Datasets:


Update README.md
Browse files
README.md
CHANGED
|
@@ -46,3 +46,43 @@ configs:
|
|
| 46 |
- split: queries
|
| 47 |
path: TATQA/queries.jsonl.gz
|
| 48 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 46 |
- split: queries
|
| 47 |
path: TATQA/queries.jsonl.gz
|
| 48 |
---
|
| 49 |
+
# Dataset Card for FinanceRAG
|
| 50 |
+
|
| 51 |
+
## Dataset Summary
|
| 52 |
+
|
| 53 |
+
TBD.
|
| 54 |
+
|
| 55 |
+
## Datasets
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
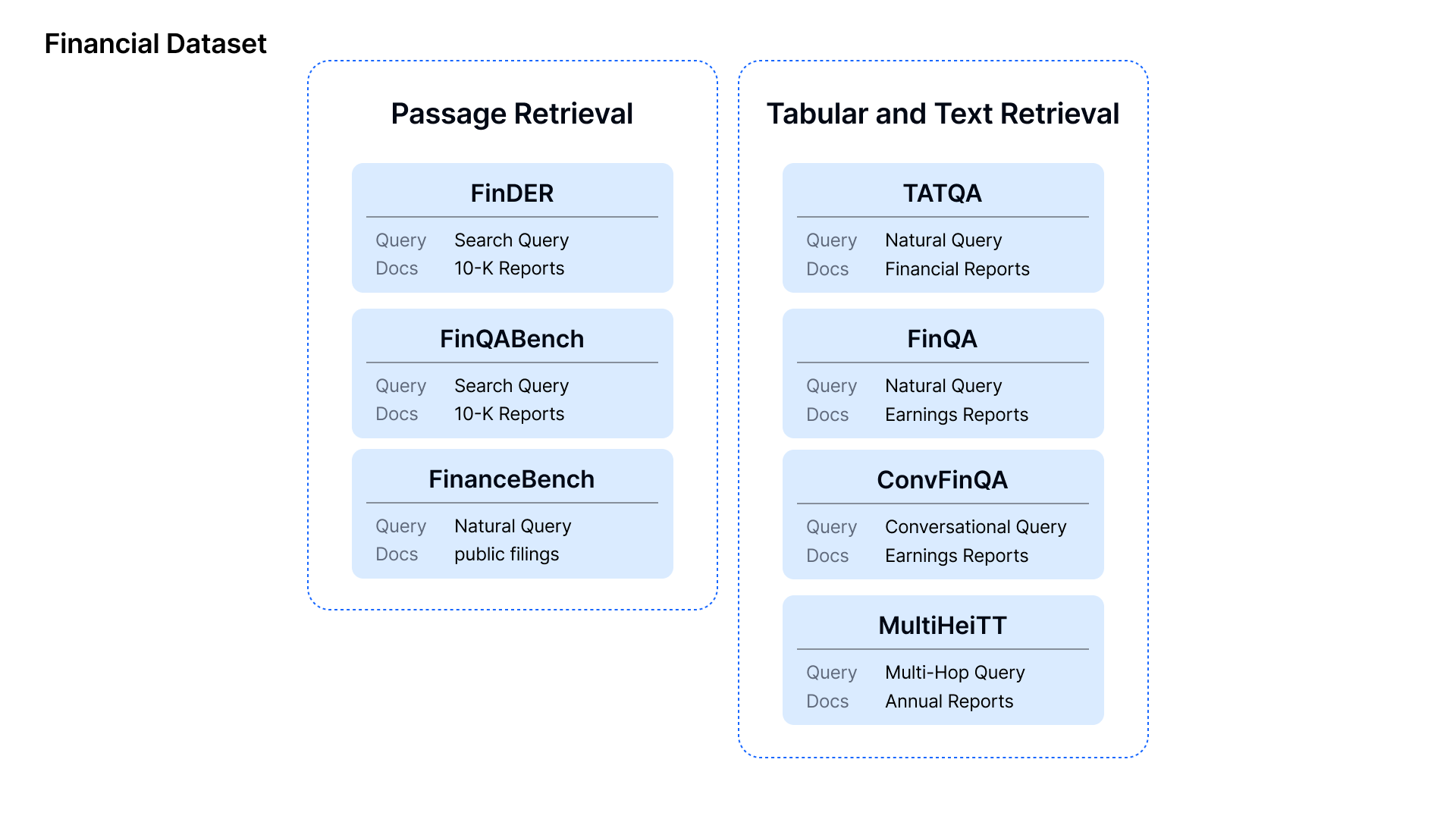
1. **Passage Retrieval**:
|
| 59 |
+
- **FinDER**: This task involves retrieving relevant sections from **10-K Reports** and financial disclosures based on **Search Queries** that simulate real-world questions asked by financial professionals, using domain-specific jargon and abbreviations.
|
| 60 |
+
- **FinQABench**: Focuses on testing AI models' ability to answer **Search Queries** over **10-K Reports** with accuracy, evaluating the system's ability to detect hallucinations and ensure factual correctness in generated answers.
|
| 61 |
+
- **FinanceBench**: Participants use **Natural Queries** to retrieve relevant information from public filings like **10-K** and **Annual Reports**. The aim is to evaluate how well systems handle straightforward, real-world financial questions.
|
| 62 |
+
|
| 63 |
+
2. **Tabular and Text Retrieval**:
|
| 64 |
+
- **TATQA**: Requires participants to answer **Natural Queries** that involve numerical reasoning over hybrid data, which combines tables and text from **Financial Reports**. Tasks include basic arithmetic, comparisons, and logical reasoning.
|
| 65 |
+
- **FinQA**: This task demands answering complex **Natural Queries** over **Earnings Reports** using multi-step numerical reasoning. Participants must accurately extract and calculate data from both textual and tabular sources.
|
| 66 |
+
- **ConvFinQA**: Involves handling **Conversational Queries** where participants answer multi-turn questions based on **Earnings Reports**, maintaining context and accuracy across multiple interactions.
|
| 67 |
+
- **MultiHiertt**: Focuses on **Multi-Hop Queries**, requiring participants to retrieve and reason over hierarchical tables and unstructured text from **Annual Reports**, making this one of the more complex reasoning tasks involving multiple steps across various document sections.
|
| 68 |
+
|
| 69 |
+
## Files
|
| 70 |
+
|
| 71 |
+
For each dataset, you are provided with two files:
|
| 72 |
+
* **corpus.jsonl** - This is a `JSONLines` file containing the context corpus. Each line in the file represents a single document in `JSON` format.
|
| 73 |
+
* **queries.jsonl** - This is a `JSONLines` file containing the queries. Each line in this file represents one query in `JSON` format.
|
| 74 |
+
|
| 75 |
+
Both files follow the jsonlines format, where each line corresponds to a separate data instance in `JSON` format.
|
| 76 |
+
|
| 77 |
+
Here’s an expanded description including explanations for each line:
|
| 78 |
+
|
| 79 |
+
- **_id**: A unique identifier for the context/query.
|
| 80 |
+
- **title**: The title or headline of the context/query.
|
| 81 |
+
- **text**: The full body of the document/query, containing the main content.
|
| 82 |
+
|
| 83 |
+
## How to Use
|
| 84 |
+
|
| 85 |
+
``` python
|
| 86 |
+
from datasets import load_dataset
|
| 87 |
+
|
| 88 |
+
```
|