |
+
latent2 = styles[1].unsqueeze(1).repeat(1, self.n_latent - inject_index, 1)
|
| 562 |
+
|
| 563 |
+
latent = torch.cat([latent, latent2], 1)
|
| 564 |
+
|
| 565 |
+
out = self.input(latent)
|
| 566 |
+
out = self.conv1(out, latent[:, 0], noise=noise[0])
|
| 567 |
+
|
| 568 |
+
skip = self.to_rgb1(out, latent[:, 1])
|
| 569 |
+
|
| 570 |
+
i = 1
|
| 571 |
+
for conv1, conv2, noise1, noise2, to_rgb in zip(
|
| 572 |
+
self.convs[::2], self.convs[1::2], noise[1::2], noise[2::2], self.to_rgbs
|
| 573 |
+
):
|
| 574 |
+
out = conv1(out, latent[:, i], noise=noise1)
|
| 575 |
+
out = conv2(out, latent[:, i + 1], noise=noise2)
|
| 576 |
+
skip = to_rgb(out, latent[:, i + 2], skip)
|
| 577 |
+
|
| 578 |
+
i += 2
|
| 579 |
+
|
| 580 |
+
image = skip
|
| 581 |
+
|
| 582 |
+
if return_latents:
|
| 583 |
+
return image, latent
|
| 584 |
+
|
| 585 |
+
else:
|
| 586 |
+
return image, None
|
| 587 |
+
|
| 588 |
+
|
| 589 |
+
class ConvLayer(nn.Sequential):
|
| 590 |
+
def __init__(
|
| 591 |
+
self,
|
| 592 |
+
in_channel,
|
| 593 |
+
out_channel,
|
| 594 |
+
kernel_size,
|
| 595 |
+
downsample=False,
|
| 596 |
+
blur_kernel=[1, 3, 3, 1],
|
| 597 |
+
bias=True,
|
| 598 |
+
activate=True,
|
| 599 |
+
):
|
| 600 |
+
layers = []
|
| 601 |
+
|
| 602 |
+
if downsample:
|
| 603 |
+
factor = 2
|
| 604 |
+
p = (len(blur_kernel) - factor) + (kernel_size - 1)
|
| 605 |
+
pad0 = (p + 1) // 2
|
| 606 |
+
pad1 = p // 2
|
| 607 |
+
|
| 608 |
+
layers.append(Blur(blur_kernel, pad=(pad0, pad1)))
|
| 609 |
+
|
| 610 |
+
stride = 2
|
| 611 |
+
self.padding = 0
|
| 612 |
+
|
| 613 |
+
else:
|
| 614 |
+
stride = 1
|
| 615 |
+
self.padding = kernel_size // 2
|
| 616 |
+
|
| 617 |
+
layers.append(
|
| 618 |
+
EqualConv2d(
|
| 619 |
+
in_channel,
|
| 620 |
+
out_channel,
|
| 621 |
+
kernel_size,
|
| 622 |
+
padding=self.padding,
|
| 623 |
+
stride=stride,
|
| 624 |
+
bias=bias and not activate,
|
| 625 |
+
)
|
| 626 |
+
)
|
| 627 |
+
|
| 628 |
+
if activate:
|
| 629 |
+
layers.append(FusedLeakyReLU(out_channel, bias=bias))
|
| 630 |
+
|
| 631 |
+
super().__init__(*layers)
|
| 632 |
+
|
| 633 |
+
|
| 634 |
+
class ResBlock(nn.Module):
|
| 635 |
+
def __init__(self, in_channel, out_channel, blur_kernel=[1, 3, 3, 1]):
|
| 636 |
+
super().__init__()
|
| 637 |
+
|
| 638 |
+
self.conv1 = ConvLayer(in_channel, in_channel, 3)
|
| 639 |
+
self.conv2 = ConvLayer(in_channel, out_channel, 3, downsample=True)
|
| 640 |
+
|
| 641 |
+
self.skip = ConvLayer(
|
| 642 |
+
in_channel, out_channel, 1, downsample=True, activate=False, bias=False
|
| 643 |
+
)
|
| 644 |
+
|
| 645 |
+
def forward(self, input):
|
| 646 |
+
out = self.conv1(input)
|
| 647 |
+
out = self.conv2(out)
|
| 648 |
+
|
| 649 |
+
skip = self.skip(input)
|
| 650 |
+
out = (out + skip) / math.sqrt(2)
|
| 651 |
+
|
| 652 |
+
return out
|
| 653 |
+
|
| 654 |
+
|
| 655 |
+
class Discriminator(nn.Module):
|
| 656 |
+
def __init__(self, size, channel_multiplier=2, blur_kernel=[1, 3, 3, 1]):
|
| 657 |
+
super().__init__()
|
| 658 |
+
|
| 659 |
+
channels = {
|
| 660 |
+
4: 512,
|
| 661 |
+
8: 512,
|
| 662 |
+
16: 512,
|
| 663 |
+
32: 512,
|
| 664 |
+
64: 256 * channel_multiplier,
|
| 665 |
+
128: 128 * channel_multiplier,
|
| 666 |
+
256: 64 * channel_multiplier,
|
| 667 |
+
512: 32 * channel_multiplier,
|
| 668 |
+
1024: 16 * channel_multiplier,
|
| 669 |
+
}
|
| 670 |
+
|
| 671 |
+
convs = [ConvLayer(3, channels[size], 1)]
|
| 672 |
+
|
| 673 |
+
log_size = int(math.log(size, 2))
|
| 674 |
+
|
| 675 |
+
in_channel = channels[size]
|
| 676 |
+
|
| 677 |
+
for i in range(log_size, 2, -1):
|
| 678 |
+
out_channel = channels[2 ** (i - 1)]
|
| 679 |
+
|
| 680 |
+
convs.append(ResBlock(in_channel, out_channel, blur_kernel))
|
| 681 |
+
|
| 682 |
+
in_channel = out_channel
|
| 683 |
+
|
| 684 |
+
self.convs = nn.Sequential(*convs)
|
| 685 |
+
|
| 686 |
+
self.stddev_group = 4
|
| 687 |
+
self.stddev_feat = 1
|
| 688 |
+
|
| 689 |
+
self.final_conv = ConvLayer(in_channel + 1, channels[4], 3)
|
| 690 |
+
self.final_linear = nn.Sequential(
|
| 691 |
+
EqualLinear(channels[4] * 4 * 4, channels[4], activation="fused_lrelu"),
|
| 692 |
+
EqualLinear(channels[4], 1),
|
| 693 |
+
)
|
| 694 |
+
|
| 695 |
+
def forward(self, input):
|
| 696 |
+
out = self.convs(input)
|
| 697 |
+
|
| 698 |
+
batch, channel, height, width = out.shape
|
| 699 |
+
group = min(batch, self.stddev_group)
|
| 700 |
+
stddev = out.view(
|
| 701 |
+
group, -1, self.stddev_feat, channel // self.stddev_feat, height, width
|
| 702 |
+
)
|
| 703 |
+
stddev = torch.sqrt(stddev.var(0, unbiased=False) + 1e-8)
|
| 704 |
+
stddev = stddev.mean([2, 3, 4], keepdims=True).squeeze(2)
|
| 705 |
+
stddev = stddev.repeat(group, 1, height, width)
|
| 706 |
+
out = torch.cat([out, stddev], 1)
|
| 707 |
+
|
| 708 |
+
out = self.final_conv(out)
|
| 709 |
+
|
| 710 |
+
out = out.view(batch, -1)
|
| 711 |
+
out = self.final_linear(out)
|
| 712 |
+
|
| 713 |
+
return out
|
draggan/deprecated/stylegan2/op/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .fused_act import FusedLeakyReLU, fused_leaky_relu, fused_leaky_relu_native, FusedLeakyReLU_Native
|
| 2 |
+
from .upfirdn2d import upfirdn2d, upfirdn2d_native
|
draggan/deprecated/stylegan2/op/conv2d_gradfix.py
ADDED
|
@@ -0,0 +1,229 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import contextlib
|
| 2 |
+
import warnings
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch import autograd
|
| 6 |
+
from torch.nn import functional as F
|
| 7 |
+
|
| 8 |
+
enabled = True
|
| 9 |
+
weight_gradients_disabled = False
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
@contextlib.contextmanager
|
| 13 |
+
def no_weight_gradients():
|
| 14 |
+
global weight_gradients_disabled
|
| 15 |
+
|
| 16 |
+
old = weight_gradients_disabled
|
| 17 |
+
weight_gradients_disabled = True
|
| 18 |
+
yield
|
| 19 |
+
weight_gradients_disabled = old
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1):
|
| 23 |
+
if could_use_op(input):
|
| 24 |
+
return conv2d_gradfix(
|
| 25 |
+
transpose=False,
|
| 26 |
+
weight_shape=weight.shape,
|
| 27 |
+
stride=stride,
|
| 28 |
+
padding=padding,
|
| 29 |
+
output_padding=0,
|
| 30 |
+
dilation=dilation,
|
| 31 |
+
groups=groups,
|
| 32 |
+
).apply(input, weight, bias)
|
| 33 |
+
|
| 34 |
+
return F.conv2d(
|
| 35 |
+
input=input,
|
| 36 |
+
weight=weight,
|
| 37 |
+
bias=bias,
|
| 38 |
+
stride=stride,
|
| 39 |
+
padding=padding,
|
| 40 |
+
dilation=dilation,
|
| 41 |
+
groups=groups,
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def conv_transpose2d(
|
| 46 |
+
input,
|
| 47 |
+
weight,
|
| 48 |
+
bias=None,
|
| 49 |
+
stride=1,
|
| 50 |
+
padding=0,
|
| 51 |
+
output_padding=0,
|
| 52 |
+
groups=1,
|
| 53 |
+
dilation=1,
|
| 54 |
+
):
|
| 55 |
+
if could_use_op(input):
|
| 56 |
+
return conv2d_gradfix(
|
| 57 |
+
transpose=True,
|
| 58 |
+
weight_shape=weight.shape,
|
| 59 |
+
stride=stride,
|
| 60 |
+
padding=padding,
|
| 61 |
+
output_padding=output_padding,
|
| 62 |
+
groups=groups,
|
| 63 |
+
dilation=dilation,
|
| 64 |
+
).apply(input, weight, bias)
|
| 65 |
+
|
| 66 |
+
return F.conv_transpose2d(
|
| 67 |
+
input=input,
|
| 68 |
+
weight=weight,
|
| 69 |
+
bias=bias,
|
| 70 |
+
stride=stride,
|
| 71 |
+
padding=padding,
|
| 72 |
+
output_padding=output_padding,
|
| 73 |
+
dilation=dilation,
|
| 74 |
+
groups=groups,
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def could_use_op(input):
|
| 79 |
+
return False
|
| 80 |
+
|
| 81 |
+
if (not enabled) or (not torch.backends.cudnn.enabled):
|
| 82 |
+
return False
|
| 83 |
+
|
| 84 |
+
if input.device.type != "cuda":
|
| 85 |
+
return False
|
| 86 |
+
|
| 87 |
+
if any(torch.__version__.startswith(x) for x in ["1.7.", "1.8."]):
|
| 88 |
+
return True
|
| 89 |
+
|
| 90 |
+
warnings.warn(
|
| 91 |
+
f"conv2d_gradfix not supported on PyTorch {torch.__version__}. Falling back to torch.nn.functional.conv2d()."
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
return False
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def ensure_tuple(xs, ndim):
|
| 98 |
+
xs = tuple(xs) if isinstance(xs, (tuple, list)) else (xs,) * ndim
|
| 99 |
+
|
| 100 |
+
return xs
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
conv2d_gradfix_cache = dict()
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def conv2d_gradfix(
|
| 107 |
+
transpose, weight_shape, stride, padding, output_padding, dilation, groups
|
| 108 |
+
):
|
| 109 |
+
ndim = 2
|
| 110 |
+
weight_shape = tuple(weight_shape)
|
| 111 |
+
stride = ensure_tuple(stride, ndim)
|
| 112 |
+
padding = ensure_tuple(padding, ndim)
|
| 113 |
+
output_padding = ensure_tuple(output_padding, ndim)
|
| 114 |
+
dilation = ensure_tuple(dilation, ndim)
|
| 115 |
+
|
| 116 |
+
key = (transpose, weight_shape, stride, padding, output_padding, dilation, groups)
|
| 117 |
+
if key in conv2d_gradfix_cache:
|
| 118 |
+
return conv2d_gradfix_cache[key]
|
| 119 |
+
|
| 120 |
+
common_kwargs = dict(
|
| 121 |
+
stride=stride, padding=padding, dilation=dilation, groups=groups
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
def calc_output_padding(input_shape, output_shape):
|
| 125 |
+
if transpose:
|
| 126 |
+
return [0, 0]
|
| 127 |
+
|
| 128 |
+
return [
|
| 129 |
+
input_shape[i + 2]
|
| 130 |
+
- (output_shape[i + 2] - 1) * stride[i]
|
| 131 |
+
- (1 - 2 * padding[i])
|
| 132 |
+
- dilation[i] * (weight_shape[i + 2] - 1)
|
| 133 |
+
for i in range(ndim)
|
| 134 |
+
]
|
| 135 |
+
|
| 136 |
+
class Conv2d(autograd.Function):
|
| 137 |
+
@staticmethod
|
| 138 |
+
def forward(ctx, input, weight, bias):
|
| 139 |
+
if not transpose:
|
| 140 |
+
out = F.conv2d(input=input, weight=weight, bias=bias, **common_kwargs)
|
| 141 |
+
|
| 142 |
+
else:
|
| 143 |
+
out = F.conv_transpose2d(
|
| 144 |
+
input=input,
|
| 145 |
+
weight=weight,
|
| 146 |
+
bias=bias,
|
| 147 |
+
output_padding=output_padding,
|
| 148 |
+
**common_kwargs,
|
| 149 |
+
)
|
| 150 |
+
|
| 151 |
+
ctx.save_for_backward(input, weight)
|
| 152 |
+
|
| 153 |
+
return out
|
| 154 |
+
|
| 155 |
+
@staticmethod
|
| 156 |
+
def backward(ctx, grad_output):
|
| 157 |
+
input, weight = ctx.saved_tensors
|
| 158 |
+
grad_input, grad_weight, grad_bias = None, None, None
|
| 159 |
+
|
| 160 |
+
if ctx.needs_input_grad[0]:
|
| 161 |
+
p = calc_output_padding(
|
| 162 |
+
input_shape=input.shape, output_shape=grad_output.shape
|
| 163 |
+
)
|
| 164 |
+
grad_input = conv2d_gradfix(
|
| 165 |
+
transpose=(not transpose),
|
| 166 |
+
weight_shape=weight_shape,
|
| 167 |
+
output_padding=p,
|
| 168 |
+
**common_kwargs,
|
| 169 |
+
).apply(grad_output, weight, None)
|
| 170 |
+
|
| 171 |
+
if ctx.needs_input_grad[1] and not weight_gradients_disabled:
|
| 172 |
+
grad_weight = Conv2dGradWeight.apply(grad_output, input)
|
| 173 |
+
|
| 174 |
+
if ctx.needs_input_grad[2]:
|
| 175 |
+
grad_bias = grad_output.sum((0, 2, 3))
|
| 176 |
+
|
| 177 |
+
return grad_input, grad_weight, grad_bias
|
| 178 |
+
|
| 179 |
+
class Conv2dGradWeight(autograd.Function):
|
| 180 |
+
@staticmethod
|
| 181 |
+
def forward(ctx, grad_output, input):
|
| 182 |
+
op = torch._C._jit_get_operation(
|
| 183 |
+
"aten::cudnn_convolution_backward_weight"
|
| 184 |
+
if not transpose
|
| 185 |
+
else "aten::cudnn_convolution_transpose_backward_weight"
|
| 186 |
+
)
|
| 187 |
+
flags = [
|
| 188 |
+
torch.backends.cudnn.benchmark,
|
| 189 |
+
torch.backends.cudnn.deterministic,
|
| 190 |
+
torch.backends.cudnn.allow_tf32,
|
| 191 |
+
]
|
| 192 |
+
grad_weight = op(
|
| 193 |
+
weight_shape,
|
| 194 |
+
grad_output,
|
| 195 |
+
input,
|
| 196 |
+
padding,
|
| 197 |
+
stride,
|
| 198 |
+
dilation,
|
| 199 |
+
groups,
|
| 200 |
+
*flags,
|
| 201 |
+
)
|
| 202 |
+
ctx.save_for_backward(grad_output, input)
|
| 203 |
+
|
| 204 |
+
return grad_weight
|
| 205 |
+
|
| 206 |
+
@staticmethod
|
| 207 |
+
def backward(ctx, grad_grad_weight):
|
| 208 |
+
grad_output, input = ctx.saved_tensors
|
| 209 |
+
grad_grad_output, grad_grad_input = None, None
|
| 210 |
+
|
| 211 |
+
if ctx.needs_input_grad[0]:
|
| 212 |
+
grad_grad_output = Conv2d.apply(input, grad_grad_weight, None)
|
| 213 |
+
|
| 214 |
+
if ctx.needs_input_grad[1]:
|
| 215 |
+
p = calc_output_padding(
|
| 216 |
+
input_shape=input.shape, output_shape=grad_output.shape
|
| 217 |
+
)
|
| 218 |
+
grad_grad_input = conv2d_gradfix(
|
| 219 |
+
transpose=(not transpose),
|
| 220 |
+
weight_shape=weight_shape,
|
| 221 |
+
output_padding=p,
|
| 222 |
+
**common_kwargs,
|
| 223 |
+
).apply(grad_output, grad_grad_weight, None)
|
| 224 |
+
|
| 225 |
+
return grad_grad_output, grad_grad_input
|
| 226 |
+
|
| 227 |
+
conv2d_gradfix_cache[key] = Conv2d
|
| 228 |
+
|
| 229 |
+
return Conv2d
|
draggan/deprecated/stylegan2/op/fused_act.py
ADDED
|
@@ -0,0 +1,157 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
from torch.autograd import Function
|
| 7 |
+
from torch.utils.cpp_extension import load
|
| 8 |
+
|
| 9 |
+
import warnings
|
| 10 |
+
|
| 11 |
+
module_path = os.path.dirname(os.path.abspath(__file__))
|
| 12 |
+
|
| 13 |
+
try:
|
| 14 |
+
fused = load(
|
| 15 |
+
"fused",
|
| 16 |
+
sources=[
|
| 17 |
+
os.path.join(module_path, "fused_bias_act.cpp"),
|
| 18 |
+
os.path.join(module_path, "fused_bias_act_kernel.cu"),
|
| 19 |
+
],
|
| 20 |
+
)
|
| 21 |
+
except:
|
| 22 |
+
warnings.warn(
|
| 23 |
+
f"(This is not error) Switch to native implementation"
|
| 24 |
+
)
|
| 25 |
+
|
| 26 |
+
fused = None
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class FusedLeakyReLUFunctionBackward(Function):
|
| 30 |
+
@staticmethod
|
| 31 |
+
def forward(ctx, grad_output, out, bias, negative_slope, scale):
|
| 32 |
+
ctx.save_for_backward(out)
|
| 33 |
+
ctx.negative_slope = negative_slope
|
| 34 |
+
ctx.scale = scale
|
| 35 |
+
|
| 36 |
+
empty = grad_output.new_empty(0)
|
| 37 |
+
|
| 38 |
+
grad_input = fused.fused_bias_act(
|
| 39 |
+
grad_output.contiguous(), empty, out, 3, 1, negative_slope, scale
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
dim = [0]
|
| 43 |
+
|
| 44 |
+
if grad_input.ndim > 2:
|
| 45 |
+
dim += list(range(2, grad_input.ndim))
|
| 46 |
+
|
| 47 |
+
if bias:
|
| 48 |
+
grad_bias = grad_input.sum(dim).detach()
|
| 49 |
+
|
| 50 |
+
else:
|
| 51 |
+
grad_bias = empty
|
| 52 |
+
|
| 53 |
+
return grad_input, grad_bias
|
| 54 |
+
|
| 55 |
+
@staticmethod
|
| 56 |
+
def backward(ctx, gradgrad_input, gradgrad_bias):
|
| 57 |
+
out, = ctx.saved_tensors
|
| 58 |
+
gradgrad_out = fused.fused_bias_act(
|
| 59 |
+
gradgrad_input.contiguous(),
|
| 60 |
+
gradgrad_bias,
|
| 61 |
+
out,
|
| 62 |
+
3,
|
| 63 |
+
1,
|
| 64 |
+
ctx.negative_slope,
|
| 65 |
+
ctx.scale,
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
return gradgrad_out, None, None, None, None
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
class FusedLeakyReLUFunction(Function):
|
| 72 |
+
@staticmethod
|
| 73 |
+
def forward(ctx, input, bias, negative_slope, scale):
|
| 74 |
+
empty = input.new_empty(0)
|
| 75 |
+
|
| 76 |
+
ctx.bias = bias is not None
|
| 77 |
+
|
| 78 |
+
if bias is None:
|
| 79 |
+
bias = empty
|
| 80 |
+
|
| 81 |
+
out = fused.fused_bias_act(input, bias, empty, 3, 0, negative_slope, scale)
|
| 82 |
+
ctx.save_for_backward(out)
|
| 83 |
+
ctx.negative_slope = negative_slope
|
| 84 |
+
ctx.scale = scale
|
| 85 |
+
|
| 86 |
+
return out
|
| 87 |
+
|
| 88 |
+
@staticmethod
|
| 89 |
+
def backward(ctx, grad_output):
|
| 90 |
+
out, = ctx.saved_tensors
|
| 91 |
+
|
| 92 |
+
grad_input, grad_bias = FusedLeakyReLUFunctionBackward.apply(
|
| 93 |
+
grad_output, out, ctx.bias, ctx.negative_slope, ctx.scale
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
if not ctx.bias:
|
| 97 |
+
grad_bias = None
|
| 98 |
+
|
| 99 |
+
return grad_input, grad_bias, None, None
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
class FusedLeakyReLU(nn.Module):
|
| 103 |
+
def __init__(self, channel, bias=True, negative_slope=0.2, scale=2 ** 0.5):
|
| 104 |
+
super().__init__()
|
| 105 |
+
|
| 106 |
+
if bias:
|
| 107 |
+
self.bias = nn.Parameter(torch.zeros(channel))
|
| 108 |
+
|
| 109 |
+
else:
|
| 110 |
+
self.bias = None
|
| 111 |
+
|
| 112 |
+
self.negative_slope = negative_slope
|
| 113 |
+
self.scale = scale
|
| 114 |
+
|
| 115 |
+
def forward(self, input):
|
| 116 |
+
return fused_leaky_relu(input, self.bias, self.negative_slope, self.scale)
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
def fused_leaky_relu(input, bias=None, negative_slope=0.2, scale=2 ** 0.5):
|
| 120 |
+
if input.device.type == "cpu":
|
| 121 |
+
if bias is not None:
|
| 122 |
+
rest_dim = [1] * (input.ndim - bias.ndim - 1)
|
| 123 |
+
return (
|
| 124 |
+
F.leaky_relu(
|
| 125 |
+
input + bias.view(1, bias.shape[0], *rest_dim), negative_slope=0.2
|
| 126 |
+
)
|
| 127 |
+
* scale
|
| 128 |
+
)
|
| 129 |
+
|
| 130 |
+
else:
|
| 131 |
+
return F.leaky_relu(input, negative_slope=0.2) * scale
|
| 132 |
+
|
| 133 |
+
else:
|
| 134 |
+
return FusedLeakyReLUFunction.apply(
|
| 135 |
+
input.contiguous(), bias, negative_slope, scale
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
class FusedLeakyReLU_Native(nn.Module):
|
| 140 |
+
def __init__(self, channel, bias=True, negative_slope=0.2, scale=2 ** 0.5):
|
| 141 |
+
super().__init__()
|
| 142 |
+
|
| 143 |
+
if bias:
|
| 144 |
+
self.bias = nn.Parameter(torch.zeros(channel))
|
| 145 |
+
|
| 146 |
+
else:
|
| 147 |
+
self.bias = None
|
| 148 |
+
|
| 149 |
+
self.negative_slope = negative_slope
|
| 150 |
+
self.scale = scale
|
| 151 |
+
|
| 152 |
+
def forward(self, input):
|
| 153 |
+
return fused_leaky_relu_native(input, self.bias, self.negative_slope, self.scale)
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def fused_leaky_relu_native(input, bias, negative_slope=0.2, scale=2 ** 0.5):
|
| 157 |
+
return scale * F.leaky_relu(input + bias.view((1, -1) + (1,) * (len(input.shape) - 2)), negative_slope=negative_slope)
|
draggan/deprecated/stylegan2/op/fused_bias_act.cpp
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
#include <ATen/ATen.h>
|
| 3 |
+
#include <torch/extension.h>
|
| 4 |
+
|
| 5 |
+
torch::Tensor fused_bias_act_op(const torch::Tensor &input,
|
| 6 |
+
const torch::Tensor &bias,
|
| 7 |
+
const torch::Tensor &refer, int act, int grad,
|
| 8 |
+
float alpha, float scale);
|
| 9 |
+
|
| 10 |
+
#define CHECK_CUDA(x) \
|
| 11 |
+
TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
|
| 12 |
+
#define CHECK_CONTIGUOUS(x) \
|
| 13 |
+
TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
|
| 14 |
+
#define CHECK_INPUT(x) \
|
| 15 |
+
CHECK_CUDA(x); \
|
| 16 |
+
CHECK_CONTIGUOUS(x)
|
| 17 |
+
|
| 18 |
+
torch::Tensor fused_bias_act(const torch::Tensor &input,
|
| 19 |
+
const torch::Tensor &bias,
|
| 20 |
+
const torch::Tensor &refer, int act, int grad,
|
| 21 |
+
float alpha, float scale) {
|
| 22 |
+
CHECK_INPUT(input);
|
| 23 |
+
CHECK_INPUT(bias);
|
| 24 |
+
|
| 25 |
+
at::DeviceGuard guard(input.device());
|
| 26 |
+
|
| 27 |
+
return fused_bias_act_op(input, bias, refer, act, grad, alpha, scale);
|
| 28 |
+
}
|
| 29 |
+
|
| 30 |
+
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
|
| 31 |
+
m.def("fused_bias_act", &fused_bias_act, "fused bias act (CUDA)");
|
| 32 |
+
}
|
draggan/deprecated/stylegan2/op/fused_bias_act_kernel.cu
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Copyright (c) 2019, NVIDIA Corporation. All rights reserved.
|
| 2 |
+
//
|
| 3 |
+
// This work is made available under the Nvidia Source Code License-NC.
|
| 4 |
+
// To view a copy of this license, visit
|
| 5 |
+
// https://nvlabs.github.io/stylegan2/license.html
|
| 6 |
+
|
| 7 |
+
#include <torch/types.h>
|
| 8 |
+
|
| 9 |
+
#include <ATen/ATen.h>
|
| 10 |
+
#include <ATen/AccumulateType.h>
|
| 11 |
+
#include <ATen/cuda/CUDAApplyUtils.cuh>
|
| 12 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
#include <cuda.h>
|
| 16 |
+
#include <cuda_runtime.h>
|
| 17 |
+
|
| 18 |
+
template <typename scalar_t>
|
| 19 |
+
static __global__ void
|
| 20 |
+
fused_bias_act_kernel(scalar_t *out, const scalar_t *p_x, const scalar_t *p_b,
|
| 21 |
+
const scalar_t *p_ref, int act, int grad, scalar_t alpha,
|
| 22 |
+
scalar_t scale, int loop_x, int size_x, int step_b,
|
| 23 |
+
int size_b, int use_bias, int use_ref) {
|
| 24 |
+
int xi = blockIdx.x * loop_x * blockDim.x + threadIdx.x;
|
| 25 |
+
|
| 26 |
+
scalar_t zero = 0.0;
|
| 27 |
+
|
| 28 |
+
for (int loop_idx = 0; loop_idx < loop_x && xi < size_x;
|
| 29 |
+
loop_idx++, xi += blockDim.x) {
|
| 30 |
+
scalar_t x = p_x[xi];
|
| 31 |
+
|
| 32 |
+
if (use_bias) {
|
| 33 |
+
x += p_b[(xi / step_b) % size_b];
|
| 34 |
+
}
|
| 35 |
+
|
| 36 |
+
scalar_t ref = use_ref ? p_ref[xi] : zero;
|
| 37 |
+
|
| 38 |
+
scalar_t y;
|
| 39 |
+
|
| 40 |
+
switch (act * 10 + grad) {
|
| 41 |
+
default:
|
| 42 |
+
case 10:
|
| 43 |
+
y = x;
|
| 44 |
+
break;
|
| 45 |
+
case 11:
|
| 46 |
+
y = x;
|
| 47 |
+
break;
|
| 48 |
+
case 12:
|
| 49 |
+
y = 0.0;
|
| 50 |
+
break;
|
| 51 |
+
|
| 52 |
+
case 30:
|
| 53 |
+
y = (x > 0.0) ? x : x * alpha;
|
| 54 |
+
break;
|
| 55 |
+
case 31:
|
| 56 |
+
y = (ref > 0.0) ? x : x * alpha;
|
| 57 |
+
break;
|
| 58 |
+
case 32:
|
| 59 |
+
y = 0.0;
|
| 60 |
+
break;
|
| 61 |
+
}
|
| 62 |
+
|
| 63 |
+
out[xi] = y * scale;
|
| 64 |
+
}
|
| 65 |
+
}
|
| 66 |
+
|
| 67 |
+
torch::Tensor fused_bias_act_op(const torch::Tensor &input,
|
| 68 |
+
const torch::Tensor &bias,
|
| 69 |
+
const torch::Tensor &refer, int act, int grad,
|
| 70 |
+
float alpha, float scale) {
|
| 71 |
+
int curDevice = -1;
|
| 72 |
+
cudaGetDevice(&curDevice);
|
| 73 |
+
cudaStream_t stream = at::cuda::getCurrentCUDAStream();
|
| 74 |
+
|
| 75 |
+
auto x = input.contiguous();
|
| 76 |
+
auto b = bias.contiguous();
|
| 77 |
+
auto ref = refer.contiguous();
|
| 78 |
+
|
| 79 |
+
int use_bias = b.numel() ? 1 : 0;
|
| 80 |
+
int use_ref = ref.numel() ? 1 : 0;
|
| 81 |
+
|
| 82 |
+
int size_x = x.numel();
|
| 83 |
+
int size_b = b.numel();
|
| 84 |
+
int step_b = 1;
|
| 85 |
+
|
| 86 |
+
for (int i = 1 + 1; i < x.dim(); i++) {
|
| 87 |
+
step_b *= x.size(i);
|
| 88 |
+
}
|
| 89 |
+
|
| 90 |
+
int loop_x = 4;
|
| 91 |
+
int block_size = 4 * 32;
|
| 92 |
+
int grid_size = (size_x - 1) / (loop_x * block_size) + 1;
|
| 93 |
+
|
| 94 |
+
auto y = torch::empty_like(x);
|
| 95 |
+
|
| 96 |
+
AT_DISPATCH_FLOATING_TYPES_AND_HALF(
|
| 97 |
+
x.scalar_type(), "fused_bias_act_kernel", [&] {
|
| 98 |
+
fused_bias_act_kernel<scalar_t><<<grid_size, block_size, 0, stream>>>(
|
| 99 |
+
y.data_ptr<scalar_t>(), x.data_ptr<scalar_t>(),
|
| 100 |
+
b.data_ptr<scalar_t>(), ref.data_ptr<scalar_t>(), act, grad, alpha,
|
| 101 |
+
scale, loop_x, size_x, step_b, size_b, use_bias, use_ref);
|
| 102 |
+
});
|
| 103 |
+
|
| 104 |
+
return y;
|
| 105 |
+
}
|
draggan/deprecated/stylegan2/op/upfirdn2d.cpp
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#include <ATen/ATen.h>
|
| 2 |
+
#include <torch/extension.h>
|
| 3 |
+
|
| 4 |
+
torch::Tensor upfirdn2d_op(const torch::Tensor &input,
|
| 5 |
+
const torch::Tensor &kernel, int up_x, int up_y,
|
| 6 |
+
int down_x, int down_y, int pad_x0, int pad_x1,
|
| 7 |
+
int pad_y0, int pad_y1);
|
| 8 |
+
|
| 9 |
+
#define CHECK_CUDA(x) \
|
| 10 |
+
TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
|
| 11 |
+
#define CHECK_CONTIGUOUS(x) \
|
| 12 |
+
TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
|
| 13 |
+
#define CHECK_INPUT(x) \
|
| 14 |
+
CHECK_CUDA(x); \
|
| 15 |
+
CHECK_CONTIGUOUS(x)
|
| 16 |
+
|
| 17 |
+
torch::Tensor upfirdn2d(const torch::Tensor &input, const torch::Tensor &kernel,
|
| 18 |
+
int up_x, int up_y, int down_x, int down_y, int pad_x0,
|
| 19 |
+
int pad_x1, int pad_y0, int pad_y1) {
|
| 20 |
+
CHECK_INPUT(input);
|
| 21 |
+
CHECK_INPUT(kernel);
|
| 22 |
+
|
| 23 |
+
at::DeviceGuard guard(input.device());
|
| 24 |
+
|
| 25 |
+
return upfirdn2d_op(input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1,
|
| 26 |
+
pad_y0, pad_y1);
|
| 27 |
+
}
|
| 28 |
+
|
| 29 |
+
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
|
| 30 |
+
m.def("upfirdn2d", &upfirdn2d, "upfirdn2d (CUDA)");
|
| 31 |
+
}
|
draggan/deprecated/stylegan2/op/upfirdn2d.py
ADDED
|
@@ -0,0 +1,232 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import abc
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
from torch.autograd import Function
|
| 7 |
+
from torch.utils.cpp_extension import load
|
| 8 |
+
import warnings
|
| 9 |
+
|
| 10 |
+
module_path = os.path.dirname(os.path.abspath(__file__))
|
| 11 |
+
|
| 12 |
+
try:
|
| 13 |
+
upfirdn2d_op = load(
|
| 14 |
+
"upfirdn2d",
|
| 15 |
+
sources=[
|
| 16 |
+
os.path.join(module_path, "upfirdn2d.cpp"),
|
| 17 |
+
os.path.join(module_path, "upfirdn2d_kernel.cu"),
|
| 18 |
+
],
|
| 19 |
+
)
|
| 20 |
+
except:
|
| 21 |
+
warnings.warn(
|
| 22 |
+
f"(This is not error) Switch to native implementation"
|
| 23 |
+
)
|
| 24 |
+
|
| 25 |
+
upfirdn2d_op = None
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class UpFirDn2dBackward(Function):
|
| 29 |
+
@staticmethod
|
| 30 |
+
def forward(
|
| 31 |
+
ctx, grad_output, kernel, grad_kernel, up, down, pad, g_pad, in_size, out_size
|
| 32 |
+
):
|
| 33 |
+
|
| 34 |
+
up_x, up_y = up
|
| 35 |
+
down_x, down_y = down
|
| 36 |
+
g_pad_x0, g_pad_x1, g_pad_y0, g_pad_y1 = g_pad
|
| 37 |
+
|
| 38 |
+
grad_output = grad_output.reshape(-1, out_size[0], out_size[1], 1)
|
| 39 |
+
|
| 40 |
+
grad_input = upfirdn2d_op.upfirdn2d(
|
| 41 |
+
grad_output,
|
| 42 |
+
grad_kernel,
|
| 43 |
+
down_x,
|
| 44 |
+
down_y,
|
| 45 |
+
up_x,
|
| 46 |
+
up_y,
|
| 47 |
+
g_pad_x0,
|
| 48 |
+
g_pad_x1,
|
| 49 |
+
g_pad_y0,
|
| 50 |
+
g_pad_y1,
|
| 51 |
+
)
|
| 52 |
+
grad_input = grad_input.view(in_size[0], in_size[1], in_size[2], in_size[3])
|
| 53 |
+
|
| 54 |
+
ctx.save_for_backward(kernel)
|
| 55 |
+
|
| 56 |
+
pad_x0, pad_x1, pad_y0, pad_y1 = pad
|
| 57 |
+
|
| 58 |
+
ctx.up_x = up_x
|
| 59 |
+
ctx.up_y = up_y
|
| 60 |
+
ctx.down_x = down_x
|
| 61 |
+
ctx.down_y = down_y
|
| 62 |
+
ctx.pad_x0 = pad_x0
|
| 63 |
+
ctx.pad_x1 = pad_x1
|
| 64 |
+
ctx.pad_y0 = pad_y0
|
| 65 |
+
ctx.pad_y1 = pad_y1
|
| 66 |
+
ctx.in_size = in_size
|
| 67 |
+
ctx.out_size = out_size
|
| 68 |
+
|
| 69 |
+
return grad_input
|
| 70 |
+
|
| 71 |
+
@staticmethod
|
| 72 |
+
def backward(ctx, gradgrad_input):
|
| 73 |
+
kernel, = ctx.saved_tensors
|
| 74 |
+
|
| 75 |
+
gradgrad_input = gradgrad_input.reshape(-1, ctx.in_size[2], ctx.in_size[3], 1)
|
| 76 |
+
|
| 77 |
+
gradgrad_out = upfirdn2d_op.upfirdn2d(
|
| 78 |
+
gradgrad_input,
|
| 79 |
+
kernel,
|
| 80 |
+
ctx.up_x,
|
| 81 |
+
ctx.up_y,
|
| 82 |
+
ctx.down_x,
|
| 83 |
+
ctx.down_y,
|
| 84 |
+
ctx.pad_x0,
|
| 85 |
+
ctx.pad_x1,
|
| 86 |
+
ctx.pad_y0,
|
| 87 |
+
ctx.pad_y1,
|
| 88 |
+
)
|
| 89 |
+
# gradgrad_out = gradgrad_out.view(ctx.in_size[0], ctx.out_size[0], ctx.out_size[1], ctx.in_size[3])
|
| 90 |
+
gradgrad_out = gradgrad_out.view(
|
| 91 |
+
ctx.in_size[0], ctx.in_size[1], ctx.out_size[0], ctx.out_size[1]
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
return gradgrad_out, None, None, None, None, None, None, None, None
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
class UpFirDn2d(Function):
|
| 98 |
+
@staticmethod
|
| 99 |
+
def forward(ctx, input, kernel, up, down, pad):
|
| 100 |
+
up_x, up_y = up
|
| 101 |
+
down_x, down_y = down
|
| 102 |
+
pad_x0, pad_x1, pad_y0, pad_y1 = pad
|
| 103 |
+
|
| 104 |
+
kernel_h, kernel_w = kernel.shape
|
| 105 |
+
batch, channel, in_h, in_w = input.shape
|
| 106 |
+
ctx.in_size = input.shape
|
| 107 |
+
|
| 108 |
+
input = input.reshape(-1, in_h, in_w, 1)
|
| 109 |
+
|
| 110 |
+
ctx.save_for_backward(kernel, torch.flip(kernel, [0, 1]))
|
| 111 |
+
|
| 112 |
+
out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h + down_y) // down_y
|
| 113 |
+
out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w + down_x) // down_x
|
| 114 |
+
ctx.out_size = (out_h, out_w)
|
| 115 |
+
|
| 116 |
+
ctx.up = (up_x, up_y)
|
| 117 |
+
ctx.down = (down_x, down_y)
|
| 118 |
+
ctx.pad = (pad_x0, pad_x1, pad_y0, pad_y1)
|
| 119 |
+
|
| 120 |
+
g_pad_x0 = kernel_w - pad_x0 - 1
|
| 121 |
+
g_pad_y0 = kernel_h - pad_y0 - 1
|
| 122 |
+
g_pad_x1 = in_w * up_x - out_w * down_x + pad_x0 - up_x + 1
|
| 123 |
+
g_pad_y1 = in_h * up_y - out_h * down_y + pad_y0 - up_y + 1
|
| 124 |
+
|
| 125 |
+
ctx.g_pad = (g_pad_x0, g_pad_x1, g_pad_y0, g_pad_y1)
|
| 126 |
+
|
| 127 |
+
out = upfirdn2d_op.upfirdn2d(
|
| 128 |
+
input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1
|
| 129 |
+
)
|
| 130 |
+
# out = out.view(major, out_h, out_w, minor)
|
| 131 |
+
out = out.view(-1, channel, out_h, out_w)
|
| 132 |
+
|
| 133 |
+
return out
|
| 134 |
+
|
| 135 |
+
@staticmethod
|
| 136 |
+
def backward(ctx, grad_output):
|
| 137 |
+
kernel, grad_kernel = ctx.saved_tensors
|
| 138 |
+
|
| 139 |
+
grad_input = None
|
| 140 |
+
|
| 141 |
+
if ctx.needs_input_grad[0]:
|
| 142 |
+
grad_input = UpFirDn2dBackward.apply(
|
| 143 |
+
grad_output,
|
| 144 |
+
kernel,
|
| 145 |
+
grad_kernel,
|
| 146 |
+
ctx.up,
|
| 147 |
+
ctx.down,
|
| 148 |
+
ctx.pad,
|
| 149 |
+
ctx.g_pad,
|
| 150 |
+
ctx.in_size,
|
| 151 |
+
ctx.out_size,
|
| 152 |
+
)
|
| 153 |
+
|
| 154 |
+
return grad_input, None, None, None, None
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def upfirdn2d(input, kernel, up=1, down=1, pad=(0, 0)):
|
| 158 |
+
if not isinstance(up, abc.Iterable):
|
| 159 |
+
up = (up, up)
|
| 160 |
+
|
| 161 |
+
if not isinstance(down, abc.Iterable):
|
| 162 |
+
down = (down, down)
|
| 163 |
+
|
| 164 |
+
if len(pad) == 2:
|
| 165 |
+
pad = (pad[0], pad[1], pad[0], pad[1])
|
| 166 |
+
|
| 167 |
+
if input.device.type == "cpu":
|
| 168 |
+
out = _upfirdn2d_native(input, kernel, *up, *down, *pad)
|
| 169 |
+
|
| 170 |
+
else:
|
| 171 |
+
out = UpFirDn2d.apply(input, kernel, up, down, pad)
|
| 172 |
+
|
| 173 |
+
return out
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
def upfirdn2d_native(input, kernel, up=1, down=1, pad=(0, 0)):
|
| 177 |
+
if not isinstance(up, abc.Iterable):
|
| 178 |
+
up = (up, up)
|
| 179 |
+
|
| 180 |
+
if not isinstance(down, abc.Iterable):
|
| 181 |
+
down = (down, down)
|
| 182 |
+
|
| 183 |
+
if len(pad) == 2:
|
| 184 |
+
pad = (pad[0], pad[1], pad[0], pad[1])
|
| 185 |
+
|
| 186 |
+
out = _upfirdn2d_native(input, kernel, *up, *down, *pad)
|
| 187 |
+
|
| 188 |
+
return out
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
def _upfirdn2d_native(
|
| 192 |
+
input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1
|
| 193 |
+
):
|
| 194 |
+
_, channel, in_h, in_w = input.shape
|
| 195 |
+
input = input.reshape(-1, in_h, in_w, 1)
|
| 196 |
+
|
| 197 |
+
_, in_h, in_w, minor = input.shape
|
| 198 |
+
kernel_h, kernel_w = kernel.shape
|
| 199 |
+
|
| 200 |
+
out = input.view(-1, in_h, 1, in_w, 1, minor)
|
| 201 |
+
out = F.pad(out, [0, 0, 0, up_x - 1, 0, 0, 0, up_y - 1])
|
| 202 |
+
out = out.view(-1, in_h * up_y, in_w * up_x, minor)
|
| 203 |
+
|
| 204 |
+
out = F.pad(
|
| 205 |
+
out, [0, 0, max(pad_x0, 0), max(pad_x1, 0), max(pad_y0, 0), max(pad_y1, 0)]
|
| 206 |
+
)
|
| 207 |
+
out = out[
|
| 208 |
+
:,
|
| 209 |
+
max(-pad_y0, 0): out.shape[1] - max(-pad_y1, 0),
|
| 210 |
+
max(-pad_x0, 0): out.shape[2] - max(-pad_x1, 0),
|
| 211 |
+
:,
|
| 212 |
+
]
|
| 213 |
+
|
| 214 |
+
out = out.permute(0, 3, 1, 2)
|
| 215 |
+
out = out.reshape(
|
| 216 |
+
[-1, 1, in_h * up_y + pad_y0 + pad_y1, in_w * up_x + pad_x0 + pad_x1]
|
| 217 |
+
)
|
| 218 |
+
w = torch.flip(kernel, [0, 1]).view(1, 1, kernel_h, kernel_w)
|
| 219 |
+
out = F.conv2d(out, w)
|
| 220 |
+
out = out.reshape(
|
| 221 |
+
-1,
|
| 222 |
+
minor,
|
| 223 |
+
in_h * up_y + pad_y0 + pad_y1 - kernel_h + 1,
|
| 224 |
+
in_w * up_x + pad_x0 + pad_x1 - kernel_w + 1,
|
| 225 |
+
)
|
| 226 |
+
out = out.permute(0, 2, 3, 1)
|
| 227 |
+
out = out[:, ::down_y, ::down_x, :]
|
| 228 |
+
|
| 229 |
+
out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h + down_y) // down_y
|
| 230 |
+
out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w + down_x) // down_x
|
| 231 |
+
|
| 232 |
+
return out.view(-1, channel, out_h, out_w)
|
draggan/deprecated/stylegan2/op/upfirdn2d_kernel.cu
ADDED
|
@@ -0,0 +1,369 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Copyright (c) 2019, NVIDIA Corporation. All rights reserved.
|
| 2 |
+
//
|
| 3 |
+
// This work is made available under the Nvidia Source Code License-NC.
|
| 4 |
+
// To view a copy of this license, visit
|
| 5 |
+
// https://nvlabs.github.io/stylegan2/license.html
|
| 6 |
+
|
| 7 |
+
#include <torch/types.h>
|
| 8 |
+
|
| 9 |
+
#include <ATen/ATen.h>
|
| 10 |
+
#include <ATen/AccumulateType.h>
|
| 11 |
+
#include <ATen/cuda/CUDAApplyUtils.cuh>
|
| 12 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 13 |
+
|
| 14 |
+
#include <cuda.h>
|
| 15 |
+
#include <cuda_runtime.h>
|
| 16 |
+
|
| 17 |
+
static __host__ __device__ __forceinline__ int floor_div(int a, int b) {
|
| 18 |
+
int c = a / b;
|
| 19 |
+
|
| 20 |
+
if (c * b > a) {
|
| 21 |
+
c--;
|
| 22 |
+
}
|
| 23 |
+
|
| 24 |
+
return c;
|
| 25 |
+
}
|
| 26 |
+
|
| 27 |
+
struct UpFirDn2DKernelParams {
|
| 28 |
+
int up_x;
|
| 29 |
+
int up_y;
|
| 30 |
+
int down_x;
|
| 31 |
+
int down_y;
|
| 32 |
+
int pad_x0;
|
| 33 |
+
int pad_x1;
|
| 34 |
+
int pad_y0;
|
| 35 |
+
int pad_y1;
|
| 36 |
+
|
| 37 |
+
int major_dim;
|
| 38 |
+
int in_h;
|
| 39 |
+
int in_w;
|
| 40 |
+
int minor_dim;
|
| 41 |
+
int kernel_h;
|
| 42 |
+
int kernel_w;
|
| 43 |
+
int out_h;
|
| 44 |
+
int out_w;
|
| 45 |
+
int loop_major;
|
| 46 |
+
int loop_x;
|
| 47 |
+
};
|
| 48 |
+
|
| 49 |
+
template <typename scalar_t>
|
| 50 |
+
__global__ void upfirdn2d_kernel_large(scalar_t *out, const scalar_t *input,
|
| 51 |
+
const scalar_t *kernel,
|
| 52 |
+
const UpFirDn2DKernelParams p) {
|
| 53 |
+
int minor_idx = blockIdx.x * blockDim.x + threadIdx.x;
|
| 54 |
+
int out_y = minor_idx / p.minor_dim;
|
| 55 |
+
minor_idx -= out_y * p.minor_dim;
|
| 56 |
+
int out_x_base = blockIdx.y * p.loop_x * blockDim.y + threadIdx.y;
|
| 57 |
+
int major_idx_base = blockIdx.z * p.loop_major;
|
| 58 |
+
|
| 59 |
+
if (out_x_base >= p.out_w || out_y >= p.out_h ||
|
| 60 |
+
major_idx_base >= p.major_dim) {
|
| 61 |
+
return;
|
| 62 |
+
}
|
| 63 |
+
|
| 64 |
+
int mid_y = out_y * p.down_y + p.up_y - 1 - p.pad_y0;
|
| 65 |
+
int in_y = min(max(floor_div(mid_y, p.up_y), 0), p.in_h);
|
| 66 |
+
int h = min(max(floor_div(mid_y + p.kernel_h, p.up_y), 0), p.in_h) - in_y;
|
| 67 |
+
int kernel_y = mid_y + p.kernel_h - (in_y + 1) * p.up_y;
|
| 68 |
+
|
| 69 |
+
for (int loop_major = 0, major_idx = major_idx_base;
|
| 70 |
+
loop_major < p.loop_major && major_idx < p.major_dim;
|
| 71 |
+
loop_major++, major_idx++) {
|
| 72 |
+
for (int loop_x = 0, out_x = out_x_base;
|
| 73 |
+
loop_x < p.loop_x && out_x < p.out_w; loop_x++, out_x += blockDim.y) {
|
| 74 |
+
int mid_x = out_x * p.down_x + p.up_x - 1 - p.pad_x0;
|
| 75 |
+
int in_x = min(max(floor_div(mid_x, p.up_x), 0), p.in_w);
|
| 76 |
+
int w = min(max(floor_div(mid_x + p.kernel_w, p.up_x), 0), p.in_w) - in_x;
|
| 77 |
+
int kernel_x = mid_x + p.kernel_w - (in_x + 1) * p.up_x;
|
| 78 |
+
|
| 79 |
+
const scalar_t *x_p =
|
| 80 |
+
&input[((major_idx * p.in_h + in_y) * p.in_w + in_x) * p.minor_dim +
|
| 81 |
+
minor_idx];
|
| 82 |
+
const scalar_t *k_p = &kernel[kernel_y * p.kernel_w + kernel_x];
|
| 83 |
+
int x_px = p.minor_dim;
|
| 84 |
+
int k_px = -p.up_x;
|
| 85 |
+
int x_py = p.in_w * p.minor_dim;
|
| 86 |
+
int k_py = -p.up_y * p.kernel_w;
|
| 87 |
+
|
| 88 |
+
scalar_t v = 0.0f;
|
| 89 |
+
|
| 90 |
+
for (int y = 0; y < h; y++) {
|
| 91 |
+
for (int x = 0; x < w; x++) {
|
| 92 |
+
v += static_cast<scalar_t>(*x_p) * static_cast<scalar_t>(*k_p);
|
| 93 |
+
x_p += x_px;
|
| 94 |
+
k_p += k_px;
|
| 95 |
+
}
|
| 96 |
+
|
| 97 |
+
x_p += x_py - w * x_px;
|
| 98 |
+
k_p += k_py - w * k_px;
|
| 99 |
+
}
|
| 100 |
+
|
| 101 |
+
out[((major_idx * p.out_h + out_y) * p.out_w + out_x) * p.minor_dim +
|
| 102 |
+
minor_idx] = v;
|
| 103 |
+
}
|
| 104 |
+
}
|
| 105 |
+
}
|
| 106 |
+
|
| 107 |
+
template <typename scalar_t, int up_x, int up_y, int down_x, int down_y,
|
| 108 |
+
int kernel_h, int kernel_w, int tile_out_h, int tile_out_w>
|
| 109 |
+
__global__ void upfirdn2d_kernel(scalar_t *out, const scalar_t *input,
|
| 110 |
+
const scalar_t *kernel,
|
| 111 |
+
const UpFirDn2DKernelParams p) {
|
| 112 |
+
const int tile_in_h = ((tile_out_h - 1) * down_y + kernel_h - 1) / up_y + 1;
|
| 113 |
+
const int tile_in_w = ((tile_out_w - 1) * down_x + kernel_w - 1) / up_x + 1;
|
| 114 |
+
|
| 115 |
+
__shared__ volatile float sk[kernel_h][kernel_w];
|
| 116 |
+
__shared__ volatile float sx[tile_in_h][tile_in_w];
|
| 117 |
+
|
| 118 |
+
int minor_idx = blockIdx.x;
|
| 119 |
+
int tile_out_y = minor_idx / p.minor_dim;
|
| 120 |
+
minor_idx -= tile_out_y * p.minor_dim;
|
| 121 |
+
tile_out_y *= tile_out_h;
|
| 122 |
+
int tile_out_x_base = blockIdx.y * p.loop_x * tile_out_w;
|
| 123 |
+
int major_idx_base = blockIdx.z * p.loop_major;
|
| 124 |
+
|
| 125 |
+
if (tile_out_x_base >= p.out_w | tile_out_y >= p.out_h |
|
| 126 |
+
major_idx_base >= p.major_dim) {
|
| 127 |
+
return;
|
| 128 |
+
}
|
| 129 |
+
|
| 130 |
+
for (int tap_idx = threadIdx.x; tap_idx < kernel_h * kernel_w;
|
| 131 |
+
tap_idx += blockDim.x) {
|
| 132 |
+
int ky = tap_idx / kernel_w;
|
| 133 |
+
int kx = tap_idx - ky * kernel_w;
|
| 134 |
+
scalar_t v = 0.0;
|
| 135 |
+
|
| 136 |
+
if (kx < p.kernel_w & ky < p.kernel_h) {
|
| 137 |
+
v = kernel[(p.kernel_h - 1 - ky) * p.kernel_w + (p.kernel_w - 1 - kx)];
|
| 138 |
+
}
|
| 139 |
+
|
| 140 |
+
sk[ky][kx] = v;
|
| 141 |
+
}
|
| 142 |
+
|
| 143 |
+
for (int loop_major = 0, major_idx = major_idx_base;
|
| 144 |
+
loop_major < p.loop_major & major_idx < p.major_dim;
|
| 145 |
+
loop_major++, major_idx++) {
|
| 146 |
+
for (int loop_x = 0, tile_out_x = tile_out_x_base;
|
| 147 |
+
loop_x < p.loop_x & tile_out_x < p.out_w;
|
| 148 |
+
loop_x++, tile_out_x += tile_out_w) {
|
| 149 |
+
int tile_mid_x = tile_out_x * down_x + up_x - 1 - p.pad_x0;
|
| 150 |
+
int tile_mid_y = tile_out_y * down_y + up_y - 1 - p.pad_y0;
|
| 151 |
+
int tile_in_x = floor_div(tile_mid_x, up_x);
|
| 152 |
+
int tile_in_y = floor_div(tile_mid_y, up_y);
|
| 153 |
+
|
| 154 |
+
__syncthreads();
|
| 155 |
+
|
| 156 |
+
for (int in_idx = threadIdx.x; in_idx < tile_in_h * tile_in_w;
|
| 157 |
+
in_idx += blockDim.x) {
|
| 158 |
+
int rel_in_y = in_idx / tile_in_w;
|
| 159 |
+
int rel_in_x = in_idx - rel_in_y * tile_in_w;
|
| 160 |
+
int in_x = rel_in_x + tile_in_x;
|
| 161 |
+
int in_y = rel_in_y + tile_in_y;
|
| 162 |
+
|
| 163 |
+
scalar_t v = 0.0;
|
| 164 |
+
|
| 165 |
+
if (in_x >= 0 & in_y >= 0 & in_x < p.in_w & in_y < p.in_h) {
|
| 166 |
+
v = input[((major_idx * p.in_h + in_y) * p.in_w + in_x) *
|
| 167 |
+
p.minor_dim +
|
| 168 |
+
minor_idx];
|
| 169 |
+
}
|
| 170 |
+
|
| 171 |
+
sx[rel_in_y][rel_in_x] = v;
|
| 172 |
+
}
|
| 173 |
+
|
| 174 |
+
__syncthreads();
|
| 175 |
+
for (int out_idx = threadIdx.x; out_idx < tile_out_h * tile_out_w;
|
| 176 |
+
out_idx += blockDim.x) {
|
| 177 |
+
int rel_out_y = out_idx / tile_out_w;
|
| 178 |
+
int rel_out_x = out_idx - rel_out_y * tile_out_w;
|
| 179 |
+
int out_x = rel_out_x + tile_out_x;
|
| 180 |
+
int out_y = rel_out_y + tile_out_y;
|
| 181 |
+
|
| 182 |
+
int mid_x = tile_mid_x + rel_out_x * down_x;
|
| 183 |
+
int mid_y = tile_mid_y + rel_out_y * down_y;
|
| 184 |
+
int in_x = floor_div(mid_x, up_x);
|
| 185 |
+
int in_y = floor_div(mid_y, up_y);
|
| 186 |
+
int rel_in_x = in_x - tile_in_x;
|
| 187 |
+
int rel_in_y = in_y - tile_in_y;
|
| 188 |
+
int kernel_x = (in_x + 1) * up_x - mid_x - 1;
|
| 189 |
+
int kernel_y = (in_y + 1) * up_y - mid_y - 1;
|
| 190 |
+
|
| 191 |
+
scalar_t v = 0.0;
|
| 192 |
+
|
| 193 |
+
#pragma unroll
|
| 194 |
+
for (int y = 0; y < kernel_h / up_y; y++)
|
| 195 |
+
#pragma unroll
|
| 196 |
+
for (int x = 0; x < kernel_w / up_x; x++)
|
| 197 |
+
v += sx[rel_in_y + y][rel_in_x + x] *
|
| 198 |
+
sk[kernel_y + y * up_y][kernel_x + x * up_x];
|
| 199 |
+
|
| 200 |
+
if (out_x < p.out_w & out_y < p.out_h) {
|
| 201 |
+
out[((major_idx * p.out_h + out_y) * p.out_w + out_x) * p.minor_dim +
|
| 202 |
+
minor_idx] = v;
|
| 203 |
+
}
|
| 204 |
+
}
|
| 205 |
+
}
|
| 206 |
+
}
|
| 207 |
+
}
|
| 208 |
+
|
| 209 |
+
torch::Tensor upfirdn2d_op(const torch::Tensor &input,
|
| 210 |
+
const torch::Tensor &kernel, int up_x, int up_y,
|
| 211 |
+
int down_x, int down_y, int pad_x0, int pad_x1,
|
| 212 |
+
int pad_y0, int pad_y1) {
|
| 213 |
+
int curDevice = -1;
|
| 214 |
+
cudaGetDevice(&curDevice);
|
| 215 |
+
cudaStream_t stream = at::cuda::getCurrentCUDAStream();
|
| 216 |
+
|
| 217 |
+
UpFirDn2DKernelParams p;
|
| 218 |
+
|
| 219 |
+
auto x = input.contiguous();
|
| 220 |
+
auto k = kernel.contiguous();
|
| 221 |
+
|
| 222 |
+
p.major_dim = x.size(0);
|
| 223 |
+
p.in_h = x.size(1);
|
| 224 |
+
p.in_w = x.size(2);
|
| 225 |
+
p.minor_dim = x.size(3);
|
| 226 |
+
p.kernel_h = k.size(0);
|
| 227 |
+
p.kernel_w = k.size(1);
|
| 228 |
+
p.up_x = up_x;
|
| 229 |
+
p.up_y = up_y;
|
| 230 |
+
p.down_x = down_x;
|
| 231 |
+
p.down_y = down_y;
|
| 232 |
+
p.pad_x0 = pad_x0;
|
| 233 |
+
p.pad_x1 = pad_x1;
|
| 234 |
+
p.pad_y0 = pad_y0;
|
| 235 |
+
p.pad_y1 = pad_y1;
|
| 236 |
+
|
| 237 |
+
p.out_h = (p.in_h * p.up_y + p.pad_y0 + p.pad_y1 - p.kernel_h + p.down_y) /
|
| 238 |
+
p.down_y;
|
| 239 |
+
p.out_w = (p.in_w * p.up_x + p.pad_x0 + p.pad_x1 - p.kernel_w + p.down_x) /
|
| 240 |
+
p.down_x;
|
| 241 |
+
|
| 242 |
+
auto out =
|
| 243 |
+
at::empty({p.major_dim, p.out_h, p.out_w, p.minor_dim}, x.options());
|
| 244 |
+
|
| 245 |
+
int mode = -1;
|
| 246 |
+
|
| 247 |
+
int tile_out_h = -1;
|
| 248 |
+
int tile_out_w = -1;
|
| 249 |
+
|
| 250 |
+
if (p.up_x == 1 && p.up_y == 1 && p.down_x == 1 && p.down_y == 1 &&
|
| 251 |
+
p.kernel_h <= 4 && p.kernel_w <= 4) {
|
| 252 |
+
mode = 1;
|
| 253 |
+
tile_out_h = 16;
|
| 254 |
+
tile_out_w = 64;
|
| 255 |
+
}
|
| 256 |
+
|
| 257 |
+
if (p.up_x == 1 && p.up_y == 1 && p.down_x == 1 && p.down_y == 1 &&
|
| 258 |
+
p.kernel_h <= 3 && p.kernel_w <= 3) {
|
| 259 |
+
mode = 2;
|
| 260 |
+
tile_out_h = 16;
|
| 261 |
+
tile_out_w = 64;
|
| 262 |
+
}
|
| 263 |
+
|
| 264 |
+
if (p.up_x == 2 && p.up_y == 2 && p.down_x == 1 && p.down_y == 1 &&
|
| 265 |
+
p.kernel_h <= 4 && p.kernel_w <= 4) {
|
| 266 |
+
mode = 3;
|
| 267 |
+
tile_out_h = 16;
|
| 268 |
+
tile_out_w = 64;
|
| 269 |
+
}
|
| 270 |
+
|
| 271 |
+
if (p.up_x == 2 && p.up_y == 2 && p.down_x == 1 && p.down_y == 1 &&
|
| 272 |
+
p.kernel_h <= 2 && p.kernel_w <= 2) {
|
| 273 |
+
mode = 4;
|
| 274 |
+
tile_out_h = 16;
|
| 275 |
+
tile_out_w = 64;
|
| 276 |
+
}
|
| 277 |
+
|
| 278 |
+
if (p.up_x == 1 && p.up_y == 1 && p.down_x == 2 && p.down_y == 2 &&
|
| 279 |
+
p.kernel_h <= 4 && p.kernel_w <= 4) {
|
| 280 |
+
mode = 5;
|
| 281 |
+
tile_out_h = 8;
|
| 282 |
+
tile_out_w = 32;
|
| 283 |
+
}
|
| 284 |
+
|
| 285 |
+
if (p.up_x == 1 && p.up_y == 1 && p.down_x == 2 && p.down_y == 2 &&
|
| 286 |
+
p.kernel_h <= 2 && p.kernel_w <= 2) {
|
| 287 |
+
mode = 6;
|
| 288 |
+
tile_out_h = 8;
|
| 289 |
+
tile_out_w = 32;
|
| 290 |
+
}
|
| 291 |
+
|
| 292 |
+
dim3 block_size;
|
| 293 |
+
dim3 grid_size;
|
| 294 |
+
|
| 295 |
+
if (tile_out_h > 0 && tile_out_w > 0) {
|
| 296 |
+
p.loop_major = (p.major_dim - 1) / 16384 + 1;
|
| 297 |
+
p.loop_x = 1;
|
| 298 |
+
block_size = dim3(32 * 8, 1, 1);
|
| 299 |
+
grid_size = dim3(((p.out_h - 1) / tile_out_h + 1) * p.minor_dim,
|
| 300 |
+
(p.out_w - 1) / (p.loop_x * tile_out_w) + 1,
|
| 301 |
+
(p.major_dim - 1) / p.loop_major + 1);
|
| 302 |
+
} else {
|
| 303 |
+
p.loop_major = (p.major_dim - 1) / 16384 + 1;
|
| 304 |
+
p.loop_x = 4;
|
| 305 |
+
block_size = dim3(4, 32, 1);
|
| 306 |
+
grid_size = dim3((p.out_h * p.minor_dim - 1) / block_size.x + 1,
|
| 307 |
+
(p.out_w - 1) / (p.loop_x * block_size.y) + 1,
|
| 308 |
+
(p.major_dim - 1) / p.loop_major + 1);
|
| 309 |
+
}
|
| 310 |
+
|
| 311 |
+
AT_DISPATCH_FLOATING_TYPES_AND_HALF(x.scalar_type(), "upfirdn2d_cuda", [&] {
|
| 312 |
+
switch (mode) {
|
| 313 |
+
case 1:
|
| 314 |
+
upfirdn2d_kernel<scalar_t, 1, 1, 1, 1, 4, 4, 16, 64>
|
| 315 |
+
<<<grid_size, block_size, 0, stream>>>(out.data_ptr<scalar_t>(),
|
| 316 |
+
x.data_ptr<scalar_t>(),
|
| 317 |
+
k.data_ptr<scalar_t>(), p);
|
| 318 |
+
|
| 319 |
+
break;
|
| 320 |
+
|
| 321 |
+
case 2:
|
| 322 |
+
upfirdn2d_kernel<scalar_t, 1, 1, 1, 1, 3, 3, 16, 64>
|
| 323 |
+
<<<grid_size, block_size, 0, stream>>>(out.data_ptr<scalar_t>(),
|
| 324 |
+
x.data_ptr<scalar_t>(),
|
| 325 |
+
k.data_ptr<scalar_t>(), p);
|
| 326 |
+
|
| 327 |
+
break;
|
| 328 |
+
|
| 329 |
+
case 3:
|
| 330 |
+
upfirdn2d_kernel<scalar_t, 2, 2, 1, 1, 4, 4, 16, 64>
|
| 331 |
+
<<<grid_size, block_size, 0, stream>>>(out.data_ptr<scalar_t>(),
|
| 332 |
+
x.data_ptr<scalar_t>(),
|
| 333 |
+
k.data_ptr<scalar_t>(), p);
|
| 334 |
+
|
| 335 |
+
break;
|
| 336 |
+
|
| 337 |
+
case 4:
|
| 338 |
+
upfirdn2d_kernel<scalar_t, 2, 2, 1, 1, 2, 2, 16, 64>
|
| 339 |
+
<<<grid_size, block_size, 0, stream>>>(out.data_ptr<scalar_t>(),
|
| 340 |
+
x.data_ptr<scalar_t>(),
|
| 341 |
+
k.data_ptr<scalar_t>(), p);
|
| 342 |
+
|
| 343 |
+
break;
|
| 344 |
+
|
| 345 |
+
case 5:
|
| 346 |
+
upfirdn2d_kernel<scalar_t, 1, 1, 2, 2, 4, 4, 8, 32>
|
| 347 |
+
<<<grid_size, block_size, 0, stream>>>(out.data_ptr<scalar_t>(),
|
| 348 |
+
x.data_ptr<scalar_t>(),
|
| 349 |
+
k.data_ptr<scalar_t>(), p);
|
| 350 |
+
|
| 351 |
+
break;
|
| 352 |
+
|
| 353 |
+
case 6:
|
| 354 |
+
upfirdn2d_kernel<scalar_t, 1, 1, 2, 2, 4, 4, 8, 32>
|
| 355 |
+
<<<grid_size, block_size, 0, stream>>>(out.data_ptr<scalar_t>(),
|
| 356 |
+
x.data_ptr<scalar_t>(),
|
| 357 |
+
k.data_ptr<scalar_t>(), p);
|
| 358 |
+
|
| 359 |
+
break;
|
| 360 |
+
|
| 361 |
+
default:
|
| 362 |
+
upfirdn2d_kernel_large<scalar_t><<<grid_size, block_size, 0, stream>>>(
|
| 363 |
+
out.data_ptr<scalar_t>(), x.data_ptr<scalar_t>(),
|
| 364 |
+
k.data_ptr<scalar_t>(), p);
|
| 365 |
+
}
|
| 366 |
+
});
|
| 367 |
+
|
| 368 |
+
return out;
|
| 369 |
+
}
|
draggan/deprecated/utils.py
ADDED
|
@@ -0,0 +1,216 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/skimai/DragGAN
|
| 2 |
+
|
| 3 |
+
import copy
|
| 4 |
+
import math
|
| 5 |
+
import os
|
| 6 |
+
import urllib.request
|
| 7 |
+
from typing import List, Optional, Tuple
|
| 8 |
+
|
| 9 |
+
import numpy as np
|
| 10 |
+
import PIL
|
| 11 |
+
import PIL.Image
|
| 12 |
+
import PIL.ImageDraw
|
| 13 |
+
import torch
|
| 14 |
+
import torch.optim
|
| 15 |
+
from tqdm import tqdm
|
| 16 |
+
|
| 17 |
+
BASE_DIR = os.environ.get(
|
| 18 |
+
'DRAGGAN_HOME',
|
| 19 |
+
os.path.join(os.path.expanduser('~'), 'draggan', 'checkpoints')
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class DownloadProgressBar(tqdm):
|
| 24 |
+
def update_to(self, b=1, bsize=1, tsize=None):
|
| 25 |
+
if tsize is not None:
|
| 26 |
+
self.total = tsize
|
| 27 |
+
self.update(b * bsize - self.n)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def download_url(url, output_path):
|
| 31 |
+
with DownloadProgressBar(unit='B', unit_scale=True,
|
| 32 |
+
miniters=1, desc=url.split('/')[-1]) as t:
|
| 33 |
+
urllib.request.urlretrieve(url, filename=output_path, reporthook=t.update_to)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def get_path(base_path):
|
| 37 |
+
save_path = os.path.join(BASE_DIR, base_path)
|
| 38 |
+
if not os.path.exists(save_path):
|
| 39 |
+
url = f"https://huggingface.co/aaronb/StyleGAN2/resolve/main/{base_path}"
|
| 40 |
+
print(f'{base_path} not found')
|
| 41 |
+
print('Try to download from huggingface: ', url)
|
| 42 |
+
os.makedirs(os.path.dirname(save_path), exist_ok=True)
|
| 43 |
+
download_url(url, save_path)
|
| 44 |
+
print('Downloaded to ', save_path)
|
| 45 |
+
return save_path
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def tensor_to_PIL(img: torch.Tensor) -> PIL.Image.Image:
|
| 49 |
+
"""
|
| 50 |
+
Converts a tensor image to a PIL Image.
|
| 51 |
+
|
| 52 |
+
Args:
|
| 53 |
+
img (torch.Tensor): The tensor image of shape [batch_size, num_channels, height, width].
|
| 54 |
+
|
| 55 |
+
Returns:
|
| 56 |
+
A PIL Image object.
|
| 57 |
+
"""
|
| 58 |
+
img = (img.permute(0, 2, 3, 1) * 127.5 + 128).clamp(0, 255).to(torch.uint8)
|
| 59 |
+
return PIL.Image.fromarray(img[0].cpu().numpy(), "RGB")
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def get_ellipse_coords(
|
| 63 |
+
point: Tuple[int, int], radius: int = 5
|
| 64 |
+
) -> Tuple[int, int, int, int]:
|
| 65 |
+
"""
|
| 66 |
+
Returns the coordinates of an ellipse centered at the given point.
|
| 67 |
+
|
| 68 |
+
Args:
|
| 69 |
+
point (Tuple[int, int]): The center point of the ellipse.
|
| 70 |
+
radius (int): The radius of the ellipse.
|
| 71 |
+
|
| 72 |
+
Returns:
|
| 73 |
+
A tuple containing the coordinates of the ellipse in the format (x_min, y_min, x_max, y_max).
|
| 74 |
+
"""
|
| 75 |
+
center = point
|
| 76 |
+
return (
|
| 77 |
+
center[0] - radius,
|
| 78 |
+
center[1] - radius,
|
| 79 |
+
center[0] + radius,
|
| 80 |
+
center[1] + radius,
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
def draw_handle_target_points(
|
| 85 |
+
img: PIL.Image.Image,
|
| 86 |
+
handle_points: List[Tuple[int, int]],
|
| 87 |
+
target_points: List[Tuple[int, int]],
|
| 88 |
+
radius: int = 5):
|
| 89 |
+
"""
|
| 90 |
+
Draws handle and target points with arrow pointing towards the target point.
|
| 91 |
+
|
| 92 |
+
Args:
|
| 93 |
+
img (PIL.Image.Image): The image to draw on.
|
| 94 |
+
handle_points (List[Tuple[int, int]]): A list of handle [x,y] points.
|
| 95 |
+
target_points (List[Tuple[int, int]]): A list of target [x,y] points.
|
| 96 |
+
radius (int): The radius of the handle and target points.
|
| 97 |
+
"""
|
| 98 |
+
if not isinstance(img, PIL.Image.Image):
|
| 99 |
+
img = PIL.Image.fromarray(img)
|
| 100 |
+
|
| 101 |
+
if len(handle_points) == len(target_points) + 1:
|
| 102 |
+
target_points = copy.deepcopy(target_points) + [None]
|
| 103 |
+
|
| 104 |
+
draw = PIL.ImageDraw.Draw(img)
|
| 105 |
+
for handle_point, target_point in zip(handle_points, target_points):
|
| 106 |
+
handle_point = [handle_point[1], handle_point[0]]
|
| 107 |
+
# Draw the handle point
|
| 108 |
+
handle_coords = get_ellipse_coords(handle_point, radius)
|
| 109 |
+
draw.ellipse(handle_coords, fill="red")
|
| 110 |
+
|
| 111 |
+
if target_point is not None:
|
| 112 |
+
target_point = [target_point[1], target_point[0]]
|
| 113 |
+
# Draw the target point
|
| 114 |
+
target_coords = get_ellipse_coords(target_point, radius)
|
| 115 |
+
draw.ellipse(target_coords, fill="blue")
|
| 116 |
+
|
| 117 |
+
# Draw arrow head
|
| 118 |
+
arrow_head_length = 10.0
|
| 119 |
+
|
| 120 |
+
# Compute the direction vector of the line
|
| 121 |
+
dx = target_point[0] - handle_point[0]
|
| 122 |
+
dy = target_point[1] - handle_point[1]
|
| 123 |
+
angle = math.atan2(dy, dx)
|
| 124 |
+
|
| 125 |
+
# Shorten the target point by the length of the arrowhead
|
| 126 |
+
shortened_target_point = (
|
| 127 |
+
target_point[0] - arrow_head_length * math.cos(angle),
|
| 128 |
+
target_point[1] - arrow_head_length * math.sin(angle),
|
| 129 |
+
)
|
| 130 |
+
|
| 131 |
+
# Draw the arrow (main line)
|
| 132 |
+
draw.line([tuple(handle_point), shortened_target_point], fill='white', width=3)
|
| 133 |
+
|
| 134 |
+
# Compute the points for the arrowhead
|
| 135 |
+
arrow_point1 = (
|
| 136 |
+
target_point[0] - arrow_head_length * math.cos(angle - math.pi / 6),
|
| 137 |
+
target_point[1] - arrow_head_length * math.sin(angle - math.pi / 6),
|
| 138 |
+
)
|
| 139 |
+
|
| 140 |
+
arrow_point2 = (
|
| 141 |
+
target_point[0] - arrow_head_length * math.cos(angle + math.pi / 6),
|
| 142 |
+
target_point[1] - arrow_head_length * math.sin(angle + math.pi / 6),
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
# Draw the arrowhead
|
| 146 |
+
draw.polygon([tuple(target_point), arrow_point1, arrow_point2], fill='white')
|
| 147 |
+
return np.array(img)
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
def create_circular_mask(
|
| 151 |
+
h: int,
|
| 152 |
+
w: int,
|
| 153 |
+
center: Optional[Tuple[int, int]] = None,
|
| 154 |
+
radius: Optional[int] = None,
|
| 155 |
+
) -> torch.Tensor:
|
| 156 |
+
"""
|
| 157 |
+
Create a circular mask tensor.
|
| 158 |
+
|
| 159 |
+
Args:
|
| 160 |
+
h (int): The height of the mask tensor.
|
| 161 |
+
w (int): The width of the mask tensor.
|
| 162 |
+
center (Optional[Tuple[int, int]]): The center of the circle as a tuple (y, x). If None, the middle of the image is used.
|
| 163 |
+
radius (Optional[int]): The radius of the circle. If None, the smallest distance between the center and image walls is used.
|
| 164 |
+
|
| 165 |
+
Returns:
|
| 166 |
+
A boolean tensor of shape [h, w] representing the circular mask.
|
| 167 |
+
"""
|
| 168 |
+
if center is None: # use the middle of the image
|
| 169 |
+
center = (int(h / 2), int(w / 2))
|
| 170 |
+
if radius is None: # use the smallest distance between the center and image walls
|
| 171 |
+
radius = min(center[0], center[1], h - center[0], w - center[1])
|
| 172 |
+
|
| 173 |
+
Y, X = np.ogrid[:h, :w]
|
| 174 |
+
dist_from_center = np.sqrt((Y - center[0]) ** 2 + (X - center[1]) ** 2)
|
| 175 |
+
|
| 176 |
+
mask = dist_from_center <= radius
|
| 177 |
+
mask = torch.from_numpy(mask).bool()
|
| 178 |
+
return mask
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
def create_square_mask(
|
| 182 |
+
height: int, width: int, center: list, radius: int
|
| 183 |
+
) -> torch.Tensor:
|
| 184 |
+
"""Create a square mask tensor.
|
| 185 |
+
|
| 186 |
+
Args:
|
| 187 |
+
height (int): The height of the mask.
|
| 188 |
+
width (int): The width of the mask.
|
| 189 |
+
center (list): The center of the square mask as a list of two integers. Order [y,x]
|
| 190 |
+
radius (int): The radius of the square mask.
|
| 191 |
+
|
| 192 |
+
Returns:
|
| 193 |
+
torch.Tensor: The square mask tensor of shape (1, 1, height, width).
|
| 194 |
+
|
| 195 |
+
Raises:
|
| 196 |
+
ValueError: If the center or radius is invalid.
|
| 197 |
+
"""
|
| 198 |
+
if not isinstance(center, list) or len(center) != 2:
|
| 199 |
+
raise ValueError("center must be a list of two integers")
|
| 200 |
+
if not isinstance(radius, int) or radius <= 0:
|
| 201 |
+
raise ValueError("radius must be a positive integer")
|
| 202 |
+
if (
|
| 203 |
+
center[0] < radius
|
| 204 |
+
or center[0] >= height - radius
|
| 205 |
+
or center[1] < radius
|
| 206 |
+
or center[1] >= width - radius
|
| 207 |
+
):
|
| 208 |
+
raise ValueError("center and radius must be within the bounds of the mask")
|
| 209 |
+
|
| 210 |
+
mask = torch.zeros((height, width), dtype=torch.float32)
|
| 211 |
+
x1 = int(center[1]) - radius
|
| 212 |
+
x2 = int(center[1]) + radius
|
| 213 |
+
y1 = int(center[0]) - radius
|
| 214 |
+
y2 = int(center[0]) + radius
|
| 215 |
+
mask[y1: y2 + 1, x1: x2 + 1] = 1.0
|
| 216 |
+
return mask.bool()
|
draggan/deprecated/web.py
ADDED
|
@@ -0,0 +1,319 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import gradio as gr
|
| 3 |
+
import torch
|
| 4 |
+
import numpy as np
|
| 5 |
+
import imageio
|
| 6 |
+
from PIL import Image
|
| 7 |
+
import uuid
|
| 8 |
+
|
| 9 |
+
from .api import drag_gan, stylegan2
|
| 10 |
+
from .stylegan2.inversion import inverse_image
|
| 11 |
+
from . import utils
|
| 12 |
+
|
| 13 |
+
device = 'cuda'
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
SIZE_TO_CLICK_SIZE = {
|
| 17 |
+
1024: 8,
|
| 18 |
+
512: 5,
|
| 19 |
+
256: 2
|
| 20 |
+
}
|
| 21 |
+
|
| 22 |
+
CKPT_SIZE = {
|
| 23 |
+
'stylegan2-ffhq-config-f.pt': 1024,
|
| 24 |
+
'stylegan2-cat-config-f.pt': 256,
|
| 25 |
+
'stylegan2-church-config-f.pt': 256,
|
| 26 |
+
'stylegan2-horse-config-f.pt': 256,
|
| 27 |
+
'ada/ffhq.pt': 1024,
|
| 28 |
+
'ada/afhqcat.pt': 512,
|
| 29 |
+
'ada/afhqdog.pt': 512,
|
| 30 |
+
'ada/afhqwild.pt': 512,
|
| 31 |
+
'ada/brecahad.pt': 512,
|
| 32 |
+
'ada/metfaces.pt': 512,
|
| 33 |
+
'human/v2_512.pt': 512,
|
| 34 |
+
'human/v2_1024.pt': 1024,
|
| 35 |
+
'self_distill/bicycles_256.pt': 256,
|
| 36 |
+
'self_distill/dogs_1024.pt': 1024,
|
| 37 |
+
'self_distill/elephants_512.pt': 512,
|
| 38 |
+
'self_distill/giraffes_512.pt': 512,
|
| 39 |
+
'self_distill/horses_256.pt': 256,
|
| 40 |
+
'self_distill/lions_512.pt': 512,
|
| 41 |
+
'self_distill/parrots_512.pt': 512,
|
| 42 |
+
}
|
| 43 |
+
|
| 44 |
+
DEFAULT_CKPT = 'self_distill/lions_512.pt'
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
class ModelWrapper:
|
| 48 |
+
def __init__(self, **kwargs):
|
| 49 |
+
self.g_ema = stylegan2(**kwargs).to(device)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def to_image(tensor):
|
| 53 |
+
tensor = tensor.squeeze(0).permute(1, 2, 0)
|
| 54 |
+
arr = tensor.detach().cpu().numpy()
|
| 55 |
+
arr = (arr - arr.min()) / (arr.max() - arr.min())
|
| 56 |
+
arr = arr * 255
|
| 57 |
+
return arr.astype('uint8')
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def add_points_to_image(image, points, size=5):
|
| 61 |
+
image = utils.draw_handle_target_points(image, points['handle'], points['target'], size)
|
| 62 |
+
return image
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def on_click(image, target_point, points, size, evt: gr.SelectData):
|
| 66 |
+
if target_point:
|
| 67 |
+
points['target'].append([evt.index[1], evt.index[0]])
|
| 68 |
+
image = add_points_to_image(image, points, size=SIZE_TO_CLICK_SIZE[size])
|
| 69 |
+
return image, not target_point
|
| 70 |
+
points['handle'].append([evt.index[1], evt.index[0]])
|
| 71 |
+
image = add_points_to_image(image, points, size=SIZE_TO_CLICK_SIZE[size])
|
| 72 |
+
return image, not target_point
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def on_drag(model, points, max_iters, state, size, mask, lr_box):
|
| 76 |
+
if len(points['handle']) == 0:
|
| 77 |
+
raise gr.Error('You must select at least one handle point and target point.')
|
| 78 |
+
if len(points['handle']) != len(points['target']):
|
| 79 |
+
raise gr.Error('You have uncompleted handle points, try to selct a target point or undo the handle point.')
|
| 80 |
+
max_iters = int(max_iters)
|
| 81 |
+
latent = state['latent']
|
| 82 |
+
noise = state['noise']
|
| 83 |
+
F = state['F']
|
| 84 |
+
|
| 85 |
+
handle_points = [torch.tensor(p, device=device).float() for p in points['handle']]
|
| 86 |
+
target_points = [torch.tensor(p, device=device).float() for p in points['target']]
|
| 87 |
+
|
| 88 |
+
if mask.get('mask') is not None:
|
| 89 |
+
mask = Image.fromarray(mask['mask']).convert('L')
|
| 90 |
+
mask = np.array(mask) == 255
|
| 91 |
+
|
| 92 |
+
mask = torch.from_numpy(mask).float().to(device)
|
| 93 |
+
mask = mask.unsqueeze(0).unsqueeze(0)
|
| 94 |
+
else:
|
| 95 |
+
mask = None
|
| 96 |
+
|
| 97 |
+
step = 0
|
| 98 |
+
for sample2, latent, F, handle_points in drag_gan(model.g_ema, latent, noise, F,
|
| 99 |
+
handle_points, target_points, mask,
|
| 100 |
+
max_iters=max_iters, lr=lr_box):
|
| 101 |
+
image = to_image(sample2)
|
| 102 |
+
|
| 103 |
+
state['F'] = F
|
| 104 |
+
state['latent'] = latent
|
| 105 |
+
state['sample'] = sample2
|
| 106 |
+
points['handle'] = [p.cpu().numpy().astype('int') for p in handle_points]
|
| 107 |
+
image = add_points_to_image(image, points, size=SIZE_TO_CLICK_SIZE[size])
|
| 108 |
+
|
| 109 |
+
state['history'].append(image)
|
| 110 |
+
step += 1
|
| 111 |
+
yield image, state, step
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
def on_reset(points, image, state):
|
| 115 |
+
return {'target': [], 'handle': []}, to_image(state['sample']), False
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def on_undo(points, image, state, size):
|
| 119 |
+
image = to_image(state['sample'])
|
| 120 |
+
|
| 121 |
+
if len(points['target']) < len(points['handle']):
|
| 122 |
+
points['handle'] = points['handle'][:-1]
|
| 123 |
+
else:
|
| 124 |
+
points['handle'] = points['handle'][:-1]
|
| 125 |
+
points['target'] = points['target'][:-1]
|
| 126 |
+
|
| 127 |
+
image = add_points_to_image(image, points, size=SIZE_TO_CLICK_SIZE[size])
|
| 128 |
+
return points, image, False
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def on_change_model(selected, model):
|
| 132 |
+
size = CKPT_SIZE[selected]
|
| 133 |
+
model = ModelWrapper(size=size, ckpt=selected)
|
| 134 |
+
g_ema = model.g_ema
|
| 135 |
+
sample_z = torch.randn([1, 512], device=device)
|
| 136 |
+
latent, noise = g_ema.prepare([sample_z])
|
| 137 |
+
sample, F = g_ema.generate(latent, noise)
|
| 138 |
+
|
| 139 |
+
state = {
|
| 140 |
+
'latent': latent,
|
| 141 |
+
'noise': noise,
|
| 142 |
+
'F': F,
|
| 143 |
+
'sample': sample,
|
| 144 |
+
'history': []
|
| 145 |
+
}
|
| 146 |
+
return model, state, to_image(sample), to_image(sample), size
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
def on_new_image(model):
|
| 150 |
+
g_ema = model.g_ema
|
| 151 |
+
sample_z = torch.randn([1, 512], device=device)
|
| 152 |
+
latent, noise = g_ema.prepare([sample_z])
|
| 153 |
+
sample, F = g_ema.generate(latent, noise)
|
| 154 |
+
|
| 155 |
+
state = {
|
| 156 |
+
'latent': latent,
|
| 157 |
+
'noise': noise,
|
| 158 |
+
'F': F,
|
| 159 |
+
'sample': sample,
|
| 160 |
+
'history': []
|
| 161 |
+
}
|
| 162 |
+
points = {'target': [], 'handle': []}
|
| 163 |
+
target_point = False
|
| 164 |
+
return to_image(sample), to_image(sample), state, points, target_point
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def on_max_iter_change(max_iters):
|
| 168 |
+
return gr.update(maximum=max_iters)
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
def on_save_files(image, state):
|
| 172 |
+
os.makedirs('draggan_tmp', exist_ok=True)
|
| 173 |
+
image_name = f'draggan_tmp/image_{uuid.uuid4()}.png'
|
| 174 |
+
video_name = f'draggan_tmp/video_{uuid.uuid4()}.mp4'
|
| 175 |
+
imageio.imsave(image_name, image)
|
| 176 |
+
imageio.mimsave(video_name, state['history'])
|
| 177 |
+
return [image_name, video_name]
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
def on_show_save():
|
| 181 |
+
return gr.update(visible=True)
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
def on_image_change(model, image_size, image):
|
| 185 |
+
image = Image.fromarray(image)
|
| 186 |
+
result = inverse_image(
|
| 187 |
+
model.g_ema,
|
| 188 |
+
image,
|
| 189 |
+
image_size=image_size
|
| 190 |
+
)
|
| 191 |
+
result['history'] = []
|
| 192 |
+
image = to_image(result['sample'])
|
| 193 |
+
points = {'target': [], 'handle': []}
|
| 194 |
+
target_point = False
|
| 195 |
+
return image, image, result, points, target_point
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
def on_mask_change(mask):
|
| 199 |
+
return mask['image']
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
def on_select_mask_tab(state):
|
| 203 |
+
img = to_image(state['sample'])
|
| 204 |
+
return img
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
def main():
|
| 208 |
+
torch.cuda.manual_seed(25)
|
| 209 |
+
|
| 210 |
+
with gr.Blocks() as demo:
|
| 211 |
+
wrapped_model = ModelWrapper(ckpt=DEFAULT_CKPT, size=CKPT_SIZE[DEFAULT_CKPT])
|
| 212 |
+
model = gr.State(wrapped_model)
|
| 213 |
+
sample_z = torch.randn([1, 512], device=device)
|
| 214 |
+
latent, noise = wrapped_model.g_ema.prepare([sample_z])
|
| 215 |
+
sample, F = wrapped_model.g_ema.generate(latent, noise)
|
| 216 |
+
|
| 217 |
+
gr.Markdown(
|
| 218 |
+
"""
|
| 219 |
+
# DragGAN
|
| 220 |
+
|
| 221 |
+
Unofficial implementation of [Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold](https://vcai.mpi-inf.mpg.de/projects/DragGAN/)
|
| 222 |
+
|
| 223 |
+
[Our Implementation](https://github.com/Zeqiang-Lai/DragGAN) | [Official Implementation](https://github.com/XingangPan/DragGAN)
|
| 224 |
+
|
| 225 |
+
## Tutorial
|
| 226 |
+
|
| 227 |
+
1. (Optional) Draw a mask indicate the movable region.
|
| 228 |
+
2. Setup a least one pair of handle point and target point.
|
| 229 |
+
3. Click "Drag it".
|
| 230 |
+
|
| 231 |
+
## Hints
|
| 232 |
+
|
| 233 |
+
- Handle points (Blue): the point you want to drag.
|
| 234 |
+
- Target points (Red): the destination you want to drag towards to.
|
| 235 |
+
|
| 236 |
+
## Primary Support of Custom Image.
|
| 237 |
+
|
| 238 |
+
- We now support dragging user uploaded image by GAN inversion.
|
| 239 |
+
- **Please upload your image at `Setup Handle Points` pannel.** Upload it from `Draw a Mask` would cause errors for now.
|
| 240 |
+
- Due to the limitation of GAN inversion,
|
| 241 |
+
- You might wait roughly 1 minute to see the GAN version of the uploaded image.
|
| 242 |
+
- The shown image might be slightly difference from the uploaded one.
|
| 243 |
+
- It could also fail to invert the uploaded image and generate very poor results.
|
| 244 |
+
- Idealy, you should choose the closest model of the uploaded image. For example, choose `stylegan2-ffhq-config-f.pt` for human face. `stylegan2-cat-config-f.pt` for cat.
|
| 245 |
+
|
| 246 |
+
> Please fire an issue if you have encounted any problem. Also don't forgot to give a star to the [Official Repo](https://github.com/XingangPan/DragGAN), [our project](https://github.com/Zeqiang-Lai/DragGAN) could not exist without it.
|
| 247 |
+
""",
|
| 248 |
+
)
|
| 249 |
+
state = gr.State({
|
| 250 |
+
'latent': latent,
|
| 251 |
+
'noise': noise,
|
| 252 |
+
'F': F,
|
| 253 |
+
'sample': sample,
|
| 254 |
+
'history': []
|
| 255 |
+
})
|
| 256 |
+
points = gr.State({'target': [], 'handle': []})
|
| 257 |
+
size = gr.State(CKPT_SIZE[DEFAULT_CKPT])
|
| 258 |
+
target_point = gr.State(False)
|
| 259 |
+
|
| 260 |
+
with gr.Row():
|
| 261 |
+
with gr.Column(scale=0.3):
|
| 262 |
+
with gr.Accordion("Model"):
|
| 263 |
+
model_dropdown = gr.Dropdown(choices=list(CKPT_SIZE.keys()), value=DEFAULT_CKPT,
|
| 264 |
+
label='StyleGAN2 model')
|
| 265 |
+
max_iters = gr.Slider(1, 500, 20, step=1, label='Max Iterations')
|
| 266 |
+
new_btn = gr.Button('New Image')
|
| 267 |
+
with gr.Accordion('Drag'):
|
| 268 |
+
with gr.Row():
|
| 269 |
+
lr_box = gr.Number(value=2e-3, label='Learning Rate')
|
| 270 |
+
|
| 271 |
+
with gr.Row():
|
| 272 |
+
with gr.Column(min_width=100):
|
| 273 |
+
reset_btn = gr.Button('Reset All')
|
| 274 |
+
with gr.Column(min_width=100):
|
| 275 |
+
undo_btn = gr.Button('Undo Last')
|
| 276 |
+
with gr.Row():
|
| 277 |
+
btn = gr.Button('Drag it', variant='primary')
|
| 278 |
+
|
| 279 |
+
with gr.Accordion('Save', visible=False) as save_panel:
|
| 280 |
+
files = gr.Files(value=[])
|
| 281 |
+
|
| 282 |
+
progress = gr.Slider(value=0, maximum=20, label='Progress', interactive=False)
|
| 283 |
+
|
| 284 |
+
with gr.Column():
|
| 285 |
+
with gr.Tabs():
|
| 286 |
+
img = to_image(sample)
|
| 287 |
+
with gr.Tab('Setup Handle Points', id='input'):
|
| 288 |
+
image = gr.Image(img).style(height=512, width=512)
|
| 289 |
+
with gr.Tab('Draw a Mask', id='mask') as masktab:
|
| 290 |
+
mask = gr.ImageMask(img, label='Mask').style(height=512, width=512)
|
| 291 |
+
|
| 292 |
+
image.select(on_click, [image, target_point, points, size], [image, target_point])
|
| 293 |
+
image.upload(on_image_change, [model, size, image], [image, mask, state, points, target_point])
|
| 294 |
+
mask.upload(on_mask_change, [mask], [image])
|
| 295 |
+
btn.click(on_drag, inputs=[model, points, max_iters, state, size, mask, lr_box], outputs=[image, state, progress]).then(
|
| 296 |
+
on_show_save, outputs=save_panel).then(
|
| 297 |
+
on_save_files, inputs=[image, state], outputs=[files]
|
| 298 |
+
)
|
| 299 |
+
reset_btn.click(on_reset, inputs=[points, image, state], outputs=[points, image, target_point])
|
| 300 |
+
undo_btn.click(on_undo, inputs=[points, image, state, size], outputs=[points, image, target_point])
|
| 301 |
+
model_dropdown.change(on_change_model, inputs=[model_dropdown, model], outputs=[model, state, image, mask, size])
|
| 302 |
+
new_btn.click(on_new_image, inputs=[model], outputs=[image, mask, state, points, target_point])
|
| 303 |
+
max_iters.change(on_max_iter_change, inputs=max_iters, outputs=progress)
|
| 304 |
+
masktab.select(lambda: gr.update(value=None), outputs=[mask]).then(on_select_mask_tab, inputs=[state], outputs=[mask])
|
| 305 |
+
return demo
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
if __name__ == '__main__':
|
| 309 |
+
import argparse
|
| 310 |
+
parser = argparse.ArgumentParser()
|
| 311 |
+
parser.add_argument('--device', default='cuda')
|
| 312 |
+
parser.add_argument('--share', action='store_true')
|
| 313 |
+
parser.add_argument('-p', '--port', default=None)
|
| 314 |
+
parser.add_argument('--ip', default=None)
|
| 315 |
+
args = parser.parse_args()
|
| 316 |
+
device = args.device
|
| 317 |
+
demo = main()
|
| 318 |
+
print('Successfully loaded, starting gradio demo')
|
| 319 |
+
demo.queue(concurrency_count=1, max_size=20).launch(share=args.share, server_name=args.ip, server_port=args.port)
|
draggan/draggan.py
ADDED
|
@@ -0,0 +1,355 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Modified from this following version https://github.com/skimai/DragGAN
|
| 2 |
+
|
| 3 |
+
import os
|
| 4 |
+
import sys
|
| 5 |
+
import time
|
| 6 |
+
from typing import List, Optional, Tuple
|
| 7 |
+
import copy
|
| 8 |
+
|
| 9 |
+
import numpy as np
|
| 10 |
+
import PIL
|
| 11 |
+
import torch
|
| 12 |
+
|
| 13 |
+
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
|
| 14 |
+
stylegan2_dir = os.path.join(CURRENT_DIR, "stylegan2")
|
| 15 |
+
sys.path.insert(0, stylegan2_dir)
|
| 16 |
+
import dnnlib
|
| 17 |
+
import legacy
|
| 18 |
+
from . import utils
|
| 19 |
+
|
| 20 |
+
def load_model(
|
| 21 |
+
network_pkl: str = "https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/afhqdog.pkl",
|
| 22 |
+
device: torch.device = torch.device("cuda"),
|
| 23 |
+
fp16: bool = True,
|
| 24 |
+
) -> torch.nn.Module:
|
| 25 |
+
"""
|
| 26 |
+
Loads a pretrained StyleGAN2-ADA generator network from a pickle file.
|
| 27 |
+
|
| 28 |
+
Args:
|
| 29 |
+
network_pkl (str): The URL or local path to the network pickle file.
|
| 30 |
+
device (torch.device): The device to use for the computation.
|
| 31 |
+
fp16 (bool): Whether to use half-precision floating point format for the network weights.
|
| 32 |
+
|
| 33 |
+
Returns:
|
| 34 |
+
The pretrained generator network.
|
| 35 |
+
"""
|
| 36 |
+
print('Loading networks from "%s"...' % network_pkl)
|
| 37 |
+
with dnnlib.util.open_url(network_pkl) as f:
|
| 38 |
+
chkpt = legacy.load_network_pkl(f, force_fp16=fp16)
|
| 39 |
+
G = chkpt["G_ema"].to(device).eval()
|
| 40 |
+
for param in G.parameters():
|
| 41 |
+
param.requires_grad_(False)
|
| 42 |
+
|
| 43 |
+
# Create a new attribute called "activations" for the Generator class
|
| 44 |
+
# This will be a list of activations from each layer
|
| 45 |
+
G.__setattr__("activations", None)
|
| 46 |
+
|
| 47 |
+
# Forward hook to collect features
|
| 48 |
+
def hook(module, input, output):
|
| 49 |
+
G.activations = output
|
| 50 |
+
|
| 51 |
+
# Apply the hook to the 7th layer (256x256)
|
| 52 |
+
for i, (name, module) in enumerate(G.synthesis.named_children()):
|
| 53 |
+
if i == 6:
|
| 54 |
+
print("Registering hook for:", name)
|
| 55 |
+
module.register_forward_hook(hook)
|
| 56 |
+
|
| 57 |
+
return G
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def register_hook(G):
|
| 61 |
+
# Create a new attribute called "activations" for the Generator class
|
| 62 |
+
# This will be a list of activations from each layer
|
| 63 |
+
G.__setattr__("activations", None)
|
| 64 |
+
|
| 65 |
+
# Forward hook to collect features
|
| 66 |
+
def hook(module, input, output):
|
| 67 |
+
G.activations = output
|
| 68 |
+
|
| 69 |
+
# Apply the hook to the 7th layer (256x256)
|
| 70 |
+
for i, (name, module) in enumerate(G.synthesis.named_children()):
|
| 71 |
+
if i == 6:
|
| 72 |
+
print("Registering hook for:", name)
|
| 73 |
+
module.register_forward_hook(hook)
|
| 74 |
+
return G
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def generate_W(
|
| 78 |
+
_G: torch.nn.Module,
|
| 79 |
+
seed: int = 0,
|
| 80 |
+
network_pkl: Optional[str] = None,
|
| 81 |
+
truncation_psi: float = 1.0,
|
| 82 |
+
truncation_cutoff: Optional[int] = None,
|
| 83 |
+
device: torch.device = torch.device("cuda"),
|
| 84 |
+
) -> np.ndarray:
|
| 85 |
+
"""
|
| 86 |
+
Generates a latent code tensor in W+ space from a pretrained StyleGAN2-ADA generator network.
|
| 87 |
+
|
| 88 |
+
Args:
|
| 89 |
+
_G (torch.nn.Module): The generator network, with underscore to avoid streamlit cache error
|
| 90 |
+
seed (int): The random seed to use for generating the latent code.
|
| 91 |
+
network_pkl (Optional[str]): The path to the network pickle file. If None, the default network will be used.
|
| 92 |
+
truncation_psi (float): The truncation psi value to use for the mapping network.
|
| 93 |
+
truncation_cutoff (Optional[int]): The number of layers to use for the truncation trick. If None, all layers will be used.
|
| 94 |
+
device (torch.device): The device to use for the computation.
|
| 95 |
+
|
| 96 |
+
Returns:
|
| 97 |
+
The W+ latent as a numpy array of shape [1, num_layers, 512].
|
| 98 |
+
"""
|
| 99 |
+
G = _G
|
| 100 |
+
torch.manual_seed(seed)
|
| 101 |
+
z = torch.randn(1, G.z_dim).to(device)
|
| 102 |
+
num_layers = G.synthesis.num_ws
|
| 103 |
+
if truncation_cutoff == -1:
|
| 104 |
+
truncation_cutoff = None
|
| 105 |
+
elif truncation_cutoff is not None:
|
| 106 |
+
truncation_cutoff = min(num_layers, truncation_cutoff)
|
| 107 |
+
W = G.mapping(
|
| 108 |
+
z,
|
| 109 |
+
None,
|
| 110 |
+
truncation_psi=truncation_psi,
|
| 111 |
+
truncation_cutoff=truncation_cutoff,
|
| 112 |
+
)
|
| 113 |
+
return W.cpu().numpy()
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def forward_G(
|
| 117 |
+
G: torch.nn.Module,
|
| 118 |
+
W: torch.Tensor,
|
| 119 |
+
device: torch.device,
|
| 120 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 121 |
+
"""
|
| 122 |
+
Forward pass through the generator network.
|
| 123 |
+
|
| 124 |
+
Args:
|
| 125 |
+
G (torch.nn.Module): The generator network.
|
| 126 |
+
W (torch.Tensor): The latent code tensor of shape [batch_size, latent_dim, 512].
|
| 127 |
+
device (torch.device): The device to use for the computation.
|
| 128 |
+
|
| 129 |
+
Returns:
|
| 130 |
+
A tuple containing the generated image tensor of shape [batch_size, 3, height, width]
|
| 131 |
+
and the feature maps tensor of shape [batch_size, num_channels, height, width].
|
| 132 |
+
"""
|
| 133 |
+
register_hook(G)
|
| 134 |
+
|
| 135 |
+
if not isinstance(W, torch.Tensor):
|
| 136 |
+
W = torch.from_numpy(W).to(device)
|
| 137 |
+
|
| 138 |
+
img = G.synthesis(W, noise_mode="const", force_fp32=True)
|
| 139 |
+
|
| 140 |
+
return img, G.activations[0]
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
def generate_image(
|
| 144 |
+
W,
|
| 145 |
+
_G: Optional[torch.nn.Module] = None,
|
| 146 |
+
network_pkl: Optional[str] = None,
|
| 147 |
+
class_idx=None,
|
| 148 |
+
device=torch.device("cuda"),
|
| 149 |
+
) -> Tuple[PIL.Image.Image, torch.Tensor]:
|
| 150 |
+
"""
|
| 151 |
+
Generates an image using a pretrained generator network.
|
| 152 |
+
|
| 153 |
+
Args:
|
| 154 |
+
W (torch.Tensor): A tensor of latent codes of shape [batch_size, latent_dim, 512].
|
| 155 |
+
_G (Optional[torch.nn.Module]): The generator network. If None, the network will be loaded from `network_pkl`.
|
| 156 |
+
network_pkl (Optional[str]): The path to the network pickle file. If None, the default network will be used.
|
| 157 |
+
class_idx (Optional[int]): The class index to use for conditional generation. If None, unconditional generation will be used.
|
| 158 |
+
device (str): The device to use for the computation.
|
| 159 |
+
|
| 160 |
+
Returns:
|
| 161 |
+
A tuple containing the generated image as a PIL Image object and the feature maps tensor of shape [batch_size, num_channels, height, width].
|
| 162 |
+
"""
|
| 163 |
+
if _G is None:
|
| 164 |
+
assert network_pkl is not None
|
| 165 |
+
_G = load_model(network_pkl, device)
|
| 166 |
+
G = _G
|
| 167 |
+
|
| 168 |
+
# Labels.
|
| 169 |
+
label = torch.zeros([1, G.c_dim], device=device)
|
| 170 |
+
if G.c_dim != 0:
|
| 171 |
+
if class_idx is None:
|
| 172 |
+
raise Exception(
|
| 173 |
+
"Must specify class label with --class when using a conditional network"
|
| 174 |
+
)
|
| 175 |
+
label[:, class_idx] = 1
|
| 176 |
+
else:
|
| 177 |
+
if class_idx is not None:
|
| 178 |
+
print("warn: --class=lbl ignored when running on an unconditional network")
|
| 179 |
+
|
| 180 |
+
# Generate image
|
| 181 |
+
img, features = forward_G(G, W, device)
|
| 182 |
+
|
| 183 |
+
img = utils.tensor_to_PIL(img)
|
| 184 |
+
|
| 185 |
+
return img, features
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def drag_gan(
|
| 189 |
+
W,
|
| 190 |
+
G,
|
| 191 |
+
handle_points,
|
| 192 |
+
target_points,
|
| 193 |
+
mask,
|
| 194 |
+
max_iters=1000,
|
| 195 |
+
r1=3,
|
| 196 |
+
r2=12,
|
| 197 |
+
lam=20,
|
| 198 |
+
d=2,
|
| 199 |
+
lr=2e-3,
|
| 200 |
+
):
|
| 201 |
+
|
| 202 |
+
handle_points0 = copy.deepcopy(handle_points)
|
| 203 |
+
handle_points = torch.stack(handle_points)
|
| 204 |
+
handle_points0 = torch.stack(handle_points0)
|
| 205 |
+
target_points = torch.stack(target_points)
|
| 206 |
+
|
| 207 |
+
device = torch.device("cuda")
|
| 208 |
+
|
| 209 |
+
img, F0 = forward_G(G, W, device)
|
| 210 |
+
|
| 211 |
+
target_resolution = img.shape[-1]
|
| 212 |
+
F0_resized = torch.nn.functional.interpolate(
|
| 213 |
+
F0,
|
| 214 |
+
size=(target_resolution, target_resolution),
|
| 215 |
+
mode="bilinear",
|
| 216 |
+
align_corners=True,
|
| 217 |
+
).detach()
|
| 218 |
+
|
| 219 |
+
W = torch.from_numpy(W).to(device).float()
|
| 220 |
+
W.requires_grad_(False)
|
| 221 |
+
|
| 222 |
+
# Only optimize the first 6 layers of W
|
| 223 |
+
W_layers_to_optimize = W[:, :6].clone()
|
| 224 |
+
W_layers_to_optimize.requires_grad_(True)
|
| 225 |
+
|
| 226 |
+
optimizer = torch.optim.Adam([W_layers_to_optimize], lr=lr)
|
| 227 |
+
|
| 228 |
+
for _ in range(max_iters):
|
| 229 |
+
start = time.perf_counter()
|
| 230 |
+
if torch.allclose(handle_points, target_points, atol=d):
|
| 231 |
+
break
|
| 232 |
+
|
| 233 |
+
optimizer.zero_grad()
|
| 234 |
+
W_combined = torch.cat([W_layers_to_optimize, W[:, 6:].detach()], dim=1)
|
| 235 |
+
|
| 236 |
+
img, F = forward_G(G, W_combined, device)
|
| 237 |
+
F_resized = torch.nn.functional.interpolate(
|
| 238 |
+
F,
|
| 239 |
+
size=(target_resolution, target_resolution),
|
| 240 |
+
mode="bilinear",
|
| 241 |
+
align_corners=True,
|
| 242 |
+
)
|
| 243 |
+
|
| 244 |
+
# motion supervision
|
| 245 |
+
loss = motion_supervison(handle_points, target_points, F_resized, r1, device)
|
| 246 |
+
|
| 247 |
+
# if mask is not None:
|
| 248 |
+
# loss += ((F - F0) * (1 - mask)).abs().mean() * lam
|
| 249 |
+
|
| 250 |
+
loss.backward()
|
| 251 |
+
optimizer.step()
|
| 252 |
+
|
| 253 |
+
print(
|
| 254 |
+
f"Loss: {loss.item():0.2f}\tTime: {(time.perf_counter() - start) * 1000:.0f}ms"
|
| 255 |
+
)
|
| 256 |
+
|
| 257 |
+
with torch.no_grad():
|
| 258 |
+
img, F = forward_G(G, W_combined, device)
|
| 259 |
+
handle_points = point_tracking(F_resized, F0_resized, handle_points, handle_points0, r2, device)
|
| 260 |
+
|
| 261 |
+
# if iter % 1 == 0:
|
| 262 |
+
# print(iter, loss.item(), handle_points, target_points)
|
| 263 |
+
W_out = torch.cat([W_layers_to_optimize, W[:, 6:]], dim=1).detach().cpu().numpy()
|
| 264 |
+
|
| 265 |
+
img = utils.tensor_to_PIL(img)
|
| 266 |
+
yield img, W_out, handle_points
|
| 267 |
+
|
| 268 |
+
|
| 269 |
+
def motion_supervison(handle_points, target_points, F, r1, device):
|
| 270 |
+
loss = 0
|
| 271 |
+
n = len(handle_points)
|
| 272 |
+
for i in range(n):
|
| 273 |
+
target2handle = target_points[i] - handle_points[i]
|
| 274 |
+
d_i = target2handle / (torch.norm(target2handle) + 1e-7)
|
| 275 |
+
if torch.norm(d_i) > torch.norm(target2handle):
|
| 276 |
+
d_i = target2handle
|
| 277 |
+
|
| 278 |
+
mask = utils.create_circular_mask(
|
| 279 |
+
F.shape[2], F.shape[3], center=handle_points[i].tolist(), radius=r1
|
| 280 |
+
).to(device)
|
| 281 |
+
|
| 282 |
+
coordinates = torch.nonzero(mask).float() # shape [num_points, 2]
|
| 283 |
+
|
| 284 |
+
# Shift the coordinates in the direction d_i
|
| 285 |
+
shifted_coordinates = coordinates + d_i[None]
|
| 286 |
+
|
| 287 |
+
h, w = F.shape[2], F.shape[3]
|
| 288 |
+
|
| 289 |
+
# Extract features in the mask region and compute the loss
|
| 290 |
+
F_qi = F[:, :, mask] # shape: [C, H*W]
|
| 291 |
+
|
| 292 |
+
# Sample shifted patch from F
|
| 293 |
+
normalized_shifted_coordinates = shifted_coordinates.clone()
|
| 294 |
+
normalized_shifted_coordinates[:, 0] = (
|
| 295 |
+
2.0 * shifted_coordinates[:, 0] / (h - 1)
|
| 296 |
+
) - 1 # for height
|
| 297 |
+
normalized_shifted_coordinates[:, 1] = (
|
| 298 |
+
2.0 * shifted_coordinates[:, 1] / (w - 1)
|
| 299 |
+
) - 1 # for width
|
| 300 |
+
# Add extra dimensions for batch and channels (required by grid_sample)
|
| 301 |
+
normalized_shifted_coordinates = normalized_shifted_coordinates.unsqueeze(
|
| 302 |
+
0
|
| 303 |
+
).unsqueeze(
|
| 304 |
+
0
|
| 305 |
+
) # shape [1, 1, num_points, 2]
|
| 306 |
+
normalized_shifted_coordinates = normalized_shifted_coordinates.flip(
|
| 307 |
+
-1
|
| 308 |
+
) # grid_sample expects [x, y] instead of [y, x]
|
| 309 |
+
normalized_shifted_coordinates = normalized_shifted_coordinates.clamp(-1, 1)
|
| 310 |
+
|
| 311 |
+
# Use grid_sample to interpolate the feature map F at the shifted patch coordinates
|
| 312 |
+
F_qi_plus_di = torch.nn.functional.grid_sample(
|
| 313 |
+
F, normalized_shifted_coordinates, mode="bilinear", align_corners=True
|
| 314 |
+
)
|
| 315 |
+
# Output has shape [1, C, 1, num_points] so squeeze it
|
| 316 |
+
F_qi_plus_di = F_qi_plus_di.squeeze(2) # shape [1, C, num_points]
|
| 317 |
+
|
| 318 |
+
loss += torch.nn.functional.l1_loss(F_qi.detach(), F_qi_plus_di)
|
| 319 |
+
return loss
|
| 320 |
+
|
| 321 |
+
|
| 322 |
+
def point_tracking(
|
| 323 |
+
F: torch.Tensor,
|
| 324 |
+
F0: torch.Tensor,
|
| 325 |
+
handle_points: torch.Tensor,
|
| 326 |
+
handle_points0: torch.Tensor,
|
| 327 |
+
r2: int = 3,
|
| 328 |
+
device: torch.device = torch.device("cuda"),
|
| 329 |
+
) -> torch.Tensor:
|
| 330 |
+
|
| 331 |
+
n = handle_points.shape[0] # Number of handle points
|
| 332 |
+
new_handle_points = torch.zeros_like(handle_points)
|
| 333 |
+
|
| 334 |
+
for i in range(n):
|
| 335 |
+
# Compute the patch around the handle point
|
| 336 |
+
patch = utils.create_square_mask(
|
| 337 |
+
F.shape[2], F.shape[3], center=handle_points[i].tolist(), radius=r2
|
| 338 |
+
).to(device)
|
| 339 |
+
|
| 340 |
+
# Find indices where the patch is True
|
| 341 |
+
patch_coordinates = torch.nonzero(patch) # shape [num_points, 2]
|
| 342 |
+
|
| 343 |
+
# Extract features in the patch
|
| 344 |
+
F_qi = F[:, :, patch_coordinates[:, 0], patch_coordinates[:, 1]]
|
| 345 |
+
# Extract feature of the initial handle point
|
| 346 |
+
f_i = F0[:, :, handle_points0[i][0].long(), handle_points0[i][1].long()]
|
| 347 |
+
|
| 348 |
+
# Compute the L1 distance between the patch features and the initial handle point feature
|
| 349 |
+
distances = torch.norm(F_qi - f_i[:, :, None], p=1, dim=1)
|
| 350 |
+
|
| 351 |
+
# Find the new handle point as the one with minimum distance
|
| 352 |
+
min_index = torch.argmin(distances)
|
| 353 |
+
new_handle_points[i] = patch_coordinates[min_index]
|
| 354 |
+
|
| 355 |
+
return new_handle_points
|
draggan/stylegan2/LICENSE.txt
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright (c) 2021, NVIDIA Corporation. All rights reserved.
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
NVIDIA Source Code License for StyleGAN2 with Adaptive Discriminator Augmentation (ADA)
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
=======================================================================
|
| 8 |
+
|
| 9 |
+
1. Definitions
|
| 10 |
+
|
| 11 |
+
"Licensor" means any person or entity that distributes its Work.
|
| 12 |
+
|
| 13 |
+
"Software" means the original work of authorship made available under
|
| 14 |
+
this License.
|
| 15 |
+
|
| 16 |
+
"Work" means the Software and any additions to or derivative works of
|
| 17 |
+
the Software that are made available under this License.
|
| 18 |
+
|
| 19 |
+
The terms "reproduce," "reproduction," "derivative works," and
|
| 20 |
+
"distribution" have the meaning as provided under U.S. copyright law;
|
| 21 |
+
provided, however, that for the purposes of this License, derivative
|
| 22 |
+
works shall not include works that remain separable from, or merely
|
| 23 |
+
link (or bind by name) to the interfaces of, the Work.
|
| 24 |
+
|
| 25 |
+
Works, including the Software, are "made available" under this License
|
| 26 |
+
by including in or with the Work either (a) a copyright notice
|
| 27 |
+
referencing the applicability of this License to the Work, or (b) a
|
| 28 |
+
copy of this License.
|
| 29 |
+
|
| 30 |
+
2. License Grants
|
| 31 |
+
|
| 32 |
+
2.1 Copyright Grant. Subject to the terms and conditions of this
|
| 33 |
+
License, each Licensor grants to you a perpetual, worldwide,
|
| 34 |
+
non-exclusive, royalty-free, copyright license to reproduce,
|
| 35 |
+
prepare derivative works of, publicly display, publicly perform,
|
| 36 |
+
sublicense and distribute its Work and any resulting derivative
|
| 37 |
+
works in any form.
|
| 38 |
+
|
| 39 |
+
3. Limitations
|
| 40 |
+
|
| 41 |
+
3.1 Redistribution. You may reproduce or distribute the Work only
|
| 42 |
+
if (a) you do so under this License, (b) you include a complete
|
| 43 |
+
copy of this License with your distribution, and (c) you retain
|
| 44 |
+
without modification any copyright, patent, trademark, or
|
| 45 |
+
attribution notices that are present in the Work.
|
| 46 |
+
|
| 47 |
+
3.2 Derivative Works. You may specify that additional or different
|
| 48 |
+
terms apply to the use, reproduction, and distribution of your
|
| 49 |
+
derivative works of the Work ("Your Terms") only if (a) Your Terms
|
| 50 |
+
provide that the use limitation in Section 3.3 applies to your
|
| 51 |
+
derivative works, and (b) you identify the specific derivative
|
| 52 |
+
works that are subject to Your Terms. Notwithstanding Your Terms,
|
| 53 |
+
this License (including the redistribution requirements in Section
|
| 54 |
+
3.1) will continue to apply to the Work itself.
|
| 55 |
+
|
| 56 |
+
3.3 Use Limitation. The Work and any derivative works thereof only
|
| 57 |
+
may be used or intended for use non-commercially. Notwithstanding
|
| 58 |
+
the foregoing, NVIDIA and its affiliates may use the Work and any
|
| 59 |
+
derivative works commercially. As used herein, "non-commercially"
|
| 60 |
+
means for research or evaluation purposes only.
|
| 61 |
+
|
| 62 |
+
3.4 Patent Claims. If you bring or threaten to bring a patent claim
|
| 63 |
+
against any Licensor (including any claim, cross-claim or
|
| 64 |
+
counterclaim in a lawsuit) to enforce any patents that you allege
|
| 65 |
+
are infringed by any Work, then your rights under this License from
|
| 66 |
+
such Licensor (including the grant in Section 2.1) will terminate
|
| 67 |
+
immediately.
|
| 68 |
+
|
| 69 |
+
3.5 Trademarks. This License does not grant any rights to use any
|
| 70 |
+
Licensor’s or its affiliates’ names, logos, or trademarks, except
|
| 71 |
+
as necessary to reproduce the notices described in this License.
|
| 72 |
+
|
| 73 |
+
3.6 Termination. If you violate any term of this License, then your
|
| 74 |
+
rights under this License (including the grant in Section 2.1) will
|
| 75 |
+
terminate immediately.
|
| 76 |
+
|
| 77 |
+
4. Disclaimer of Warranty.
|
| 78 |
+
|
| 79 |
+
THE WORK IS PROVIDED "AS IS" WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
| 80 |
+
KIND, EITHER EXPRESS OR IMPLIED, INCLUDING WARRANTIES OR CONDITIONS OF
|
| 81 |
+
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, TITLE OR
|
| 82 |
+
NON-INFRINGEMENT. YOU BEAR THE RISK OF UNDERTAKING ANY ACTIVITIES UNDER
|
| 83 |
+
THIS LICENSE.
|
| 84 |
+
|
| 85 |
+
5. Limitation of Liability.
|
| 86 |
+
|
| 87 |
+
EXCEPT AS PROHIBITED BY APPLICABLE LAW, IN NO EVENT AND UNDER NO LEGAL
|
| 88 |
+
THEORY, WHETHER IN TORT (INCLUDING NEGLIGENCE), CONTRACT, OR OTHERWISE
|
| 89 |
+
SHALL ANY LICENSOR BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY DIRECT,
|
| 90 |
+
INDIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES ARISING OUT OF
|
| 91 |
+
OR RELATED TO THIS LICENSE, THE USE OR INABILITY TO USE THE WORK
|
| 92 |
+
(INCLUDING BUT NOT LIMITED TO LOSS OF GOODWILL, BUSINESS INTERRUPTION,
|
| 93 |
+
LOST PROFITS OR DATA, COMPUTER FAILURE OR MALFUNCTION, OR ANY OTHER
|
| 94 |
+
COMMERCIAL DAMAGES OR LOSSES), EVEN IF THE LICENSOR HAS BEEN ADVISED OF
|
| 95 |
+
THE POSSIBILITY OF SUCH DAMAGES.
|
| 96 |
+
|
| 97 |
+
=======================================================================
|
draggan/stylegan2/__init__.py
ADDED
|
File without changes
|
draggan/stylegan2/dnnlib/__init__.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
from .util import EasyDict, make_cache_dir_path
|
draggan/stylegan2/dnnlib/util.py
ADDED
|
@@ -0,0 +1,477 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Miscellaneous utility classes and functions."""
|
| 10 |
+
|
| 11 |
+
import ctypes
|
| 12 |
+
import fnmatch
|
| 13 |
+
import importlib
|
| 14 |
+
import inspect
|
| 15 |
+
import numpy as np
|
| 16 |
+
import os
|
| 17 |
+
import shutil
|
| 18 |
+
import sys
|
| 19 |
+
import types
|
| 20 |
+
import io
|
| 21 |
+
import pickle
|
| 22 |
+
import re
|
| 23 |
+
import requests
|
| 24 |
+
import html
|
| 25 |
+
import hashlib
|
| 26 |
+
import glob
|
| 27 |
+
import tempfile
|
| 28 |
+
import urllib
|
| 29 |
+
import urllib.request
|
| 30 |
+
import uuid
|
| 31 |
+
|
| 32 |
+
from distutils.util import strtobool
|
| 33 |
+
from typing import Any, List, Tuple, Union
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
# Util classes
|
| 37 |
+
# ------------------------------------------------------------------------------------------
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class EasyDict(dict):
|
| 41 |
+
"""Convenience class that behaves like a dict but allows access with the attribute syntax."""
|
| 42 |
+
|
| 43 |
+
def __getattr__(self, name: str) -> Any:
|
| 44 |
+
try:
|
| 45 |
+
return self[name]
|
| 46 |
+
except KeyError:
|
| 47 |
+
raise AttributeError(name)
|
| 48 |
+
|
| 49 |
+
def __setattr__(self, name: str, value: Any) -> None:
|
| 50 |
+
self[name] = value
|
| 51 |
+
|
| 52 |
+
def __delattr__(self, name: str) -> None:
|
| 53 |
+
del self[name]
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
class Logger(object):
|
| 57 |
+
"""Redirect stderr to stdout, optionally print stdout to a file, and optionally force flushing on both stdout and the file."""
|
| 58 |
+
|
| 59 |
+
def __init__(self, file_name: str = None, file_mode: str = "w", should_flush: bool = True):
|
| 60 |
+
self.file = None
|
| 61 |
+
|
| 62 |
+
if file_name is not None:
|
| 63 |
+
self.file = open(file_name, file_mode)
|
| 64 |
+
|
| 65 |
+
self.should_flush = should_flush
|
| 66 |
+
self.stdout = sys.stdout
|
| 67 |
+
self.stderr = sys.stderr
|
| 68 |
+
|
| 69 |
+
sys.stdout = self
|
| 70 |
+
sys.stderr = self
|
| 71 |
+
|
| 72 |
+
def __enter__(self) -> "Logger":
|
| 73 |
+
return self
|
| 74 |
+
|
| 75 |
+
def __exit__(self, exc_type: Any, exc_value: Any, traceback: Any) -> None:
|
| 76 |
+
self.close()
|
| 77 |
+
|
| 78 |
+
def write(self, text: Union[str, bytes]) -> None:
|
| 79 |
+
"""Write text to stdout (and a file) and optionally flush."""
|
| 80 |
+
if isinstance(text, bytes):
|
| 81 |
+
text = text.decode()
|
| 82 |
+
if len(text) == 0: # workaround for a bug in VSCode debugger: sys.stdout.write(''); sys.stdout.flush() => crash
|
| 83 |
+
return
|
| 84 |
+
|
| 85 |
+
if self.file is not None:
|
| 86 |
+
self.file.write(text)
|
| 87 |
+
|
| 88 |
+
self.stdout.write(text)
|
| 89 |
+
|
| 90 |
+
if self.should_flush:
|
| 91 |
+
self.flush()
|
| 92 |
+
|
| 93 |
+
def flush(self) -> None:
|
| 94 |
+
"""Flush written text to both stdout and a file, if open."""
|
| 95 |
+
if self.file is not None:
|
| 96 |
+
self.file.flush()
|
| 97 |
+
|
| 98 |
+
self.stdout.flush()
|
| 99 |
+
|
| 100 |
+
def close(self) -> None:
|
| 101 |
+
"""Flush, close possible files, and remove stdout/stderr mirroring."""
|
| 102 |
+
self.flush()
|
| 103 |
+
|
| 104 |
+
# if using multiple loggers, prevent closing in wrong order
|
| 105 |
+
if sys.stdout is self:
|
| 106 |
+
sys.stdout = self.stdout
|
| 107 |
+
if sys.stderr is self:
|
| 108 |
+
sys.stderr = self.stderr
|
| 109 |
+
|
| 110 |
+
if self.file is not None:
|
| 111 |
+
self.file.close()
|
| 112 |
+
self.file = None
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
# Cache directories
|
| 116 |
+
# ------------------------------------------------------------------------------------------
|
| 117 |
+
|
| 118 |
+
_dnnlib_cache_dir = None
|
| 119 |
+
|
| 120 |
+
def set_cache_dir(path: str) -> None:
|
| 121 |
+
global _dnnlib_cache_dir
|
| 122 |
+
_dnnlib_cache_dir = path
|
| 123 |
+
|
| 124 |
+
def make_cache_dir_path(*paths: str) -> str:
|
| 125 |
+
if _dnnlib_cache_dir is not None:
|
| 126 |
+
return os.path.join(_dnnlib_cache_dir, *paths)
|
| 127 |
+
if 'DNNLIB_CACHE_DIR' in os.environ:
|
| 128 |
+
return os.path.join(os.environ['DNNLIB_CACHE_DIR'], *paths)
|
| 129 |
+
if 'HOME' in os.environ:
|
| 130 |
+
return os.path.join(os.environ['HOME'], '.cache', 'dnnlib', *paths)
|
| 131 |
+
if 'USERPROFILE' in os.environ:
|
| 132 |
+
return os.path.join(os.environ['USERPROFILE'], '.cache', 'dnnlib', *paths)
|
| 133 |
+
return os.path.join(tempfile.gettempdir(), '.cache', 'dnnlib', *paths)
|
| 134 |
+
|
| 135 |
+
# Small util functions
|
| 136 |
+
# ------------------------------------------------------------------------------------------
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
def format_time(seconds: Union[int, float]) -> str:
|
| 140 |
+
"""Convert the seconds to human readable string with days, hours, minutes and seconds."""
|
| 141 |
+
s = int(np.rint(seconds))
|
| 142 |
+
|
| 143 |
+
if s < 60:
|
| 144 |
+
return "{0}s".format(s)
|
| 145 |
+
elif s < 60 * 60:
|
| 146 |
+
return "{0}m {1:02}s".format(s // 60, s % 60)
|
| 147 |
+
elif s < 24 * 60 * 60:
|
| 148 |
+
return "{0}h {1:02}m {2:02}s".format(s // (60 * 60), (s // 60) % 60, s % 60)
|
| 149 |
+
else:
|
| 150 |
+
return "{0}d {1:02}h {2:02}m".format(s // (24 * 60 * 60), (s // (60 * 60)) % 24, (s // 60) % 60)
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
def ask_yes_no(question: str) -> bool:
|
| 154 |
+
"""Ask the user the question until the user inputs a valid answer."""
|
| 155 |
+
while True:
|
| 156 |
+
try:
|
| 157 |
+
print("{0} [y/n]".format(question))
|
| 158 |
+
return strtobool(input().lower())
|
| 159 |
+
except ValueError:
|
| 160 |
+
pass
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
def tuple_product(t: Tuple) -> Any:
|
| 164 |
+
"""Calculate the product of the tuple elements."""
|
| 165 |
+
result = 1
|
| 166 |
+
|
| 167 |
+
for v in t:
|
| 168 |
+
result *= v
|
| 169 |
+
|
| 170 |
+
return result
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
_str_to_ctype = {
|
| 174 |
+
"uint8": ctypes.c_ubyte,
|
| 175 |
+
"uint16": ctypes.c_uint16,
|
| 176 |
+
"uint32": ctypes.c_uint32,
|
| 177 |
+
"uint64": ctypes.c_uint64,
|
| 178 |
+
"int8": ctypes.c_byte,
|
| 179 |
+
"int16": ctypes.c_int16,
|
| 180 |
+
"int32": ctypes.c_int32,
|
| 181 |
+
"int64": ctypes.c_int64,
|
| 182 |
+
"float32": ctypes.c_float,
|
| 183 |
+
"float64": ctypes.c_double
|
| 184 |
+
}
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
def get_dtype_and_ctype(type_obj: Any) -> Tuple[np.dtype, Any]:
|
| 188 |
+
"""Given a type name string (or an object having a __name__ attribute), return matching Numpy and ctypes types that have the same size in bytes."""
|
| 189 |
+
type_str = None
|
| 190 |
+
|
| 191 |
+
if isinstance(type_obj, str):
|
| 192 |
+
type_str = type_obj
|
| 193 |
+
elif hasattr(type_obj, "__name__"):
|
| 194 |
+
type_str = type_obj.__name__
|
| 195 |
+
elif hasattr(type_obj, "name"):
|
| 196 |
+
type_str = type_obj.name
|
| 197 |
+
else:
|
| 198 |
+
raise RuntimeError("Cannot infer type name from input")
|
| 199 |
+
|
| 200 |
+
assert type_str in _str_to_ctype.keys()
|
| 201 |
+
|
| 202 |
+
my_dtype = np.dtype(type_str)
|
| 203 |
+
my_ctype = _str_to_ctype[type_str]
|
| 204 |
+
|
| 205 |
+
assert my_dtype.itemsize == ctypes.sizeof(my_ctype)
|
| 206 |
+
|
| 207 |
+
return my_dtype, my_ctype
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
def is_pickleable(obj: Any) -> bool:
|
| 211 |
+
try:
|
| 212 |
+
with io.BytesIO() as stream:
|
| 213 |
+
pickle.dump(obj, stream)
|
| 214 |
+
return True
|
| 215 |
+
except:
|
| 216 |
+
return False
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
# Functionality to import modules/objects by name, and call functions by name
|
| 220 |
+
# ------------------------------------------------------------------------------------------
|
| 221 |
+
|
| 222 |
+
def get_module_from_obj_name(obj_name: str) -> Tuple[types.ModuleType, str]:
|
| 223 |
+
"""Searches for the underlying module behind the name to some python object.
|
| 224 |
+
Returns the module and the object name (original name with module part removed)."""
|
| 225 |
+
|
| 226 |
+
# allow convenience shorthands, substitute them by full names
|
| 227 |
+
obj_name = re.sub("^np.", "numpy.", obj_name)
|
| 228 |
+
obj_name = re.sub("^tf.", "tensorflow.", obj_name)
|
| 229 |
+
|
| 230 |
+
# list alternatives for (module_name, local_obj_name)
|
| 231 |
+
parts = obj_name.split(".")
|
| 232 |
+
name_pairs = [(".".join(parts[:i]), ".".join(parts[i:])) for i in range(len(parts), 0, -1)]
|
| 233 |
+
|
| 234 |
+
# try each alternative in turn
|
| 235 |
+
for module_name, local_obj_name in name_pairs:
|
| 236 |
+
try:
|
| 237 |
+
module = importlib.import_module(module_name) # may raise ImportError
|
| 238 |
+
get_obj_from_module(module, local_obj_name) # may raise AttributeError
|
| 239 |
+
return module, local_obj_name
|
| 240 |
+
except:
|
| 241 |
+
pass
|
| 242 |
+
|
| 243 |
+
# maybe some of the modules themselves contain errors?
|
| 244 |
+
for module_name, _local_obj_name in name_pairs:
|
| 245 |
+
try:
|
| 246 |
+
importlib.import_module(module_name) # may raise ImportError
|
| 247 |
+
except ImportError:
|
| 248 |
+
if not str(sys.exc_info()[1]).startswith("No module named '" + module_name + "'"):
|
| 249 |
+
raise
|
| 250 |
+
|
| 251 |
+
# maybe the requested attribute is missing?
|
| 252 |
+
for module_name, local_obj_name in name_pairs:
|
| 253 |
+
try:
|
| 254 |
+
module = importlib.import_module(module_name) # may raise ImportError
|
| 255 |
+
get_obj_from_module(module, local_obj_name) # may raise AttributeError
|
| 256 |
+
except ImportError:
|
| 257 |
+
pass
|
| 258 |
+
|
| 259 |
+
# we are out of luck, but we have no idea why
|
| 260 |
+
raise ImportError(obj_name)
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
def get_obj_from_module(module: types.ModuleType, obj_name: str) -> Any:
|
| 264 |
+
"""Traverses the object name and returns the last (rightmost) python object."""
|
| 265 |
+
if obj_name == '':
|
| 266 |
+
return module
|
| 267 |
+
obj = module
|
| 268 |
+
for part in obj_name.split("."):
|
| 269 |
+
obj = getattr(obj, part)
|
| 270 |
+
return obj
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
def get_obj_by_name(name: str) -> Any:
|
| 274 |
+
"""Finds the python object with the given name."""
|
| 275 |
+
module, obj_name = get_module_from_obj_name(name)
|
| 276 |
+
return get_obj_from_module(module, obj_name)
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
def call_func_by_name(*args, func_name: str = None, **kwargs) -> Any:
|
| 280 |
+
"""Finds the python object with the given name and calls it as a function."""
|
| 281 |
+
assert func_name is not None
|
| 282 |
+
func_obj = get_obj_by_name(func_name)
|
| 283 |
+
assert callable(func_obj)
|
| 284 |
+
return func_obj(*args, **kwargs)
|
| 285 |
+
|
| 286 |
+
|
| 287 |
+
def construct_class_by_name(*args, class_name: str = None, **kwargs) -> Any:
|
| 288 |
+
"""Finds the python class with the given name and constructs it with the given arguments."""
|
| 289 |
+
return call_func_by_name(*args, func_name=class_name, **kwargs)
|
| 290 |
+
|
| 291 |
+
|
| 292 |
+
def get_module_dir_by_obj_name(obj_name: str) -> str:
|
| 293 |
+
"""Get the directory path of the module containing the given object name."""
|
| 294 |
+
module, _ = get_module_from_obj_name(obj_name)
|
| 295 |
+
return os.path.dirname(inspect.getfile(module))
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
def is_top_level_function(obj: Any) -> bool:
|
| 299 |
+
"""Determine whether the given object is a top-level function, i.e., defined at module scope using 'def'."""
|
| 300 |
+
return callable(obj) and obj.__name__ in sys.modules[obj.__module__].__dict__
|
| 301 |
+
|
| 302 |
+
|
| 303 |
+
def get_top_level_function_name(obj: Any) -> str:
|
| 304 |
+
"""Return the fully-qualified name of a top-level function."""
|
| 305 |
+
assert is_top_level_function(obj)
|
| 306 |
+
module = obj.__module__
|
| 307 |
+
if module == '__main__':
|
| 308 |
+
module = os.path.splitext(os.path.basename(sys.modules[module].__file__))[0]
|
| 309 |
+
return module + "." + obj.__name__
|
| 310 |
+
|
| 311 |
+
|
| 312 |
+
# File system helpers
|
| 313 |
+
# ------------------------------------------------------------------------------------------
|
| 314 |
+
|
| 315 |
+
def list_dir_recursively_with_ignore(dir_path: str, ignores: List[str] = None, add_base_to_relative: bool = False) -> List[Tuple[str, str]]:
|
| 316 |
+
"""List all files recursively in a given directory while ignoring given file and directory names.
|
| 317 |
+
Returns list of tuples containing both absolute and relative paths."""
|
| 318 |
+
assert os.path.isdir(dir_path)
|
| 319 |
+
base_name = os.path.basename(os.path.normpath(dir_path))
|
| 320 |
+
|
| 321 |
+
if ignores is None:
|
| 322 |
+
ignores = []
|
| 323 |
+
|
| 324 |
+
result = []
|
| 325 |
+
|
| 326 |
+
for root, dirs, files in os.walk(dir_path, topdown=True):
|
| 327 |
+
for ignore_ in ignores:
|
| 328 |
+
dirs_to_remove = [d for d in dirs if fnmatch.fnmatch(d, ignore_)]
|
| 329 |
+
|
| 330 |
+
# dirs need to be edited in-place
|
| 331 |
+
for d in dirs_to_remove:
|
| 332 |
+
dirs.remove(d)
|
| 333 |
+
|
| 334 |
+
files = [f for f in files if not fnmatch.fnmatch(f, ignore_)]
|
| 335 |
+
|
| 336 |
+
absolute_paths = [os.path.join(root, f) for f in files]
|
| 337 |
+
relative_paths = [os.path.relpath(p, dir_path) for p in absolute_paths]
|
| 338 |
+
|
| 339 |
+
if add_base_to_relative:
|
| 340 |
+
relative_paths = [os.path.join(base_name, p) for p in relative_paths]
|
| 341 |
+
|
| 342 |
+
assert len(absolute_paths) == len(relative_paths)
|
| 343 |
+
result += zip(absolute_paths, relative_paths)
|
| 344 |
+
|
| 345 |
+
return result
|
| 346 |
+
|
| 347 |
+
|
| 348 |
+
def copy_files_and_create_dirs(files: List[Tuple[str, str]]) -> None:
|
| 349 |
+
"""Takes in a list of tuples of (src, dst) paths and copies files.
|
| 350 |
+
Will create all necessary directories."""
|
| 351 |
+
for file in files:
|
| 352 |
+
target_dir_name = os.path.dirname(file[1])
|
| 353 |
+
|
| 354 |
+
# will create all intermediate-level directories
|
| 355 |
+
if not os.path.exists(target_dir_name):
|
| 356 |
+
os.makedirs(target_dir_name)
|
| 357 |
+
|
| 358 |
+
shutil.copyfile(file[0], file[1])
|
| 359 |
+
|
| 360 |
+
|
| 361 |
+
# URL helpers
|
| 362 |
+
# ------------------------------------------------------------------------------------------
|
| 363 |
+
|
| 364 |
+
def is_url(obj: Any, allow_file_urls: bool = False) -> bool:
|
| 365 |
+
"""Determine whether the given object is a valid URL string."""
|
| 366 |
+
if not isinstance(obj, str) or not "://" in obj:
|
| 367 |
+
return False
|
| 368 |
+
if allow_file_urls and obj.startswith('file://'):
|
| 369 |
+
return True
|
| 370 |
+
try:
|
| 371 |
+
res = requests.compat.urlparse(obj)
|
| 372 |
+
if not res.scheme or not res.netloc or not "." in res.netloc:
|
| 373 |
+
return False
|
| 374 |
+
res = requests.compat.urlparse(requests.compat.urljoin(obj, "/"))
|
| 375 |
+
if not res.scheme or not res.netloc or not "." in res.netloc:
|
| 376 |
+
return False
|
| 377 |
+
except:
|
| 378 |
+
return False
|
| 379 |
+
return True
|
| 380 |
+
|
| 381 |
+
|
| 382 |
+
def open_url(url: str, cache_dir: str = None, num_attempts: int = 10, verbose: bool = True, return_filename: bool = False, cache: bool = True) -> Any:
|
| 383 |
+
"""Download the given URL and return a binary-mode file object to access the data."""
|
| 384 |
+
assert num_attempts >= 1
|
| 385 |
+
assert not (return_filename and (not cache))
|
| 386 |
+
|
| 387 |
+
# Doesn't look like an URL scheme so interpret it as a local filename.
|
| 388 |
+
if not re.match('^[a-z]+://', url):
|
| 389 |
+
return url if return_filename else open(url, "rb")
|
| 390 |
+
|
| 391 |
+
# Handle file URLs. This code handles unusual file:// patterns that
|
| 392 |
+
# arise on Windows:
|
| 393 |
+
#
|
| 394 |
+
# file:///c:/foo.txt
|
| 395 |
+
#
|
| 396 |
+
# which would translate to a local '/c:/foo.txt' filename that's
|
| 397 |
+
# invalid. Drop the forward slash for such pathnames.
|
| 398 |
+
#
|
| 399 |
+
# If you touch this code path, you should test it on both Linux and
|
| 400 |
+
# Windows.
|
| 401 |
+
#
|
| 402 |
+
# Some internet resources suggest using urllib.request.url2pathname() but
|
| 403 |
+
# but that converts forward slashes to backslashes and this causes
|
| 404 |
+
# its own set of problems.
|
| 405 |
+
if url.startswith('file://'):
|
| 406 |
+
filename = urllib.parse.urlparse(url).path
|
| 407 |
+
if re.match(r'^/[a-zA-Z]:', filename):
|
| 408 |
+
filename = filename[1:]
|
| 409 |
+
return filename if return_filename else open(filename, "rb")
|
| 410 |
+
|
| 411 |
+
assert is_url(url)
|
| 412 |
+
|
| 413 |
+
# Lookup from cache.
|
| 414 |
+
if cache_dir is None:
|
| 415 |
+
cache_dir = make_cache_dir_path('downloads')
|
| 416 |
+
|
| 417 |
+
url_md5 = hashlib.md5(url.encode("utf-8")).hexdigest()
|
| 418 |
+
if cache:
|
| 419 |
+
cache_files = glob.glob(os.path.join(cache_dir, url_md5 + "_*"))
|
| 420 |
+
if len(cache_files) == 1:
|
| 421 |
+
filename = cache_files[0]
|
| 422 |
+
return filename if return_filename else open(filename, "rb")
|
| 423 |
+
|
| 424 |
+
# Download.
|
| 425 |
+
url_name = None
|
| 426 |
+
url_data = None
|
| 427 |
+
with requests.Session() as session:
|
| 428 |
+
if verbose:
|
| 429 |
+
print("Downloading %s ..." % url, end="", flush=True)
|
| 430 |
+
for attempts_left in reversed(range(num_attempts)):
|
| 431 |
+
try:
|
| 432 |
+
with session.get(url) as res:
|
| 433 |
+
res.raise_for_status()
|
| 434 |
+
if len(res.content) == 0:
|
| 435 |
+
raise IOError("No data received")
|
| 436 |
+
|
| 437 |
+
if len(res.content) < 8192:
|
| 438 |
+
content_str = res.content.decode("utf-8")
|
| 439 |
+
if "download_warning" in res.headers.get("Set-Cookie", ""):
|
| 440 |
+
links = [html.unescape(link) for link in content_str.split('"') if "export=download" in link]
|
| 441 |
+
if len(links) == 1:
|
| 442 |
+
url = requests.compat.urljoin(url, links[0])
|
| 443 |
+
raise IOError("Google Drive virus checker nag")
|
| 444 |
+
if "Google Drive - Quota exceeded" in content_str:
|
| 445 |
+
raise IOError("Google Drive download quota exceeded -- please try again later")
|
| 446 |
+
|
| 447 |
+
match = re.search(r'filename="([^"]*)"', res.headers.get("Content-Disposition", ""))
|
| 448 |
+
url_name = match[1] if match else url
|
| 449 |
+
url_data = res.content
|
| 450 |
+
if verbose:
|
| 451 |
+
print(" done")
|
| 452 |
+
break
|
| 453 |
+
except KeyboardInterrupt:
|
| 454 |
+
raise
|
| 455 |
+
except:
|
| 456 |
+
if not attempts_left:
|
| 457 |
+
if verbose:
|
| 458 |
+
print(" failed")
|
| 459 |
+
raise
|
| 460 |
+
if verbose:
|
| 461 |
+
print(".", end="", flush=True)
|
| 462 |
+
|
| 463 |
+
# Save to cache.
|
| 464 |
+
if cache:
|
| 465 |
+
safe_name = re.sub(r"[^0-9a-zA-Z-._]", "_", url_name)
|
| 466 |
+
cache_file = os.path.join(cache_dir, url_md5 + "_" + safe_name)
|
| 467 |
+
temp_file = os.path.join(cache_dir, "tmp_" + uuid.uuid4().hex + "_" + url_md5 + "_" + safe_name)
|
| 468 |
+
os.makedirs(cache_dir, exist_ok=True)
|
| 469 |
+
with open(temp_file, "wb") as f:
|
| 470 |
+
f.write(url_data)
|
| 471 |
+
os.replace(temp_file, cache_file) # atomic
|
| 472 |
+
if return_filename:
|
| 473 |
+
return cache_file
|
| 474 |
+
|
| 475 |
+
# Return data as file object.
|
| 476 |
+
assert not return_filename
|
| 477 |
+
return io.BytesIO(url_data)
|
draggan/stylegan2/legacy.py
ADDED
|
@@ -0,0 +1,320 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
import click
|
| 10 |
+
import pickle
|
| 11 |
+
import re
|
| 12 |
+
import copy
|
| 13 |
+
import numpy as np
|
| 14 |
+
import torch
|
| 15 |
+
import dnnlib
|
| 16 |
+
from torch_utils import misc
|
| 17 |
+
|
| 18 |
+
#----------------------------------------------------------------------------
|
| 19 |
+
|
| 20 |
+
def load_network_pkl(f, force_fp16=False):
|
| 21 |
+
data = _LegacyUnpickler(f).load()
|
| 22 |
+
|
| 23 |
+
# Legacy TensorFlow pickle => convert.
|
| 24 |
+
if isinstance(data, tuple) and len(data) == 3 and all(isinstance(net, _TFNetworkStub) for net in data):
|
| 25 |
+
tf_G, tf_D, tf_Gs = data
|
| 26 |
+
G = convert_tf_generator(tf_G)
|
| 27 |
+
D = convert_tf_discriminator(tf_D)
|
| 28 |
+
G_ema = convert_tf_generator(tf_Gs)
|
| 29 |
+
data = dict(G=G, D=D, G_ema=G_ema)
|
| 30 |
+
|
| 31 |
+
# Add missing fields.
|
| 32 |
+
if 'training_set_kwargs' not in data:
|
| 33 |
+
data['training_set_kwargs'] = None
|
| 34 |
+
if 'augment_pipe' not in data:
|
| 35 |
+
data['augment_pipe'] = None
|
| 36 |
+
|
| 37 |
+
# Validate contents.
|
| 38 |
+
assert isinstance(data['G'], torch.nn.Module)
|
| 39 |
+
assert isinstance(data['D'], torch.nn.Module)
|
| 40 |
+
assert isinstance(data['G_ema'], torch.nn.Module)
|
| 41 |
+
assert isinstance(data['training_set_kwargs'], (dict, type(None)))
|
| 42 |
+
assert isinstance(data['augment_pipe'], (torch.nn.Module, type(None)))
|
| 43 |
+
|
| 44 |
+
# Force FP16.
|
| 45 |
+
if force_fp16:
|
| 46 |
+
for key in ['G', 'D', 'G_ema']:
|
| 47 |
+
old = data[key]
|
| 48 |
+
kwargs = copy.deepcopy(old.init_kwargs)
|
| 49 |
+
if key.startswith('G'):
|
| 50 |
+
kwargs.synthesis_kwargs = dnnlib.EasyDict(kwargs.get('synthesis_kwargs', {}))
|
| 51 |
+
kwargs.synthesis_kwargs.num_fp16_res = 4
|
| 52 |
+
kwargs.synthesis_kwargs.conv_clamp = 256
|
| 53 |
+
if key.startswith('D'):
|
| 54 |
+
kwargs.num_fp16_res = 4
|
| 55 |
+
kwargs.conv_clamp = 256
|
| 56 |
+
if kwargs != old.init_kwargs:
|
| 57 |
+
new = type(old)(**kwargs).eval().requires_grad_(False)
|
| 58 |
+
misc.copy_params_and_buffers(old, new, require_all=True)
|
| 59 |
+
data[key] = new
|
| 60 |
+
return data
|
| 61 |
+
|
| 62 |
+
#----------------------------------------------------------------------------
|
| 63 |
+
|
| 64 |
+
class _TFNetworkStub(dnnlib.EasyDict):
|
| 65 |
+
pass
|
| 66 |
+
|
| 67 |
+
class _LegacyUnpickler(pickle.Unpickler):
|
| 68 |
+
def find_class(self, module, name):
|
| 69 |
+
if module == 'dnnlib.tflib.network' and name == 'Network':
|
| 70 |
+
return _TFNetworkStub
|
| 71 |
+
return super().find_class(module, name)
|
| 72 |
+
|
| 73 |
+
#----------------------------------------------------------------------------
|
| 74 |
+
|
| 75 |
+
def _collect_tf_params(tf_net):
|
| 76 |
+
# pylint: disable=protected-access
|
| 77 |
+
tf_params = dict()
|
| 78 |
+
def recurse(prefix, tf_net):
|
| 79 |
+
for name, value in tf_net.variables:
|
| 80 |
+
tf_params[prefix + name] = value
|
| 81 |
+
for name, comp in tf_net.components.items():
|
| 82 |
+
recurse(prefix + name + '/', comp)
|
| 83 |
+
recurse('', tf_net)
|
| 84 |
+
return tf_params
|
| 85 |
+
|
| 86 |
+
#----------------------------------------------------------------------------
|
| 87 |
+
|
| 88 |
+
def _populate_module_params(module, *patterns):
|
| 89 |
+
for name, tensor in misc.named_params_and_buffers(module):
|
| 90 |
+
found = False
|
| 91 |
+
value = None
|
| 92 |
+
for pattern, value_fn in zip(patterns[0::2], patterns[1::2]):
|
| 93 |
+
match = re.fullmatch(pattern, name)
|
| 94 |
+
if match:
|
| 95 |
+
found = True
|
| 96 |
+
if value_fn is not None:
|
| 97 |
+
value = value_fn(*match.groups())
|
| 98 |
+
break
|
| 99 |
+
try:
|
| 100 |
+
assert found
|
| 101 |
+
if value is not None:
|
| 102 |
+
tensor.copy_(torch.from_numpy(np.array(value)))
|
| 103 |
+
except:
|
| 104 |
+
print(name, list(tensor.shape))
|
| 105 |
+
raise
|
| 106 |
+
|
| 107 |
+
#----------------------------------------------------------------------------
|
| 108 |
+
|
| 109 |
+
def convert_tf_generator(tf_G):
|
| 110 |
+
if tf_G.version < 4:
|
| 111 |
+
raise ValueError('TensorFlow pickle version too low')
|
| 112 |
+
|
| 113 |
+
# Collect kwargs.
|
| 114 |
+
tf_kwargs = tf_G.static_kwargs
|
| 115 |
+
known_kwargs = set()
|
| 116 |
+
def kwarg(tf_name, default=None, none=None):
|
| 117 |
+
known_kwargs.add(tf_name)
|
| 118 |
+
val = tf_kwargs.get(tf_name, default)
|
| 119 |
+
return val if val is not None else none
|
| 120 |
+
|
| 121 |
+
# Convert kwargs.
|
| 122 |
+
kwargs = dnnlib.EasyDict(
|
| 123 |
+
z_dim = kwarg('latent_size', 512),
|
| 124 |
+
c_dim = kwarg('label_size', 0),
|
| 125 |
+
w_dim = kwarg('dlatent_size', 512),
|
| 126 |
+
img_resolution = kwarg('resolution', 1024),
|
| 127 |
+
img_channels = kwarg('num_channels', 3),
|
| 128 |
+
mapping_kwargs = dnnlib.EasyDict(
|
| 129 |
+
num_layers = kwarg('mapping_layers', 8),
|
| 130 |
+
embed_features = kwarg('label_fmaps', None),
|
| 131 |
+
layer_features = kwarg('mapping_fmaps', None),
|
| 132 |
+
activation = kwarg('mapping_nonlinearity', 'lrelu'),
|
| 133 |
+
lr_multiplier = kwarg('mapping_lrmul', 0.01),
|
| 134 |
+
w_avg_beta = kwarg('w_avg_beta', 0.995, none=1),
|
| 135 |
+
),
|
| 136 |
+
synthesis_kwargs = dnnlib.EasyDict(
|
| 137 |
+
channel_base = kwarg('fmap_base', 16384) * 2,
|
| 138 |
+
channel_max = kwarg('fmap_max', 512),
|
| 139 |
+
num_fp16_res = kwarg('num_fp16_res', 0),
|
| 140 |
+
conv_clamp = kwarg('conv_clamp', None),
|
| 141 |
+
architecture = kwarg('architecture', 'skip'),
|
| 142 |
+
resample_filter = kwarg('resample_kernel', [1,3,3,1]),
|
| 143 |
+
use_noise = kwarg('use_noise', True),
|
| 144 |
+
activation = kwarg('nonlinearity', 'lrelu'),
|
| 145 |
+
),
|
| 146 |
+
)
|
| 147 |
+
|
| 148 |
+
# Check for unknown kwargs.
|
| 149 |
+
kwarg('truncation_psi')
|
| 150 |
+
kwarg('truncation_cutoff')
|
| 151 |
+
kwarg('style_mixing_prob')
|
| 152 |
+
kwarg('structure')
|
| 153 |
+
unknown_kwargs = list(set(tf_kwargs.keys()) - known_kwargs)
|
| 154 |
+
if len(unknown_kwargs) > 0:
|
| 155 |
+
raise ValueError('Unknown TensorFlow kwarg', unknown_kwargs[0])
|
| 156 |
+
|
| 157 |
+
# Collect params.
|
| 158 |
+
tf_params = _collect_tf_params(tf_G)
|
| 159 |
+
for name, value in list(tf_params.items()):
|
| 160 |
+
match = re.fullmatch(r'ToRGB_lod(\d+)/(.*)', name)
|
| 161 |
+
if match:
|
| 162 |
+
r = kwargs.img_resolution // (2 ** int(match.group(1)))
|
| 163 |
+
tf_params[f'{r}x{r}/ToRGB/{match.group(2)}'] = value
|
| 164 |
+
kwargs.synthesis.kwargs.architecture = 'orig'
|
| 165 |
+
#for name, value in tf_params.items(): print(f'{name:<50s}{list(value.shape)}')
|
| 166 |
+
|
| 167 |
+
# Convert params.
|
| 168 |
+
from training import networks
|
| 169 |
+
G = networks.Generator(**kwargs).eval().requires_grad_(False)
|
| 170 |
+
# pylint: disable=unnecessary-lambda
|
| 171 |
+
_populate_module_params(G,
|
| 172 |
+
r'mapping\.w_avg', lambda: tf_params[f'dlatent_avg'],
|
| 173 |
+
r'mapping\.embed\.weight', lambda: tf_params[f'mapping/LabelEmbed/weight'].transpose(),
|
| 174 |
+
r'mapping\.embed\.bias', lambda: tf_params[f'mapping/LabelEmbed/bias'],
|
| 175 |
+
r'mapping\.fc(\d+)\.weight', lambda i: tf_params[f'mapping/Dense{i}/weight'].transpose(),
|
| 176 |
+
r'mapping\.fc(\d+)\.bias', lambda i: tf_params[f'mapping/Dense{i}/bias'],
|
| 177 |
+
r'synthesis\.b4\.const', lambda: tf_params[f'synthesis/4x4/Const/const'][0],
|
| 178 |
+
r'synthesis\.b4\.conv1\.weight', lambda: tf_params[f'synthesis/4x4/Conv/weight'].transpose(3, 2, 0, 1),
|
| 179 |
+
r'synthesis\.b4\.conv1\.bias', lambda: tf_params[f'synthesis/4x4/Conv/bias'],
|
| 180 |
+
r'synthesis\.b4\.conv1\.noise_const', lambda: tf_params[f'synthesis/noise0'][0, 0],
|
| 181 |
+
r'synthesis\.b4\.conv1\.noise_strength', lambda: tf_params[f'synthesis/4x4/Conv/noise_strength'],
|
| 182 |
+
r'synthesis\.b4\.conv1\.affine\.weight', lambda: tf_params[f'synthesis/4x4/Conv/mod_weight'].transpose(),
|
| 183 |
+
r'synthesis\.b4\.conv1\.affine\.bias', lambda: tf_params[f'synthesis/4x4/Conv/mod_bias'] + 1,
|
| 184 |
+
r'synthesis\.b(\d+)\.conv0\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/Conv0_up/weight'][::-1, ::-1].transpose(3, 2, 0, 1),
|
| 185 |
+
r'synthesis\.b(\d+)\.conv0\.bias', lambda r: tf_params[f'synthesis/{r}x{r}/Conv0_up/bias'],
|
| 186 |
+
r'synthesis\.b(\d+)\.conv0\.noise_const', lambda r: tf_params[f'synthesis/noise{int(np.log2(int(r)))*2-5}'][0, 0],
|
| 187 |
+
r'synthesis\.b(\d+)\.conv0\.noise_strength', lambda r: tf_params[f'synthesis/{r}x{r}/Conv0_up/noise_strength'],
|
| 188 |
+
r'synthesis\.b(\d+)\.conv0\.affine\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/Conv0_up/mod_weight'].transpose(),
|
| 189 |
+
r'synthesis\.b(\d+)\.conv0\.affine\.bias', lambda r: tf_params[f'synthesis/{r}x{r}/Conv0_up/mod_bias'] + 1,
|
| 190 |
+
r'synthesis\.b(\d+)\.conv1\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/Conv1/weight'].transpose(3, 2, 0, 1),
|
| 191 |
+
r'synthesis\.b(\d+)\.conv1\.bias', lambda r: tf_params[f'synthesis/{r}x{r}/Conv1/bias'],
|
| 192 |
+
r'synthesis\.b(\d+)\.conv1\.noise_const', lambda r: tf_params[f'synthesis/noise{int(np.log2(int(r)))*2-4}'][0, 0],
|
| 193 |
+
r'synthesis\.b(\d+)\.conv1\.noise_strength', lambda r: tf_params[f'synthesis/{r}x{r}/Conv1/noise_strength'],
|
| 194 |
+
r'synthesis\.b(\d+)\.conv1\.affine\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/Conv1/mod_weight'].transpose(),
|
| 195 |
+
r'synthesis\.b(\d+)\.conv1\.affine\.bias', lambda r: tf_params[f'synthesis/{r}x{r}/Conv1/mod_bias'] + 1,
|
| 196 |
+
r'synthesis\.b(\d+)\.torgb\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/ToRGB/weight'].transpose(3, 2, 0, 1),
|
| 197 |
+
r'synthesis\.b(\d+)\.torgb\.bias', lambda r: tf_params[f'synthesis/{r}x{r}/ToRGB/bias'],
|
| 198 |
+
r'synthesis\.b(\d+)\.torgb\.affine\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/ToRGB/mod_weight'].transpose(),
|
| 199 |
+
r'synthesis\.b(\d+)\.torgb\.affine\.bias', lambda r: tf_params[f'synthesis/{r}x{r}/ToRGB/mod_bias'] + 1,
|
| 200 |
+
r'synthesis\.b(\d+)\.skip\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/Skip/weight'][::-1, ::-1].transpose(3, 2, 0, 1),
|
| 201 |
+
r'.*\.resample_filter', None,
|
| 202 |
+
)
|
| 203 |
+
return G
|
| 204 |
+
|
| 205 |
+
#----------------------------------------------------------------------------
|
| 206 |
+
|
| 207 |
+
def convert_tf_discriminator(tf_D):
|
| 208 |
+
if tf_D.version < 4:
|
| 209 |
+
raise ValueError('TensorFlow pickle version too low')
|
| 210 |
+
|
| 211 |
+
# Collect kwargs.
|
| 212 |
+
tf_kwargs = tf_D.static_kwargs
|
| 213 |
+
known_kwargs = set()
|
| 214 |
+
def kwarg(tf_name, default=None):
|
| 215 |
+
known_kwargs.add(tf_name)
|
| 216 |
+
return tf_kwargs.get(tf_name, default)
|
| 217 |
+
|
| 218 |
+
# Convert kwargs.
|
| 219 |
+
kwargs = dnnlib.EasyDict(
|
| 220 |
+
c_dim = kwarg('label_size', 0),
|
| 221 |
+
img_resolution = kwarg('resolution', 1024),
|
| 222 |
+
img_channels = kwarg('num_channels', 3),
|
| 223 |
+
architecture = kwarg('architecture', 'resnet'),
|
| 224 |
+
channel_base = kwarg('fmap_base', 16384) * 2,
|
| 225 |
+
channel_max = kwarg('fmap_max', 512),
|
| 226 |
+
num_fp16_res = kwarg('num_fp16_res', 0),
|
| 227 |
+
conv_clamp = kwarg('conv_clamp', None),
|
| 228 |
+
cmap_dim = kwarg('mapping_fmaps', None),
|
| 229 |
+
block_kwargs = dnnlib.EasyDict(
|
| 230 |
+
activation = kwarg('nonlinearity', 'lrelu'),
|
| 231 |
+
resample_filter = kwarg('resample_kernel', [1,3,3,1]),
|
| 232 |
+
freeze_layers = kwarg('freeze_layers', 0),
|
| 233 |
+
),
|
| 234 |
+
mapping_kwargs = dnnlib.EasyDict(
|
| 235 |
+
num_layers = kwarg('mapping_layers', 0),
|
| 236 |
+
embed_features = kwarg('mapping_fmaps', None),
|
| 237 |
+
layer_features = kwarg('mapping_fmaps', None),
|
| 238 |
+
activation = kwarg('nonlinearity', 'lrelu'),
|
| 239 |
+
lr_multiplier = kwarg('mapping_lrmul', 0.1),
|
| 240 |
+
),
|
| 241 |
+
epilogue_kwargs = dnnlib.EasyDict(
|
| 242 |
+
mbstd_group_size = kwarg('mbstd_group_size', None),
|
| 243 |
+
mbstd_num_channels = kwarg('mbstd_num_features', 1),
|
| 244 |
+
activation = kwarg('nonlinearity', 'lrelu'),
|
| 245 |
+
),
|
| 246 |
+
)
|
| 247 |
+
|
| 248 |
+
# Check for unknown kwargs.
|
| 249 |
+
kwarg('structure')
|
| 250 |
+
unknown_kwargs = list(set(tf_kwargs.keys()) - known_kwargs)
|
| 251 |
+
if len(unknown_kwargs) > 0:
|
| 252 |
+
raise ValueError('Unknown TensorFlow kwarg', unknown_kwargs[0])
|
| 253 |
+
|
| 254 |
+
# Collect params.
|
| 255 |
+
tf_params = _collect_tf_params(tf_D)
|
| 256 |
+
for name, value in list(tf_params.items()):
|
| 257 |
+
match = re.fullmatch(r'FromRGB_lod(\d+)/(.*)', name)
|
| 258 |
+
if match:
|
| 259 |
+
r = kwargs.img_resolution // (2 ** int(match.group(1)))
|
| 260 |
+
tf_params[f'{r}x{r}/FromRGB/{match.group(2)}'] = value
|
| 261 |
+
kwargs.architecture = 'orig'
|
| 262 |
+
#for name, value in tf_params.items(): print(f'{name:<50s}{list(value.shape)}')
|
| 263 |
+
|
| 264 |
+
# Convert params.
|
| 265 |
+
from training import networks
|
| 266 |
+
D = networks.Discriminator(**kwargs).eval().requires_grad_(False)
|
| 267 |
+
# pylint: disable=unnecessary-lambda
|
| 268 |
+
_populate_module_params(D,
|
| 269 |
+
r'b(\d+)\.fromrgb\.weight', lambda r: tf_params[f'{r}x{r}/FromRGB/weight'].transpose(3, 2, 0, 1),
|
| 270 |
+
r'b(\d+)\.fromrgb\.bias', lambda r: tf_params[f'{r}x{r}/FromRGB/bias'],
|
| 271 |
+
r'b(\d+)\.conv(\d+)\.weight', lambda r, i: tf_params[f'{r}x{r}/Conv{i}{["","_down"][int(i)]}/weight'].transpose(3, 2, 0, 1),
|
| 272 |
+
r'b(\d+)\.conv(\d+)\.bias', lambda r, i: tf_params[f'{r}x{r}/Conv{i}{["","_down"][int(i)]}/bias'],
|
| 273 |
+
r'b(\d+)\.skip\.weight', lambda r: tf_params[f'{r}x{r}/Skip/weight'].transpose(3, 2, 0, 1),
|
| 274 |
+
r'mapping\.embed\.weight', lambda: tf_params[f'LabelEmbed/weight'].transpose(),
|
| 275 |
+
r'mapping\.embed\.bias', lambda: tf_params[f'LabelEmbed/bias'],
|
| 276 |
+
r'mapping\.fc(\d+)\.weight', lambda i: tf_params[f'Mapping{i}/weight'].transpose(),
|
| 277 |
+
r'mapping\.fc(\d+)\.bias', lambda i: tf_params[f'Mapping{i}/bias'],
|
| 278 |
+
r'b4\.conv\.weight', lambda: tf_params[f'4x4/Conv/weight'].transpose(3, 2, 0, 1),
|
| 279 |
+
r'b4\.conv\.bias', lambda: tf_params[f'4x4/Conv/bias'],
|
| 280 |
+
r'b4\.fc\.weight', lambda: tf_params[f'4x4/Dense0/weight'].transpose(),
|
| 281 |
+
r'b4\.fc\.bias', lambda: tf_params[f'4x4/Dense0/bias'],
|
| 282 |
+
r'b4\.out\.weight', lambda: tf_params[f'Output/weight'].transpose(),
|
| 283 |
+
r'b4\.out\.bias', lambda: tf_params[f'Output/bias'],
|
| 284 |
+
r'.*\.resample_filter', None,
|
| 285 |
+
)
|
| 286 |
+
return D
|
| 287 |
+
|
| 288 |
+
#----------------------------------------------------------------------------
|
| 289 |
+
|
| 290 |
+
@click.command()
|
| 291 |
+
@click.option('--source', help='Input pickle', required=True, metavar='PATH')
|
| 292 |
+
@click.option('--dest', help='Output pickle', required=True, metavar='PATH')
|
| 293 |
+
@click.option('--force-fp16', help='Force the networks to use FP16', type=bool, default=False, metavar='BOOL', show_default=True)
|
| 294 |
+
def convert_network_pickle(source, dest, force_fp16):
|
| 295 |
+
"""Convert legacy network pickle into the native PyTorch format.
|
| 296 |
+
|
| 297 |
+
The tool is able to load the main network configurations exported using the TensorFlow version of StyleGAN2 or StyleGAN2-ADA.
|
| 298 |
+
It does not support e.g. StyleGAN2-ADA comparison methods, StyleGAN2 configs A-D, or StyleGAN1 networks.
|
| 299 |
+
|
| 300 |
+
Example:
|
| 301 |
+
|
| 302 |
+
\b
|
| 303 |
+
python legacy.py \\
|
| 304 |
+
--source=https://nvlabs-fi-cdn.nvidia.com/stylegan2/networks/stylegan2-cat-config-f.pkl \\
|
| 305 |
+
--dest=stylegan2-cat-config-f.pkl
|
| 306 |
+
"""
|
| 307 |
+
print(f'Loading "{source}"...')
|
| 308 |
+
with dnnlib.util.open_url(source) as f:
|
| 309 |
+
data = load_network_pkl(f, force_fp16=force_fp16)
|
| 310 |
+
print(f'Saving "{dest}"...')
|
| 311 |
+
with open(dest, 'wb') as f:
|
| 312 |
+
pickle.dump(data, f)
|
| 313 |
+
print('Done.')
|
| 314 |
+
|
| 315 |
+
#----------------------------------------------------------------------------
|
| 316 |
+
|
| 317 |
+
if __name__ == "__main__":
|
| 318 |
+
convert_network_pickle() # pylint: disable=no-value-for-parameter
|
| 319 |
+
|
| 320 |
+
#----------------------------------------------------------------------------
|
draggan/stylegan2/torch_utils/__init__.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
# empty
|
draggan/stylegan2/torch_utils/custom_ops.py
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
import os
|
| 10 |
+
import glob
|
| 11 |
+
import torch
|
| 12 |
+
import torch.utils.cpp_extension
|
| 13 |
+
import importlib
|
| 14 |
+
import hashlib
|
| 15 |
+
import shutil
|
| 16 |
+
from pathlib import Path
|
| 17 |
+
|
| 18 |
+
from torch.utils.file_baton import FileBaton
|
| 19 |
+
|
| 20 |
+
#----------------------------------------------------------------------------
|
| 21 |
+
# Global options.
|
| 22 |
+
|
| 23 |
+
verbosity = 'brief' # Verbosity level: 'none', 'brief', 'full'
|
| 24 |
+
|
| 25 |
+
#----------------------------------------------------------------------------
|
| 26 |
+
# Internal helper funcs.
|
| 27 |
+
|
| 28 |
+
def _find_compiler_bindir():
|
| 29 |
+
patterns = [
|
| 30 |
+
'C:/Program Files (x86)/Microsoft Visual Studio/*/Professional/VC/Tools/MSVC/*/bin/Hostx64/x64',
|
| 31 |
+
'C:/Program Files (x86)/Microsoft Visual Studio/*/BuildTools/VC/Tools/MSVC/*/bin/Hostx64/x64',
|
| 32 |
+
'C:/Program Files (x86)/Microsoft Visual Studio/*/Community/VC/Tools/MSVC/*/bin/Hostx64/x64',
|
| 33 |
+
'C:/Program Files (x86)/Microsoft Visual Studio */vc/bin',
|
| 34 |
+
]
|
| 35 |
+
for pattern in patterns:
|
| 36 |
+
matches = sorted(glob.glob(pattern))
|
| 37 |
+
if len(matches):
|
| 38 |
+
return matches[-1]
|
| 39 |
+
return None
|
| 40 |
+
|
| 41 |
+
#----------------------------------------------------------------------------
|
| 42 |
+
# Main entry point for compiling and loading C++/CUDA plugins.
|
| 43 |
+
|
| 44 |
+
_cached_plugins = dict()
|
| 45 |
+
|
| 46 |
+
def get_plugin(module_name, sources, **build_kwargs):
|
| 47 |
+
assert verbosity in ['none', 'brief', 'full']
|
| 48 |
+
|
| 49 |
+
# Already cached?
|
| 50 |
+
if module_name in _cached_plugins:
|
| 51 |
+
return _cached_plugins[module_name]
|
| 52 |
+
|
| 53 |
+
# Print status.
|
| 54 |
+
if verbosity == 'full':
|
| 55 |
+
print(f'Setting up PyTorch plugin "{module_name}"...')
|
| 56 |
+
elif verbosity == 'brief':
|
| 57 |
+
print(f'Setting up PyTorch plugin "{module_name}"... ', end='', flush=True)
|
| 58 |
+
|
| 59 |
+
try: # pylint: disable=too-many-nested-blocks
|
| 60 |
+
# Make sure we can find the necessary compiler binaries.
|
| 61 |
+
if os.name == 'nt' and os.system("where cl.exe >nul 2>nul") != 0:
|
| 62 |
+
compiler_bindir = _find_compiler_bindir()
|
| 63 |
+
if compiler_bindir is None:
|
| 64 |
+
raise RuntimeError(f'Could not find MSVC/GCC/CLANG installation on this computer. Check _find_compiler_bindir() in "{__file__}".')
|
| 65 |
+
os.environ['PATH'] += ';' + compiler_bindir
|
| 66 |
+
|
| 67 |
+
# Compile and load.
|
| 68 |
+
verbose_build = (verbosity == 'full')
|
| 69 |
+
|
| 70 |
+
# Incremental build md5sum trickery. Copies all the input source files
|
| 71 |
+
# into a cached build directory under a combined md5 digest of the input
|
| 72 |
+
# source files. Copying is done only if the combined digest has changed.
|
| 73 |
+
# This keeps input file timestamps and filenames the same as in previous
|
| 74 |
+
# extension builds, allowing for fast incremental rebuilds.
|
| 75 |
+
#
|
| 76 |
+
# This optimization is done only in case all the source files reside in
|
| 77 |
+
# a single directory (just for simplicity) and if the TORCH_EXTENSIONS_DIR
|
| 78 |
+
# environment variable is set (we take this as a signal that the user
|
| 79 |
+
# actually cares about this.)
|
| 80 |
+
source_dirs_set = set(os.path.dirname(source) for source in sources)
|
| 81 |
+
if len(source_dirs_set) == 1 and ('TORCH_EXTENSIONS_DIR' in os.environ):
|
| 82 |
+
all_source_files = sorted(list(x for x in Path(list(source_dirs_set)[0]).iterdir() if x.is_file()))
|
| 83 |
+
|
| 84 |
+
# Compute a combined hash digest for all source files in the same
|
| 85 |
+
# custom op directory (usually .cu, .cpp, .py and .h files).
|
| 86 |
+
hash_md5 = hashlib.md5()
|
| 87 |
+
for src in all_source_files:
|
| 88 |
+
with open(src, 'rb') as f:
|
| 89 |
+
hash_md5.update(f.read())
|
| 90 |
+
build_dir = torch.utils.cpp_extension._get_build_directory(module_name, verbose=verbose_build) # pylint: disable=protected-access
|
| 91 |
+
digest_build_dir = os.path.join(build_dir, hash_md5.hexdigest())
|
| 92 |
+
|
| 93 |
+
if not os.path.isdir(digest_build_dir):
|
| 94 |
+
os.makedirs(digest_build_dir, exist_ok=True)
|
| 95 |
+
baton = FileBaton(os.path.join(digest_build_dir, 'lock'))
|
| 96 |
+
if baton.try_acquire():
|
| 97 |
+
try:
|
| 98 |
+
for src in all_source_files:
|
| 99 |
+
shutil.copyfile(src, os.path.join(digest_build_dir, os.path.basename(src)))
|
| 100 |
+
finally:
|
| 101 |
+
baton.release()
|
| 102 |
+
else:
|
| 103 |
+
# Someone else is copying source files under the digest dir,
|
| 104 |
+
# wait until done and continue.
|
| 105 |
+
baton.wait()
|
| 106 |
+
digest_sources = [os.path.join(digest_build_dir, os.path.basename(x)) for x in sources]
|
| 107 |
+
torch.utils.cpp_extension.load(name=module_name, build_directory=build_dir,
|
| 108 |
+
verbose=verbose_build, sources=digest_sources, **build_kwargs)
|
| 109 |
+
else:
|
| 110 |
+
torch.utils.cpp_extension.load(name=module_name, verbose=verbose_build, sources=sources, **build_kwargs)
|
| 111 |
+
module = importlib.import_module(module_name)
|
| 112 |
+
|
| 113 |
+
except:
|
| 114 |
+
if verbosity == 'brief':
|
| 115 |
+
print('Failed!')
|
| 116 |
+
raise
|
| 117 |
+
|
| 118 |
+
# Print status and add to cache.
|
| 119 |
+
if verbosity == 'full':
|
| 120 |
+
print(f'Done setting up PyTorch plugin "{module_name}".')
|
| 121 |
+
elif verbosity == 'brief':
|
| 122 |
+
print('Done.')
|
| 123 |
+
_cached_plugins[module_name] = module
|
| 124 |
+
return module
|
| 125 |
+
|
| 126 |
+
#----------------------------------------------------------------------------
|
draggan/stylegan2/torch_utils/misc.py
ADDED
|
@@ -0,0 +1,262 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
import re
|
| 10 |
+
import contextlib
|
| 11 |
+
import numpy as np
|
| 12 |
+
import torch
|
| 13 |
+
import warnings
|
| 14 |
+
import dnnlib
|
| 15 |
+
|
| 16 |
+
#----------------------------------------------------------------------------
|
| 17 |
+
# Cached construction of constant tensors. Avoids CPU=>GPU copy when the
|
| 18 |
+
# same constant is used multiple times.
|
| 19 |
+
|
| 20 |
+
_constant_cache = dict()
|
| 21 |
+
|
| 22 |
+
def constant(value, shape=None, dtype=None, device=None, memory_format=None):
|
| 23 |
+
value = np.asarray(value)
|
| 24 |
+
if shape is not None:
|
| 25 |
+
shape = tuple(shape)
|
| 26 |
+
if dtype is None:
|
| 27 |
+
dtype = torch.get_default_dtype()
|
| 28 |
+
if device is None:
|
| 29 |
+
device = torch.device('cpu')
|
| 30 |
+
if memory_format is None:
|
| 31 |
+
memory_format = torch.contiguous_format
|
| 32 |
+
|
| 33 |
+
key = (value.shape, value.dtype, value.tobytes(), shape, dtype, device, memory_format)
|
| 34 |
+
tensor = _constant_cache.get(key, None)
|
| 35 |
+
if tensor is None:
|
| 36 |
+
tensor = torch.as_tensor(value.copy(), dtype=dtype, device=device)
|
| 37 |
+
if shape is not None:
|
| 38 |
+
tensor, _ = torch.broadcast_tensors(tensor, torch.empty(shape))
|
| 39 |
+
tensor = tensor.contiguous(memory_format=memory_format)
|
| 40 |
+
_constant_cache[key] = tensor
|
| 41 |
+
return tensor
|
| 42 |
+
|
| 43 |
+
#----------------------------------------------------------------------------
|
| 44 |
+
# Replace NaN/Inf with specified numerical values.
|
| 45 |
+
|
| 46 |
+
try:
|
| 47 |
+
nan_to_num = torch.nan_to_num # 1.8.0a0
|
| 48 |
+
except AttributeError:
|
| 49 |
+
def nan_to_num(input, nan=0.0, posinf=None, neginf=None, *, out=None): # pylint: disable=redefined-builtin
|
| 50 |
+
assert isinstance(input, torch.Tensor)
|
| 51 |
+
if posinf is None:
|
| 52 |
+
posinf = torch.finfo(input.dtype).max
|
| 53 |
+
if neginf is None:
|
| 54 |
+
neginf = torch.finfo(input.dtype).min
|
| 55 |
+
assert nan == 0
|
| 56 |
+
return torch.clamp(input.unsqueeze(0).nansum(0), min=neginf, max=posinf, out=out)
|
| 57 |
+
|
| 58 |
+
#----------------------------------------------------------------------------
|
| 59 |
+
# Symbolic assert.
|
| 60 |
+
|
| 61 |
+
try:
|
| 62 |
+
symbolic_assert = torch._assert # 1.8.0a0 # pylint: disable=protected-access
|
| 63 |
+
except AttributeError:
|
| 64 |
+
symbolic_assert = torch.Assert # 1.7.0
|
| 65 |
+
|
| 66 |
+
#----------------------------------------------------------------------------
|
| 67 |
+
# Context manager to suppress known warnings in torch.jit.trace().
|
| 68 |
+
|
| 69 |
+
class suppress_tracer_warnings(warnings.catch_warnings):
|
| 70 |
+
def __enter__(self):
|
| 71 |
+
super().__enter__()
|
| 72 |
+
warnings.simplefilter('ignore', category=torch.jit.TracerWarning)
|
| 73 |
+
return self
|
| 74 |
+
|
| 75 |
+
#----------------------------------------------------------------------------
|
| 76 |
+
# Assert that the shape of a tensor matches the given list of integers.
|
| 77 |
+
# None indicates that the size of a dimension is allowed to vary.
|
| 78 |
+
# Performs symbolic assertion when used in torch.jit.trace().
|
| 79 |
+
|
| 80 |
+
def assert_shape(tensor, ref_shape):
|
| 81 |
+
if tensor.ndim != len(ref_shape):
|
| 82 |
+
raise AssertionError(f'Wrong number of dimensions: got {tensor.ndim}, expected {len(ref_shape)}')
|
| 83 |
+
for idx, (size, ref_size) in enumerate(zip(tensor.shape, ref_shape)):
|
| 84 |
+
if ref_size is None:
|
| 85 |
+
pass
|
| 86 |
+
elif isinstance(ref_size, torch.Tensor):
|
| 87 |
+
with suppress_tracer_warnings(): # as_tensor results are registered as constants
|
| 88 |
+
symbolic_assert(torch.equal(torch.as_tensor(size), ref_size), f'Wrong size for dimension {idx}')
|
| 89 |
+
elif isinstance(size, torch.Tensor):
|
| 90 |
+
with suppress_tracer_warnings(): # as_tensor results are registered as constants
|
| 91 |
+
symbolic_assert(torch.equal(size, torch.as_tensor(ref_size)), f'Wrong size for dimension {idx}: expected {ref_size}')
|
| 92 |
+
elif size != ref_size:
|
| 93 |
+
raise AssertionError(f'Wrong size for dimension {idx}: got {size}, expected {ref_size}')
|
| 94 |
+
|
| 95 |
+
#----------------------------------------------------------------------------
|
| 96 |
+
# Function decorator that calls torch.autograd.profiler.record_function().
|
| 97 |
+
|
| 98 |
+
def profiled_function(fn):
|
| 99 |
+
def decorator(*args, **kwargs):
|
| 100 |
+
with torch.autograd.profiler.record_function(fn.__name__):
|
| 101 |
+
return fn(*args, **kwargs)
|
| 102 |
+
decorator.__name__ = fn.__name__
|
| 103 |
+
return decorator
|
| 104 |
+
|
| 105 |
+
#----------------------------------------------------------------------------
|
| 106 |
+
# Sampler for torch.utils.data.DataLoader that loops over the dataset
|
| 107 |
+
# indefinitely, shuffling items as it goes.
|
| 108 |
+
|
| 109 |
+
class InfiniteSampler(torch.utils.data.Sampler):
|
| 110 |
+
def __init__(self, dataset, rank=0, num_replicas=1, shuffle=True, seed=0, window_size=0.5):
|
| 111 |
+
assert len(dataset) > 0
|
| 112 |
+
assert num_replicas > 0
|
| 113 |
+
assert 0 <= rank < num_replicas
|
| 114 |
+
assert 0 <= window_size <= 1
|
| 115 |
+
super().__init__(dataset)
|
| 116 |
+
self.dataset = dataset
|
| 117 |
+
self.rank = rank
|
| 118 |
+
self.num_replicas = num_replicas
|
| 119 |
+
self.shuffle = shuffle
|
| 120 |
+
self.seed = seed
|
| 121 |
+
self.window_size = window_size
|
| 122 |
+
|
| 123 |
+
def __iter__(self):
|
| 124 |
+
order = np.arange(len(self.dataset))
|
| 125 |
+
rnd = None
|
| 126 |
+
window = 0
|
| 127 |
+
if self.shuffle:
|
| 128 |
+
rnd = np.random.RandomState(self.seed)
|
| 129 |
+
rnd.shuffle(order)
|
| 130 |
+
window = int(np.rint(order.size * self.window_size))
|
| 131 |
+
|
| 132 |
+
idx = 0
|
| 133 |
+
while True:
|
| 134 |
+
i = idx % order.size
|
| 135 |
+
if idx % self.num_replicas == self.rank:
|
| 136 |
+
yield order[i]
|
| 137 |
+
if window >= 2:
|
| 138 |
+
j = (i - rnd.randint(window)) % order.size
|
| 139 |
+
order[i], order[j] = order[j], order[i]
|
| 140 |
+
idx += 1
|
| 141 |
+
|
| 142 |
+
#----------------------------------------------------------------------------
|
| 143 |
+
# Utilities for operating with torch.nn.Module parameters and buffers.
|
| 144 |
+
|
| 145 |
+
def params_and_buffers(module):
|
| 146 |
+
assert isinstance(module, torch.nn.Module)
|
| 147 |
+
return list(module.parameters()) + list(module.buffers())
|
| 148 |
+
|
| 149 |
+
def named_params_and_buffers(module):
|
| 150 |
+
assert isinstance(module, torch.nn.Module)
|
| 151 |
+
return list(module.named_parameters()) + list(module.named_buffers())
|
| 152 |
+
|
| 153 |
+
def copy_params_and_buffers(src_module, dst_module, require_all=False):
|
| 154 |
+
assert isinstance(src_module, torch.nn.Module)
|
| 155 |
+
assert isinstance(dst_module, torch.nn.Module)
|
| 156 |
+
src_tensors = {name: tensor for name, tensor in named_params_and_buffers(src_module)}
|
| 157 |
+
for name, tensor in named_params_and_buffers(dst_module):
|
| 158 |
+
assert (name in src_tensors) or (not require_all)
|
| 159 |
+
if name in src_tensors:
|
| 160 |
+
tensor.copy_(src_tensors[name].detach()).requires_grad_(tensor.requires_grad)
|
| 161 |
+
|
| 162 |
+
#----------------------------------------------------------------------------
|
| 163 |
+
# Context manager for easily enabling/disabling DistributedDataParallel
|
| 164 |
+
# synchronization.
|
| 165 |
+
|
| 166 |
+
@contextlib.contextmanager
|
| 167 |
+
def ddp_sync(module, sync):
|
| 168 |
+
assert isinstance(module, torch.nn.Module)
|
| 169 |
+
if sync or not isinstance(module, torch.nn.parallel.DistributedDataParallel):
|
| 170 |
+
yield
|
| 171 |
+
else:
|
| 172 |
+
with module.no_sync():
|
| 173 |
+
yield
|
| 174 |
+
|
| 175 |
+
#----------------------------------------------------------------------------
|
| 176 |
+
# Check DistributedDataParallel consistency across processes.
|
| 177 |
+
|
| 178 |
+
def check_ddp_consistency(module, ignore_regex=None):
|
| 179 |
+
assert isinstance(module, torch.nn.Module)
|
| 180 |
+
for name, tensor in named_params_and_buffers(module):
|
| 181 |
+
fullname = type(module).__name__ + '.' + name
|
| 182 |
+
if ignore_regex is not None and re.fullmatch(ignore_regex, fullname):
|
| 183 |
+
continue
|
| 184 |
+
tensor = tensor.detach()
|
| 185 |
+
other = tensor.clone()
|
| 186 |
+
torch.distributed.broadcast(tensor=other, src=0)
|
| 187 |
+
assert (nan_to_num(tensor) == nan_to_num(other)).all(), fullname
|
| 188 |
+
|
| 189 |
+
#----------------------------------------------------------------------------
|
| 190 |
+
# Print summary table of module hierarchy.
|
| 191 |
+
|
| 192 |
+
def print_module_summary(module, inputs, max_nesting=3, skip_redundant=True):
|
| 193 |
+
assert isinstance(module, torch.nn.Module)
|
| 194 |
+
assert not isinstance(module, torch.jit.ScriptModule)
|
| 195 |
+
assert isinstance(inputs, (tuple, list))
|
| 196 |
+
|
| 197 |
+
# Register hooks.
|
| 198 |
+
entries = []
|
| 199 |
+
nesting = [0]
|
| 200 |
+
def pre_hook(_mod, _inputs):
|
| 201 |
+
nesting[0] += 1
|
| 202 |
+
def post_hook(mod, _inputs, outputs):
|
| 203 |
+
nesting[0] -= 1
|
| 204 |
+
if nesting[0] <= max_nesting:
|
| 205 |
+
outputs = list(outputs) if isinstance(outputs, (tuple, list)) else [outputs]
|
| 206 |
+
outputs = [t for t in outputs if isinstance(t, torch.Tensor)]
|
| 207 |
+
entries.append(dnnlib.EasyDict(mod=mod, outputs=outputs))
|
| 208 |
+
hooks = [mod.register_forward_pre_hook(pre_hook) for mod in module.modules()]
|
| 209 |
+
hooks += [mod.register_forward_hook(post_hook) for mod in module.modules()]
|
| 210 |
+
|
| 211 |
+
# Run module.
|
| 212 |
+
outputs = module(*inputs)
|
| 213 |
+
for hook in hooks:
|
| 214 |
+
hook.remove()
|
| 215 |
+
|
| 216 |
+
# Identify unique outputs, parameters, and buffers.
|
| 217 |
+
tensors_seen = set()
|
| 218 |
+
for e in entries:
|
| 219 |
+
e.unique_params = [t for t in e.mod.parameters() if id(t) not in tensors_seen]
|
| 220 |
+
e.unique_buffers = [t for t in e.mod.buffers() if id(t) not in tensors_seen]
|
| 221 |
+
e.unique_outputs = [t for t in e.outputs if id(t) not in tensors_seen]
|
| 222 |
+
tensors_seen |= {id(t) for t in e.unique_params + e.unique_buffers + e.unique_outputs}
|
| 223 |
+
|
| 224 |
+
# Filter out redundant entries.
|
| 225 |
+
if skip_redundant:
|
| 226 |
+
entries = [e for e in entries if len(e.unique_params) or len(e.unique_buffers) or len(e.unique_outputs)]
|
| 227 |
+
|
| 228 |
+
# Construct table.
|
| 229 |
+
rows = [[type(module).__name__, 'Parameters', 'Buffers', 'Output shape', 'Datatype']]
|
| 230 |
+
rows += [['---'] * len(rows[0])]
|
| 231 |
+
param_total = 0
|
| 232 |
+
buffer_total = 0
|
| 233 |
+
submodule_names = {mod: name for name, mod in module.named_modules()}
|
| 234 |
+
for e in entries:
|
| 235 |
+
name = '<top-level>' if e.mod is module else submodule_names[e.mod]
|
| 236 |
+
param_size = sum(t.numel() for t in e.unique_params)
|
| 237 |
+
buffer_size = sum(t.numel() for t in e.unique_buffers)
|
| 238 |
+
output_shapes = [str(list(e.outputs[0].shape)) for t in e.outputs]
|
| 239 |
+
output_dtypes = [str(t.dtype).split('.')[-1] for t in e.outputs]
|
| 240 |
+
rows += [[
|
| 241 |
+
name + (':0' if len(e.outputs) >= 2 else ''),
|
| 242 |
+
str(param_size) if param_size else '-',
|
| 243 |
+
str(buffer_size) if buffer_size else '-',
|
| 244 |
+
(output_shapes + ['-'])[0],
|
| 245 |
+
(output_dtypes + ['-'])[0],
|
| 246 |
+
]]
|
| 247 |
+
for idx in range(1, len(e.outputs)):
|
| 248 |
+
rows += [[name + f':{idx}', '-', '-', output_shapes[idx], output_dtypes[idx]]]
|
| 249 |
+
param_total += param_size
|
| 250 |
+
buffer_total += buffer_size
|
| 251 |
+
rows += [['---'] * len(rows[0])]
|
| 252 |
+
rows += [['Total', str(param_total), str(buffer_total), '-', '-']]
|
| 253 |
+
|
| 254 |
+
# Print table.
|
| 255 |
+
widths = [max(len(cell) for cell in column) for column in zip(*rows)]
|
| 256 |
+
print()
|
| 257 |
+
for row in rows:
|
| 258 |
+
print(' '.join(cell + ' ' * (width - len(cell)) for cell, width in zip(row, widths)))
|
| 259 |
+
print()
|
| 260 |
+
return outputs
|
| 261 |
+
|
| 262 |
+
#----------------------------------------------------------------------------
|
draggan/stylegan2/torch_utils/ops/__init__.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
# empty
|
draggan/stylegan2/torch_utils/ops/bias_act.cpp
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
| 2 |
+
//
|
| 3 |
+
// NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
// and proprietary rights in and to this software, related documentation
|
| 5 |
+
// and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
// distribution of this software and related documentation without an express
|
| 7 |
+
// license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
#include <torch/extension.h>
|
| 10 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 11 |
+
#include <c10/cuda/CUDAGuard.h>
|
| 12 |
+
#include "bias_act.h"
|
| 13 |
+
|
| 14 |
+
//------------------------------------------------------------------------
|
| 15 |
+
|
| 16 |
+
static bool has_same_layout(torch::Tensor x, torch::Tensor y)
|
| 17 |
+
{
|
| 18 |
+
if (x.dim() != y.dim())
|
| 19 |
+
return false;
|
| 20 |
+
for (int64_t i = 0; i < x.dim(); i++)
|
| 21 |
+
{
|
| 22 |
+
if (x.size(i) != y.size(i))
|
| 23 |
+
return false;
|
| 24 |
+
if (x.size(i) >= 2 && x.stride(i) != y.stride(i))
|
| 25 |
+
return false;
|
| 26 |
+
}
|
| 27 |
+
return true;
|
| 28 |
+
}
|
| 29 |
+
|
| 30 |
+
//------------------------------------------------------------------------
|
| 31 |
+
|
| 32 |
+
static torch::Tensor bias_act(torch::Tensor x, torch::Tensor b, torch::Tensor xref, torch::Tensor yref, torch::Tensor dy, int grad, int dim, int act, float alpha, float gain, float clamp)
|
| 33 |
+
{
|
| 34 |
+
// Validate arguments.
|
| 35 |
+
TORCH_CHECK(x.is_cuda(), "x must reside on CUDA device");
|
| 36 |
+
TORCH_CHECK(b.numel() == 0 || (b.dtype() == x.dtype() && b.device() == x.device()), "b must have the same dtype and device as x");
|
| 37 |
+
TORCH_CHECK(xref.numel() == 0 || (xref.sizes() == x.sizes() && xref.dtype() == x.dtype() && xref.device() == x.device()), "xref must have the same shape, dtype, and device as x");
|
| 38 |
+
TORCH_CHECK(yref.numel() == 0 || (yref.sizes() == x.sizes() && yref.dtype() == x.dtype() && yref.device() == x.device()), "yref must have the same shape, dtype, and device as x");
|
| 39 |
+
TORCH_CHECK(dy.numel() == 0 || (dy.sizes() == x.sizes() && dy.dtype() == x.dtype() && dy.device() == x.device()), "dy must have the same dtype and device as x");
|
| 40 |
+
TORCH_CHECK(x.numel() <= INT_MAX, "x is too large");
|
| 41 |
+
TORCH_CHECK(b.dim() == 1, "b must have rank 1");
|
| 42 |
+
TORCH_CHECK(b.numel() == 0 || (dim >= 0 && dim < x.dim()), "dim is out of bounds");
|
| 43 |
+
TORCH_CHECK(b.numel() == 0 || b.numel() == x.size(dim), "b has wrong number of elements");
|
| 44 |
+
TORCH_CHECK(grad >= 0, "grad must be non-negative");
|
| 45 |
+
|
| 46 |
+
// Validate layout.
|
| 47 |
+
TORCH_CHECK(x.is_non_overlapping_and_dense(), "x must be non-overlapping and dense");
|
| 48 |
+
TORCH_CHECK(b.is_contiguous(), "b must be contiguous");
|
| 49 |
+
TORCH_CHECK(xref.numel() == 0 || has_same_layout(xref, x), "xref must have the same layout as x");
|
| 50 |
+
TORCH_CHECK(yref.numel() == 0 || has_same_layout(yref, x), "yref must have the same layout as x");
|
| 51 |
+
TORCH_CHECK(dy.numel() == 0 || has_same_layout(dy, x), "dy must have the same layout as x");
|
| 52 |
+
|
| 53 |
+
// Create output tensor.
|
| 54 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(x));
|
| 55 |
+
torch::Tensor y = torch::empty_like(x);
|
| 56 |
+
TORCH_CHECK(has_same_layout(y, x), "y must have the same layout as x");
|
| 57 |
+
|
| 58 |
+
// Initialize CUDA kernel parameters.
|
| 59 |
+
bias_act_kernel_params p;
|
| 60 |
+
p.x = x.data_ptr();
|
| 61 |
+
p.b = (b.numel()) ? b.data_ptr() : NULL;
|
| 62 |
+
p.xref = (xref.numel()) ? xref.data_ptr() : NULL;
|
| 63 |
+
p.yref = (yref.numel()) ? yref.data_ptr() : NULL;
|
| 64 |
+
p.dy = (dy.numel()) ? dy.data_ptr() : NULL;
|
| 65 |
+
p.y = y.data_ptr();
|
| 66 |
+
p.grad = grad;
|
| 67 |
+
p.act = act;
|
| 68 |
+
p.alpha = alpha;
|
| 69 |
+
p.gain = gain;
|
| 70 |
+
p.clamp = clamp;
|
| 71 |
+
p.sizeX = (int)x.numel();
|
| 72 |
+
p.sizeB = (int)b.numel();
|
| 73 |
+
p.stepB = (b.numel()) ? (int)x.stride(dim) : 1;
|
| 74 |
+
|
| 75 |
+
// Choose CUDA kernel.
|
| 76 |
+
void* kernel;
|
| 77 |
+
AT_DISPATCH_FLOATING_TYPES_AND_HALF(x.scalar_type(), "upfirdn2d_cuda", [&]
|
| 78 |
+
{
|
| 79 |
+
kernel = choose_bias_act_kernel<scalar_t>(p);
|
| 80 |
+
});
|
| 81 |
+
TORCH_CHECK(kernel, "no CUDA kernel found for the specified activation func");
|
| 82 |
+
|
| 83 |
+
// Launch CUDA kernel.
|
| 84 |
+
p.loopX = 4;
|
| 85 |
+
int blockSize = 4 * 32;
|
| 86 |
+
int gridSize = (p.sizeX - 1) / (p.loopX * blockSize) + 1;
|
| 87 |
+
void* args[] = {&p};
|
| 88 |
+
AT_CUDA_CHECK(cudaLaunchKernel(kernel, gridSize, blockSize, args, 0, at::cuda::getCurrentCUDAStream()));
|
| 89 |
+
return y;
|
| 90 |
+
}
|
| 91 |
+
|
| 92 |
+
//------------------------------------------------------------------------
|
| 93 |
+
|
| 94 |
+
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m)
|
| 95 |
+
{
|
| 96 |
+
m.def("bias_act", &bias_act);
|
| 97 |
+
}
|
| 98 |
+
|
| 99 |
+
//------------------------------------------------------------------------
|
draggan/stylegan2/torch_utils/ops/bias_act.cu
ADDED
|
@@ -0,0 +1,173 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
| 2 |
+
//
|
| 3 |
+
// NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
// and proprietary rights in and to this software, related documentation
|
| 5 |
+
// and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
// distribution of this software and related documentation without an express
|
| 7 |
+
// license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
#include <c10/util/Half.h>
|
| 10 |
+
#include "bias_act.h"
|
| 11 |
+
|
| 12 |
+
//------------------------------------------------------------------------
|
| 13 |
+
// Helpers.
|
| 14 |
+
|
| 15 |
+
template <class T> struct InternalType;
|
| 16 |
+
template <> struct InternalType<double> { typedef double scalar_t; };
|
| 17 |
+
template <> struct InternalType<float> { typedef float scalar_t; };
|
| 18 |
+
template <> struct InternalType<c10::Half> { typedef float scalar_t; };
|
| 19 |
+
|
| 20 |
+
//------------------------------------------------------------------------
|
| 21 |
+
// CUDA kernel.
|
| 22 |
+
|
| 23 |
+
template <class T, int A>
|
| 24 |
+
__global__ void bias_act_kernel(bias_act_kernel_params p)
|
| 25 |
+
{
|
| 26 |
+
typedef typename InternalType<T>::scalar_t scalar_t;
|
| 27 |
+
int G = p.grad;
|
| 28 |
+
scalar_t alpha = (scalar_t)p.alpha;
|
| 29 |
+
scalar_t gain = (scalar_t)p.gain;
|
| 30 |
+
scalar_t clamp = (scalar_t)p.clamp;
|
| 31 |
+
scalar_t one = (scalar_t)1;
|
| 32 |
+
scalar_t two = (scalar_t)2;
|
| 33 |
+
scalar_t expRange = (scalar_t)80;
|
| 34 |
+
scalar_t halfExpRange = (scalar_t)40;
|
| 35 |
+
scalar_t seluScale = (scalar_t)1.0507009873554804934193349852946;
|
| 36 |
+
scalar_t seluAlpha = (scalar_t)1.6732632423543772848170429916717;
|
| 37 |
+
|
| 38 |
+
// Loop over elements.
|
| 39 |
+
int xi = blockIdx.x * p.loopX * blockDim.x + threadIdx.x;
|
| 40 |
+
for (int loopIdx = 0; loopIdx < p.loopX && xi < p.sizeX; loopIdx++, xi += blockDim.x)
|
| 41 |
+
{
|
| 42 |
+
// Load.
|
| 43 |
+
scalar_t x = (scalar_t)((const T*)p.x)[xi];
|
| 44 |
+
scalar_t b = (p.b) ? (scalar_t)((const T*)p.b)[(xi / p.stepB) % p.sizeB] : 0;
|
| 45 |
+
scalar_t xref = (p.xref) ? (scalar_t)((const T*)p.xref)[xi] : 0;
|
| 46 |
+
scalar_t yref = (p.yref) ? (scalar_t)((const T*)p.yref)[xi] : 0;
|
| 47 |
+
scalar_t dy = (p.dy) ? (scalar_t)((const T*)p.dy)[xi] : one;
|
| 48 |
+
scalar_t yy = (gain != 0) ? yref / gain : 0;
|
| 49 |
+
scalar_t y = 0;
|
| 50 |
+
|
| 51 |
+
// Apply bias.
|
| 52 |
+
((G == 0) ? x : xref) += b;
|
| 53 |
+
|
| 54 |
+
// linear
|
| 55 |
+
if (A == 1)
|
| 56 |
+
{
|
| 57 |
+
if (G == 0) y = x;
|
| 58 |
+
if (G == 1) y = x;
|
| 59 |
+
}
|
| 60 |
+
|
| 61 |
+
// relu
|
| 62 |
+
if (A == 2)
|
| 63 |
+
{
|
| 64 |
+
if (G == 0) y = (x > 0) ? x : 0;
|
| 65 |
+
if (G == 1) y = (yy > 0) ? x : 0;
|
| 66 |
+
}
|
| 67 |
+
|
| 68 |
+
// lrelu
|
| 69 |
+
if (A == 3)
|
| 70 |
+
{
|
| 71 |
+
if (G == 0) y = (x > 0) ? x : x * alpha;
|
| 72 |
+
if (G == 1) y = (yy > 0) ? x : x * alpha;
|
| 73 |
+
}
|
| 74 |
+
|
| 75 |
+
// tanh
|
| 76 |
+
if (A == 4)
|
| 77 |
+
{
|
| 78 |
+
if (G == 0) { scalar_t c = exp(x); scalar_t d = one / c; y = (x < -expRange) ? -one : (x > expRange) ? one : (c - d) / (c + d); }
|
| 79 |
+
if (G == 1) y = x * (one - yy * yy);
|
| 80 |
+
if (G == 2) y = x * (one - yy * yy) * (-two * yy);
|
| 81 |
+
}
|
| 82 |
+
|
| 83 |
+
// sigmoid
|
| 84 |
+
if (A == 5)
|
| 85 |
+
{
|
| 86 |
+
if (G == 0) y = (x < -expRange) ? 0 : one / (exp(-x) + one);
|
| 87 |
+
if (G == 1) y = x * yy * (one - yy);
|
| 88 |
+
if (G == 2) y = x * yy * (one - yy) * (one - two * yy);
|
| 89 |
+
}
|
| 90 |
+
|
| 91 |
+
// elu
|
| 92 |
+
if (A == 6)
|
| 93 |
+
{
|
| 94 |
+
if (G == 0) y = (x >= 0) ? x : exp(x) - one;
|
| 95 |
+
if (G == 1) y = (yy >= 0) ? x : x * (yy + one);
|
| 96 |
+
if (G == 2) y = (yy >= 0) ? 0 : x * (yy + one);
|
| 97 |
+
}
|
| 98 |
+
|
| 99 |
+
// selu
|
| 100 |
+
if (A == 7)
|
| 101 |
+
{
|
| 102 |
+
if (G == 0) y = (x >= 0) ? seluScale * x : (seluScale * seluAlpha) * (exp(x) - one);
|
| 103 |
+
if (G == 1) y = (yy >= 0) ? x * seluScale : x * (yy + seluScale * seluAlpha);
|
| 104 |
+
if (G == 2) y = (yy >= 0) ? 0 : x * (yy + seluScale * seluAlpha);
|
| 105 |
+
}
|
| 106 |
+
|
| 107 |
+
// softplus
|
| 108 |
+
if (A == 8)
|
| 109 |
+
{
|
| 110 |
+
if (G == 0) y = (x > expRange) ? x : log(exp(x) + one);
|
| 111 |
+
if (G == 1) y = x * (one - exp(-yy));
|
| 112 |
+
if (G == 2) { scalar_t c = exp(-yy); y = x * c * (one - c); }
|
| 113 |
+
}
|
| 114 |
+
|
| 115 |
+
// swish
|
| 116 |
+
if (A == 9)
|
| 117 |
+
{
|
| 118 |
+
if (G == 0)
|
| 119 |
+
y = (x < -expRange) ? 0 : x / (exp(-x) + one);
|
| 120 |
+
else
|
| 121 |
+
{
|
| 122 |
+
scalar_t c = exp(xref);
|
| 123 |
+
scalar_t d = c + one;
|
| 124 |
+
if (G == 1)
|
| 125 |
+
y = (xref > halfExpRange) ? x : x * c * (xref + d) / (d * d);
|
| 126 |
+
else
|
| 127 |
+
y = (xref > halfExpRange) ? 0 : x * c * (xref * (two - d) + two * d) / (d * d * d);
|
| 128 |
+
yref = (xref < -expRange) ? 0 : xref / (exp(-xref) + one) * gain;
|
| 129 |
+
}
|
| 130 |
+
}
|
| 131 |
+
|
| 132 |
+
// Apply gain.
|
| 133 |
+
y *= gain * dy;
|
| 134 |
+
|
| 135 |
+
// Clamp.
|
| 136 |
+
if (clamp >= 0)
|
| 137 |
+
{
|
| 138 |
+
if (G == 0)
|
| 139 |
+
y = (y > -clamp & y < clamp) ? y : (y >= 0) ? clamp : -clamp;
|
| 140 |
+
else
|
| 141 |
+
y = (yref > -clamp & yref < clamp) ? y : 0;
|
| 142 |
+
}
|
| 143 |
+
|
| 144 |
+
// Store.
|
| 145 |
+
((T*)p.y)[xi] = (T)y;
|
| 146 |
+
}
|
| 147 |
+
}
|
| 148 |
+
|
| 149 |
+
//------------------------------------------------------------------------
|
| 150 |
+
// CUDA kernel selection.
|
| 151 |
+
|
| 152 |
+
template <class T> void* choose_bias_act_kernel(const bias_act_kernel_params& p)
|
| 153 |
+
{
|
| 154 |
+
if (p.act == 1) return (void*)bias_act_kernel<T, 1>;
|
| 155 |
+
if (p.act == 2) return (void*)bias_act_kernel<T, 2>;
|
| 156 |
+
if (p.act == 3) return (void*)bias_act_kernel<T, 3>;
|
| 157 |
+
if (p.act == 4) return (void*)bias_act_kernel<T, 4>;
|
| 158 |
+
if (p.act == 5) return (void*)bias_act_kernel<T, 5>;
|
| 159 |
+
if (p.act == 6) return (void*)bias_act_kernel<T, 6>;
|
| 160 |
+
if (p.act == 7) return (void*)bias_act_kernel<T, 7>;
|
| 161 |
+
if (p.act == 8) return (void*)bias_act_kernel<T, 8>;
|
| 162 |
+
if (p.act == 9) return (void*)bias_act_kernel<T, 9>;
|
| 163 |
+
return NULL;
|
| 164 |
+
}
|
| 165 |
+
|
| 166 |
+
//------------------------------------------------------------------------
|
| 167 |
+
// Template specializations.
|
| 168 |
+
|
| 169 |
+
template void* choose_bias_act_kernel<double> (const bias_act_kernel_params& p);
|
| 170 |
+
template void* choose_bias_act_kernel<float> (const bias_act_kernel_params& p);
|
| 171 |
+
template void* choose_bias_act_kernel<c10::Half> (const bias_act_kernel_params& p);
|
| 172 |
+
|
| 173 |
+
//------------------------------------------------------------------------
|
draggan/stylegan2/torch_utils/ops/bias_act.h
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
| 2 |
+
//
|
| 3 |
+
// NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
// and proprietary rights in and to this software, related documentation
|
| 5 |
+
// and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
// distribution of this software and related documentation without an express
|
| 7 |
+
// license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
//------------------------------------------------------------------------
|
| 10 |
+
// CUDA kernel parameters.
|
| 11 |
+
|
| 12 |
+
struct bias_act_kernel_params
|
| 13 |
+
{
|
| 14 |
+
const void* x; // [sizeX]
|
| 15 |
+
const void* b; // [sizeB] or NULL
|
| 16 |
+
const void* xref; // [sizeX] or NULL
|
| 17 |
+
const void* yref; // [sizeX] or NULL
|
| 18 |
+
const void* dy; // [sizeX] or NULL
|
| 19 |
+
void* y; // [sizeX]
|
| 20 |
+
|
| 21 |
+
int grad;
|
| 22 |
+
int act;
|
| 23 |
+
float alpha;
|
| 24 |
+
float gain;
|
| 25 |
+
float clamp;
|
| 26 |
+
|
| 27 |
+
int sizeX;
|
| 28 |
+
int sizeB;
|
| 29 |
+
int stepB;
|
| 30 |
+
int loopX;
|
| 31 |
+
};
|
| 32 |
+
|
| 33 |
+
//------------------------------------------------------------------------
|
| 34 |
+
// CUDA kernel selection.
|
| 35 |
+
|
| 36 |
+
template <class T> void* choose_bias_act_kernel(const bias_act_kernel_params& p);
|
| 37 |
+
|
| 38 |
+
//------------------------------------------------------------------------
|
draggan/stylegan2/torch_utils/ops/bias_act.py
ADDED
|
@@ -0,0 +1,212 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Custom PyTorch ops for efficient bias and activation."""
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
import warnings
|
| 13 |
+
import numpy as np
|
| 14 |
+
import torch
|
| 15 |
+
import dnnlib
|
| 16 |
+
import traceback
|
| 17 |
+
|
| 18 |
+
from .. import custom_ops
|
| 19 |
+
from .. import misc
|
| 20 |
+
|
| 21 |
+
#----------------------------------------------------------------------------
|
| 22 |
+
|
| 23 |
+
activation_funcs = {
|
| 24 |
+
'linear': dnnlib.EasyDict(func=lambda x, **_: x, def_alpha=0, def_gain=1, cuda_idx=1, ref='', has_2nd_grad=False),
|
| 25 |
+
'relu': dnnlib.EasyDict(func=lambda x, **_: torch.nn.functional.relu(x), def_alpha=0, def_gain=np.sqrt(2), cuda_idx=2, ref='y', has_2nd_grad=False),
|
| 26 |
+
'lrelu': dnnlib.EasyDict(func=lambda x, alpha, **_: torch.nn.functional.leaky_relu(x, alpha), def_alpha=0.2, def_gain=np.sqrt(2), cuda_idx=3, ref='y', has_2nd_grad=False),
|
| 27 |
+
'tanh': dnnlib.EasyDict(func=lambda x, **_: torch.tanh(x), def_alpha=0, def_gain=1, cuda_idx=4, ref='y', has_2nd_grad=True),
|
| 28 |
+
'sigmoid': dnnlib.EasyDict(func=lambda x, **_: torch.sigmoid(x), def_alpha=0, def_gain=1, cuda_idx=5, ref='y', has_2nd_grad=True),
|
| 29 |
+
'elu': dnnlib.EasyDict(func=lambda x, **_: torch.nn.functional.elu(x), def_alpha=0, def_gain=1, cuda_idx=6, ref='y', has_2nd_grad=True),
|
| 30 |
+
'selu': dnnlib.EasyDict(func=lambda x, **_: torch.nn.functional.selu(x), def_alpha=0, def_gain=1, cuda_idx=7, ref='y', has_2nd_grad=True),
|
| 31 |
+
'softplus': dnnlib.EasyDict(func=lambda x, **_: torch.nn.functional.softplus(x), def_alpha=0, def_gain=1, cuda_idx=8, ref='y', has_2nd_grad=True),
|
| 32 |
+
'swish': dnnlib.EasyDict(func=lambda x, **_: torch.sigmoid(x) * x, def_alpha=0, def_gain=np.sqrt(2), cuda_idx=9, ref='x', has_2nd_grad=True),
|
| 33 |
+
}
|
| 34 |
+
|
| 35 |
+
#----------------------------------------------------------------------------
|
| 36 |
+
|
| 37 |
+
_inited = False
|
| 38 |
+
_plugin = None
|
| 39 |
+
_null_tensor = torch.empty([0])
|
| 40 |
+
|
| 41 |
+
def _init():
|
| 42 |
+
global _inited, _plugin
|
| 43 |
+
if not _inited:
|
| 44 |
+
_inited = True
|
| 45 |
+
sources = ['bias_act.cpp', 'bias_act.cu']
|
| 46 |
+
sources = [os.path.join(os.path.dirname(__file__), s) for s in sources]
|
| 47 |
+
try:
|
| 48 |
+
_plugin = custom_ops.get_plugin('bias_act_plugin', sources=sources, extra_cuda_cflags=['--use_fast_math'])
|
| 49 |
+
except:
|
| 50 |
+
warnings.warn('Failed to build CUDA kernels for bias_act. Falling back to slow reference implementation. Details:\n\n' + traceback.format_exc())
|
| 51 |
+
return _plugin is not None
|
| 52 |
+
|
| 53 |
+
#----------------------------------------------------------------------------
|
| 54 |
+
|
| 55 |
+
def bias_act(x, b=None, dim=1, act='linear', alpha=None, gain=None, clamp=None, impl='cuda'):
|
| 56 |
+
r"""Fused bias and activation function.
|
| 57 |
+
|
| 58 |
+
Adds bias `b` to activation tensor `x`, evaluates activation function `act`,
|
| 59 |
+
and scales the result by `gain`. Each of the steps is optional. In most cases,
|
| 60 |
+
the fused op is considerably more efficient than performing the same calculation
|
| 61 |
+
using standard PyTorch ops. It supports first and second order gradients,
|
| 62 |
+
but not third order gradients.
|
| 63 |
+
|
| 64 |
+
Args:
|
| 65 |
+
x: Input activation tensor. Can be of any shape.
|
| 66 |
+
b: Bias vector, or `None` to disable. Must be a 1D tensor of the same type
|
| 67 |
+
as `x`. The shape must be known, and it must match the dimension of `x`
|
| 68 |
+
corresponding to `dim`.
|
| 69 |
+
dim: The dimension in `x` corresponding to the elements of `b`.
|
| 70 |
+
The value of `dim` is ignored if `b` is not specified.
|
| 71 |
+
act: Name of the activation function to evaluate, or `"linear"` to disable.
|
| 72 |
+
Can be e.g. `"relu"`, `"lrelu"`, `"tanh"`, `"sigmoid"`, `"swish"`, etc.
|
| 73 |
+
See `activation_funcs` for a full list. `None` is not allowed.
|
| 74 |
+
alpha: Shape parameter for the activation function, or `None` to use the default.
|
| 75 |
+
gain: Scaling factor for the output tensor, or `None` to use default.
|
| 76 |
+
See `activation_funcs` for the default scaling of each activation function.
|
| 77 |
+
If unsure, consider specifying 1.
|
| 78 |
+
clamp: Clamp the output values to `[-clamp, +clamp]`, or `None` to disable
|
| 79 |
+
the clamping (default).
|
| 80 |
+
impl: Name of the implementation to use. Can be `"ref"` or `"cuda"` (default).
|
| 81 |
+
|
| 82 |
+
Returns:
|
| 83 |
+
Tensor of the same shape and datatype as `x`.
|
| 84 |
+
"""
|
| 85 |
+
assert isinstance(x, torch.Tensor)
|
| 86 |
+
assert impl in ['ref', 'cuda']
|
| 87 |
+
if impl == 'cuda' and x.device.type == 'cuda' and _init():
|
| 88 |
+
return _bias_act_cuda(dim=dim, act=act, alpha=alpha, gain=gain, clamp=clamp).apply(x, b)
|
| 89 |
+
return _bias_act_ref(x=x, b=b, dim=dim, act=act, alpha=alpha, gain=gain, clamp=clamp)
|
| 90 |
+
|
| 91 |
+
#----------------------------------------------------------------------------
|
| 92 |
+
|
| 93 |
+
@misc.profiled_function
|
| 94 |
+
def _bias_act_ref(x, b=None, dim=1, act='linear', alpha=None, gain=None, clamp=None):
|
| 95 |
+
"""Slow reference implementation of `bias_act()` using standard TensorFlow ops.
|
| 96 |
+
"""
|
| 97 |
+
assert isinstance(x, torch.Tensor)
|
| 98 |
+
assert clamp is None or clamp >= 0
|
| 99 |
+
spec = activation_funcs[act]
|
| 100 |
+
alpha = float(alpha if alpha is not None else spec.def_alpha)
|
| 101 |
+
gain = float(gain if gain is not None else spec.def_gain)
|
| 102 |
+
clamp = float(clamp if clamp is not None else -1)
|
| 103 |
+
|
| 104 |
+
# Add bias.
|
| 105 |
+
if b is not None:
|
| 106 |
+
assert isinstance(b, torch.Tensor) and b.ndim == 1
|
| 107 |
+
assert 0 <= dim < x.ndim
|
| 108 |
+
assert b.shape[0] == x.shape[dim]
|
| 109 |
+
x = x + b.reshape([-1 if i == dim else 1 for i in range(x.ndim)])
|
| 110 |
+
|
| 111 |
+
# Evaluate activation function.
|
| 112 |
+
alpha = float(alpha)
|
| 113 |
+
x = spec.func(x, alpha=alpha)
|
| 114 |
+
|
| 115 |
+
# Scale by gain.
|
| 116 |
+
gain = float(gain)
|
| 117 |
+
if gain != 1:
|
| 118 |
+
x = x * gain
|
| 119 |
+
|
| 120 |
+
# Clamp.
|
| 121 |
+
if clamp >= 0:
|
| 122 |
+
x = x.clamp(-clamp, clamp) # pylint: disable=invalid-unary-operand-type
|
| 123 |
+
return x
|
| 124 |
+
|
| 125 |
+
#----------------------------------------------------------------------------
|
| 126 |
+
|
| 127 |
+
_bias_act_cuda_cache = dict()
|
| 128 |
+
|
| 129 |
+
def _bias_act_cuda(dim=1, act='linear', alpha=None, gain=None, clamp=None):
|
| 130 |
+
"""Fast CUDA implementation of `bias_act()` using custom ops.
|
| 131 |
+
"""
|
| 132 |
+
# Parse arguments.
|
| 133 |
+
assert clamp is None or clamp >= 0
|
| 134 |
+
spec = activation_funcs[act]
|
| 135 |
+
alpha = float(alpha if alpha is not None else spec.def_alpha)
|
| 136 |
+
gain = float(gain if gain is not None else spec.def_gain)
|
| 137 |
+
clamp = float(clamp if clamp is not None else -1)
|
| 138 |
+
|
| 139 |
+
# Lookup from cache.
|
| 140 |
+
key = (dim, act, alpha, gain, clamp)
|
| 141 |
+
if key in _bias_act_cuda_cache:
|
| 142 |
+
return _bias_act_cuda_cache[key]
|
| 143 |
+
|
| 144 |
+
# Forward op.
|
| 145 |
+
class BiasActCuda(torch.autograd.Function):
|
| 146 |
+
@staticmethod
|
| 147 |
+
def forward(ctx, x, b): # pylint: disable=arguments-differ
|
| 148 |
+
ctx.memory_format = torch.channels_last if x.ndim > 2 and x.stride()[1] == 1 else torch.contiguous_format
|
| 149 |
+
x = x.contiguous(memory_format=ctx.memory_format)
|
| 150 |
+
b = b.contiguous() if b is not None else _null_tensor
|
| 151 |
+
y = x
|
| 152 |
+
if act != 'linear' or gain != 1 or clamp >= 0 or b is not _null_tensor:
|
| 153 |
+
y = _plugin.bias_act(x, b, _null_tensor, _null_tensor, _null_tensor, 0, dim, spec.cuda_idx, alpha, gain, clamp)
|
| 154 |
+
ctx.save_for_backward(
|
| 155 |
+
x if 'x' in spec.ref or spec.has_2nd_grad else _null_tensor,
|
| 156 |
+
b if 'x' in spec.ref or spec.has_2nd_grad else _null_tensor,
|
| 157 |
+
y if 'y' in spec.ref else _null_tensor)
|
| 158 |
+
return y
|
| 159 |
+
|
| 160 |
+
@staticmethod
|
| 161 |
+
def backward(ctx, dy): # pylint: disable=arguments-differ
|
| 162 |
+
dy = dy.contiguous(memory_format=ctx.memory_format)
|
| 163 |
+
x, b, y = ctx.saved_tensors
|
| 164 |
+
dx = None
|
| 165 |
+
db = None
|
| 166 |
+
|
| 167 |
+
if ctx.needs_input_grad[0] or ctx.needs_input_grad[1]:
|
| 168 |
+
dx = dy
|
| 169 |
+
if act != 'linear' or gain != 1 or clamp >= 0:
|
| 170 |
+
dx = BiasActCudaGrad.apply(dy, x, b, y)
|
| 171 |
+
|
| 172 |
+
if ctx.needs_input_grad[1]:
|
| 173 |
+
db = dx.sum([i for i in range(dx.ndim) if i != dim])
|
| 174 |
+
|
| 175 |
+
return dx, db
|
| 176 |
+
|
| 177 |
+
# Backward op.
|
| 178 |
+
class BiasActCudaGrad(torch.autograd.Function):
|
| 179 |
+
@staticmethod
|
| 180 |
+
def forward(ctx, dy, x, b, y): # pylint: disable=arguments-differ
|
| 181 |
+
ctx.memory_format = torch.channels_last if dy.ndim > 2 and dy.stride()[1] == 1 else torch.contiguous_format
|
| 182 |
+
dx = _plugin.bias_act(dy, b, x, y, _null_tensor, 1, dim, spec.cuda_idx, alpha, gain, clamp)
|
| 183 |
+
ctx.save_for_backward(
|
| 184 |
+
dy if spec.has_2nd_grad else _null_tensor,
|
| 185 |
+
x, b, y)
|
| 186 |
+
return dx
|
| 187 |
+
|
| 188 |
+
@staticmethod
|
| 189 |
+
def backward(ctx, d_dx): # pylint: disable=arguments-differ
|
| 190 |
+
d_dx = d_dx.contiguous(memory_format=ctx.memory_format)
|
| 191 |
+
dy, x, b, y = ctx.saved_tensors
|
| 192 |
+
d_dy = None
|
| 193 |
+
d_x = None
|
| 194 |
+
d_b = None
|
| 195 |
+
d_y = None
|
| 196 |
+
|
| 197 |
+
if ctx.needs_input_grad[0]:
|
| 198 |
+
d_dy = BiasActCudaGrad.apply(d_dx, x, b, y)
|
| 199 |
+
|
| 200 |
+
if spec.has_2nd_grad and (ctx.needs_input_grad[1] or ctx.needs_input_grad[2]):
|
| 201 |
+
d_x = _plugin.bias_act(d_dx, b, x, y, dy, 2, dim, spec.cuda_idx, alpha, gain, clamp)
|
| 202 |
+
|
| 203 |
+
if spec.has_2nd_grad and ctx.needs_input_grad[2]:
|
| 204 |
+
d_b = d_x.sum([i for i in range(d_x.ndim) if i != dim])
|
| 205 |
+
|
| 206 |
+
return d_dy, d_x, d_b, d_y
|
| 207 |
+
|
| 208 |
+
# Add to cache.
|
| 209 |
+
_bias_act_cuda_cache[key] = BiasActCuda
|
| 210 |
+
return BiasActCuda
|
| 211 |
+
|
| 212 |
+
#----------------------------------------------------------------------------
|