
Quant for 6.5
Browse files- README.md +100 -36
- config.json +42 -0
- generation_config.json +6 -0
- merges.txt +0 -0
- model.safetensors.index.json +651 -0
- output-00001-of-00002.safetensors +3 -0
- output-00002-of-00002.safetensors +3 -0
- special_tokens_map.json +63 -0
- tokenizer.json +0 -0
- tokenizer_config.json +357 -0
- vocab.json +0 -0
README.md
CHANGED
|
@@ -82,68 +82,132 @@ model-index:
|
|
| 82 |
metrics:
|
| 83 |
- type: pass@1
|
| 84 |
value: 40.6
|
| 85 |
-
quantized_by: bartowski
|
| 86 |
---
|
| 87 |
|
| 88 |
-
|
| 89 |
|
| 90 |
-
|
| 91 |
|
| 92 |
-
|
| 93 |
|
| 94 |
-
|
| 95 |
|
| 96 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 97 |
|
| 98 |
-
|
| 99 |
|
| 100 |
-
|
| 101 |
|
|
|
|
| 102 |
|
| 103 |
-
|
| 104 |
|
| 105 |
-
|
| 106 |
|
| 107 |
-
|
|
|
|
|
|
|
| 108 |
|
| 109 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 110 |
|
| 111 |
-
|
|
|
|
|
|
|
|
|
|
| 112 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 113 |
|
| 114 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 115 |
|
| 116 |
-
With git:
|
| 117 |
|
| 118 |
-
|
| 119 |
-
|
|
|
|
|
|
|
| 120 |
```
|
| 121 |
|
| 122 |
-
|
| 123 |
|
| 124 |
-
|
| 125 |
-
|
| 126 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 127 |
|
| 128 |
-
|
|
|
|
|
|
|
| 129 |
|
| 130 |
-
|
| 131 |
-
|
| 132 |
-
|
|
|
|
| 133 |
```
|
|
|
|
| 134 |
|
| 135 |
-
|
| 136 |
|
| 137 |
-
|
| 138 |
|
| 139 |
-
|
| 140 |
-
mkdir starcoder2-15b-instruct-v0.1-exl2-6_5
|
| 141 |
-
huggingface-cli download bartowski/starcoder2-15b-instruct-v0.1-exl2 --revision 6_5 --local-dir starcoder2-15b-instruct-v0.1-exl2-6_5 --local-dir-use-symlinks False
|
| 142 |
-
```
|
| 143 |
|
| 144 |
-
|
| 145 |
|
| 146 |
-
|
| 147 |
-
|
| 148 |
-
|
| 149 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 82 |
metrics:
|
| 83 |
- type: pass@1
|
| 84 |
value: 40.6
|
|
|
|
| 85 |
---
|
| 86 |
|
| 87 |
+
# StarCoder2-Instruct: Fully Transparent and Permissive Self-Alignment for Code Generation
|
| 88 |
|
| 89 |
+

|
| 90 |
|
| 91 |
+
## Model Summary
|
| 92 |
|
| 93 |
+
We introduce StarCoder2-15B-Instruct-v0.1, the very first entirely self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs.
|
| 94 |
|
| 95 |
+
- **Model:** [bigcode/starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1)
|
| 96 |
+
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align)
|
| 97 |
+
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/)
|
| 98 |
+
- **Authors:**
|
| 99 |
+
[Yuxiang Wei](https://yuxiang.cs.illinois.edu),
|
| 100 |
+
[Federico Cassano](https://federico.codes/),
|
| 101 |
+
[Jiawei Liu](https://jw-liu.xyz),
|
| 102 |
+
[Yifeng Ding](https://yifeng-ding.com),
|
| 103 |
+
[Naman Jain](https://naman-ntc.github.io),
|
| 104 |
+
[Harm de Vries](https://www.harmdevries.com),
|
| 105 |
+
[Leandro von Werra](https://twitter.com/lvwerra),
|
| 106 |
+
[Arjun Guha](https://www.khoury.northeastern.edu/home/arjunguha/main/home/),
|
| 107 |
+
[Lingming Zhang](https://lingming.cs.illinois.edu).
|
| 108 |
|
| 109 |
+

|
| 110 |
|
| 111 |
+
## Use
|
| 112 |
|
| 113 |
+
### Intended use
|
| 114 |
|
| 115 |
+
The model is designed to respond to **coding-related instructions in a single turn**. Instructions in other styles may result in less accurate responses.
|
| 116 |
|
| 117 |
+
Here is an example to get started with the model using the [transformers](https://huggingface.co/docs/transformers/index) library:
|
| 118 |
|
| 119 |
+
```python
|
| 120 |
+
import transformers
|
| 121 |
+
import torch
|
| 122 |
|
| 123 |
+
pipeline = transformers.pipeline(
|
| 124 |
+
model="bigcode/starcoder2-15b-instruct-v0.1",
|
| 125 |
+
task="text-generation",
|
| 126 |
+
torch_dtype=torch.bfloat16,
|
| 127 |
+
device_map="auto",
|
| 128 |
+
)
|
| 129 |
|
| 130 |
+
def respond(instruction: str, response_prefix: str) -> str:
|
| 131 |
+
messages = [{"role": "user", "content": instruction}]
|
| 132 |
+
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False)
|
| 133 |
+
prompt += response_prefix
|
| 134 |
|
| 135 |
+
teminators = [
|
| 136 |
+
pipeline.tokenizer.eos_token_id,
|
| 137 |
+
pipeline.tokenizer.convert_tokens_to_ids("###"),
|
| 138 |
+
]
|
| 139 |
|
| 140 |
+
result = pipeline(
|
| 141 |
+
prompt,
|
| 142 |
+
max_length=256,
|
| 143 |
+
num_return_sequences=1,
|
| 144 |
+
do_sample=False,
|
| 145 |
+
eos_token_id=teminators,
|
| 146 |
+
pad_token_id=pipeline.tokenizer.eos_token_id,
|
| 147 |
+
truncation=True,
|
| 148 |
+
)
|
| 149 |
+
response = response_prefix + result[0]["generated_text"][len(prompt) :].split("###")[0].rstrip()
|
| 150 |
+
return response
|
| 151 |
|
|
|
|
| 152 |
|
| 153 |
+
instruction = "Write a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria."
|
| 154 |
+
response_prefix = ""
|
| 155 |
+
|
| 156 |
+
print(respond(instruction, response_prefix))
|
| 157 |
```
|
| 158 |
|
| 159 |
+
Here is the expected output:
|
| 160 |
|
| 161 |
+
``````
|
| 162 |
+
Here's how you can implement a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria:
|
| 163 |
+
|
| 164 |
+
```python
|
| 165 |
+
from typing import TypeVar, Callable
|
| 166 |
+
|
| 167 |
+
T = TypeVar('T')
|
| 168 |
|
| 169 |
+
def quicksort(items: list[T], less_than: Callable[[T, T], bool] = lambda x, y: x < y) -> list[T]:
|
| 170 |
+
if len(items) <= 1:
|
| 171 |
+
return items
|
| 172 |
|
| 173 |
+
pivot = items[0]
|
| 174 |
+
less = [x for x in items[1:] if less_than(x, pivot)]
|
| 175 |
+
greater = [x for x in items[1:] if not less_than(x, pivot)]
|
| 176 |
+
return quicksort(less, less_than) + [pivot] + quicksort(greater, less_than)
|
| 177 |
```
|
| 178 |
+
``````
|
| 179 |
|
| 180 |
+
### Bias, Risks, and Limitations
|
| 181 |
|
| 182 |
+
StarCoder2-15B-Instruct-v0.1 is primarily finetuned for Python code generation tasks that can be verified through execution, which may lead to certain biases and limitations. For example, the model might not adhere strictly to instructions that dictate the output format. In these situations, it's beneficial to provide a **response prefix** or a **one-shot example** to steer the model’s output. Additionally, the model may have limitations with other programming languages and out-of-domain coding tasks.
|
| 183 |
|
| 184 |
+
The model also inherits the bias, risks, and limitations from its base StarCoder2-15B model. For more information, please refer to the [StarCoder2-15B model card](https://huggingface.co/bigcode/starcoder2-15b).
|
|
|
|
|
|
|
|
|
|
| 185 |
|
| 186 |
+
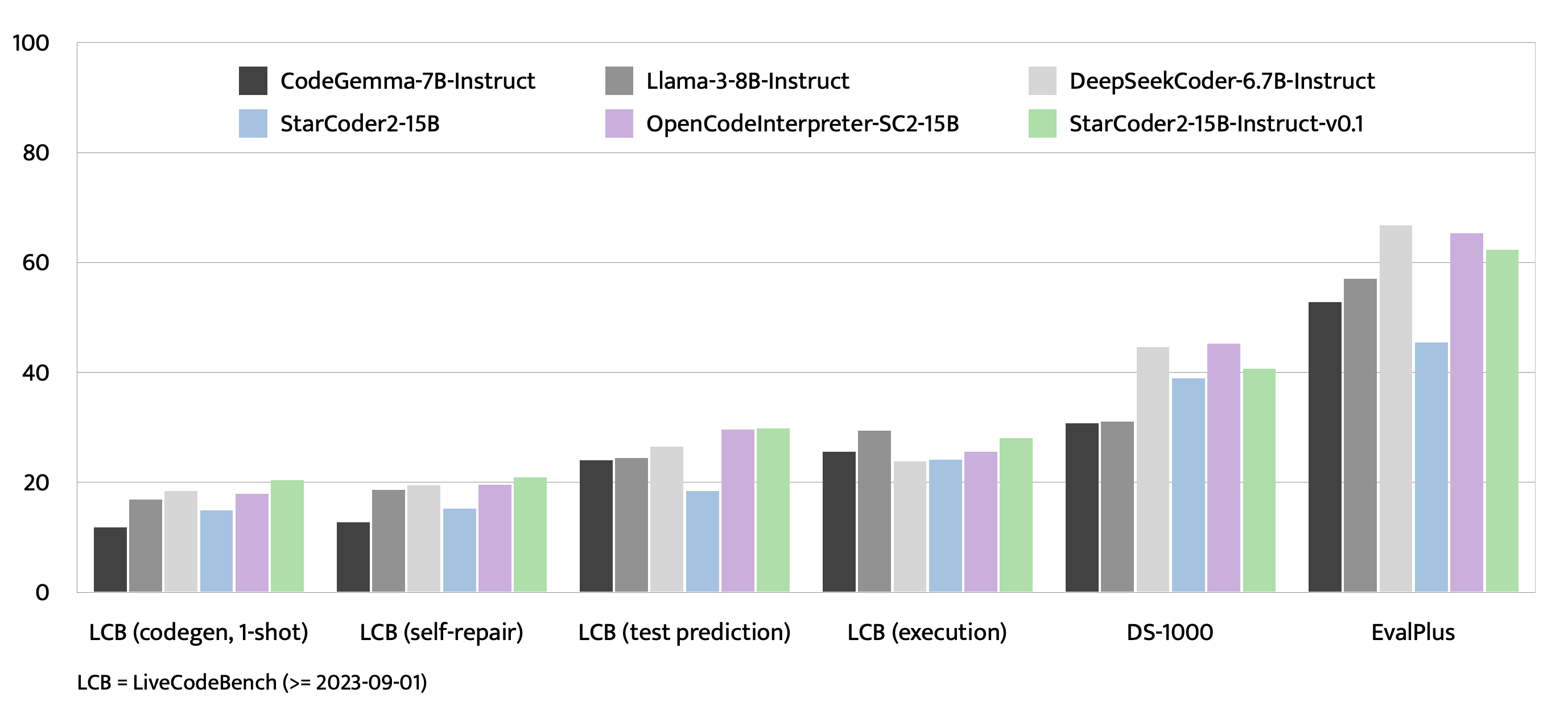
## Evaluation on EvalPlus, LiveCodeBench, and DS-1000
|
| 187 |
|
| 188 |
+
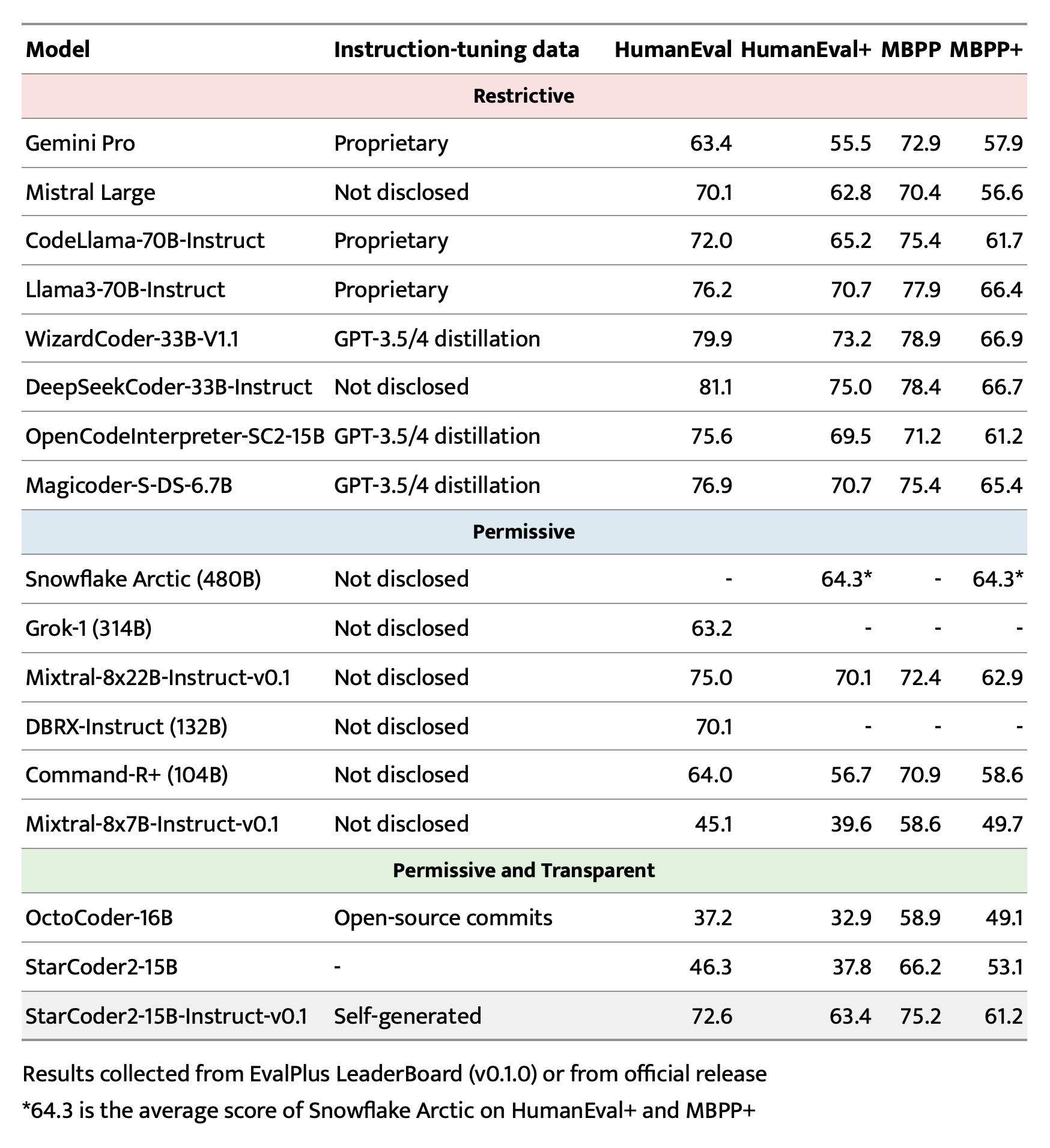
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
## Training Details
|
| 193 |
+
|
| 194 |
+
### Hyperparameters
|
| 195 |
+
|
| 196 |
+
- **Optimizer:** Adafactor
|
| 197 |
+
- **Learning rate:** 1e-5
|
| 198 |
+
- **Epoch:** 4
|
| 199 |
+
- **Batch size:** 64
|
| 200 |
+
- **Warmup ratio:** 0.05
|
| 201 |
+
- **Scheduler:** Linear
|
| 202 |
+
- **Sequence length:** 1280
|
| 203 |
+
- **Dropout**: Not applied
|
| 204 |
+
|
| 205 |
+
### Hardware
|
| 206 |
+
|
| 207 |
+
1 x NVIDIA A100 80GB
|
| 208 |
+
|
| 209 |
+
## Resources
|
| 210 |
+
|
| 211 |
+
- **Model:** [bigcode/starCoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1)
|
| 212 |
+
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align)
|
| 213 |
+
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/)
|
config.json
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "starcoder2-instruct-15b-v0.1",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"Starcoder2ForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 0,
|
| 8 |
+
"embedding_dropout": 0.0,
|
| 9 |
+
"eos_token_id": 0,
|
| 10 |
+
"hidden_act": "gelu_pytorch_tanh",
|
| 11 |
+
"hidden_size": 6144,
|
| 12 |
+
"initializer_range": 0.01275,
|
| 13 |
+
"intermediate_size": 24576,
|
| 14 |
+
"max_position_embeddings": 16384,
|
| 15 |
+
"mlp_type": "default",
|
| 16 |
+
"model_type": "starcoder2",
|
| 17 |
+
"norm_epsilon": 1e-05,
|
| 18 |
+
"norm_type": "layer_norm",
|
| 19 |
+
"num_attention_heads": 48,
|
| 20 |
+
"num_hidden_layers": 40,
|
| 21 |
+
"num_key_value_heads": 4,
|
| 22 |
+
"residual_dropout": 0.0,
|
| 23 |
+
"rope_theta": 100000,
|
| 24 |
+
"sliding_window": 4096,
|
| 25 |
+
"tie_word_embeddings": false,
|
| 26 |
+
"torch_dtype": "bfloat16",
|
| 27 |
+
"transformers_version": "4.39.0.dev0",
|
| 28 |
+
"use_bias": true,
|
| 29 |
+
"use_cache": true,
|
| 30 |
+
"vocab_size": 49152,
|
| 31 |
+
"quantization_config": {
|
| 32 |
+
"quant_method": "exl2",
|
| 33 |
+
"version": "0.0.20",
|
| 34 |
+
"bits": 6.5,
|
| 35 |
+
"head_bits": 8,
|
| 36 |
+
"calibration": {
|
| 37 |
+
"rows": 100,
|
| 38 |
+
"length": 2048,
|
| 39 |
+
"dataset": "(default)"
|
| 40 |
+
}
|
| 41 |
+
}
|
| 42 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 50256,
|
| 4 |
+
"eos_token_id": 50256,
|
| 5 |
+
"transformers_version": "4.39.0.dev0"
|
| 6 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,651 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 31915778048
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "model-00007-of-00007.safetensors",
|
| 7 |
+
"model.embed_tokens.weight": "model-00001-of-00007.safetensors",
|
| 8 |
+
"model.layers.0.input_layernorm.bias": "model-00001-of-00007.safetensors",
|
| 9 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 10 |
+
"model.layers.0.mlp.c_fc.bias": "model-00001-of-00007.safetensors",
|
| 11 |
+
"model.layers.0.mlp.c_fc.weight": "model-00001-of-00007.safetensors",
|
| 12 |
+
"model.layers.0.mlp.c_proj.bias": "model-00001-of-00007.safetensors",
|
| 13 |
+
"model.layers.0.mlp.c_proj.weight": "model-00001-of-00007.safetensors",
|
| 14 |
+
"model.layers.0.post_attention_layernorm.bias": "model-00001-of-00007.safetensors",
|
| 15 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 16 |
+
"model.layers.0.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
| 17 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
| 18 |
+
"model.layers.0.self_attn.o_proj.bias": "model-00001-of-00007.safetensors",
|
| 19 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
| 20 |
+
"model.layers.0.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
| 21 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
| 22 |
+
"model.layers.0.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
| 23 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
| 24 |
+
"model.layers.1.input_layernorm.bias": "model-00001-of-00007.safetensors",
|
| 25 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 26 |
+
"model.layers.1.mlp.c_fc.bias": "model-00001-of-00007.safetensors",
|
| 27 |
+
"model.layers.1.mlp.c_fc.weight": "model-00001-of-00007.safetensors",
|
| 28 |
+
"model.layers.1.mlp.c_proj.bias": "model-00001-of-00007.safetensors",
|
| 29 |
+
"model.layers.1.mlp.c_proj.weight": "model-00001-of-00007.safetensors",
|
| 30 |
+
"model.layers.1.post_attention_layernorm.bias": "model-00001-of-00007.safetensors",
|
| 31 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 32 |
+
"model.layers.1.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
| 33 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
| 34 |
+
"model.layers.1.self_attn.o_proj.bias": "model-00001-of-00007.safetensors",
|
| 35 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
| 36 |
+
"model.layers.1.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
| 37 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
| 38 |
+
"model.layers.1.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
| 39 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
| 40 |
+
"model.layers.10.input_layernorm.bias": "model-00002-of-00007.safetensors",
|
| 41 |
+
"model.layers.10.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 42 |
+
"model.layers.10.mlp.c_fc.bias": "model-00002-of-00007.safetensors",
|
| 43 |
+
"model.layers.10.mlp.c_fc.weight": "model-00002-of-00007.safetensors",
|
| 44 |
+
"model.layers.10.mlp.c_proj.bias": "model-00002-of-00007.safetensors",
|
| 45 |
+
"model.layers.10.mlp.c_proj.weight": "model-00002-of-00007.safetensors",
|
| 46 |
+
"model.layers.10.post_attention_layernorm.bias": "model-00002-of-00007.safetensors",
|
| 47 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 48 |
+
"model.layers.10.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
| 49 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
| 50 |
+
"model.layers.10.self_attn.o_proj.bias": "model-00002-of-00007.safetensors",
|
| 51 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
| 52 |
+
"model.layers.10.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
| 53 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
| 54 |
+
"model.layers.10.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
| 55 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
| 56 |
+
"model.layers.11.input_layernorm.bias": "model-00002-of-00007.safetensors",
|
| 57 |
+
"model.layers.11.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 58 |
+
"model.layers.11.mlp.c_fc.bias": "model-00002-of-00007.safetensors",
|
| 59 |
+
"model.layers.11.mlp.c_fc.weight": "model-00002-of-00007.safetensors",
|
| 60 |
+
"model.layers.11.mlp.c_proj.bias": "model-00002-of-00007.safetensors",
|
| 61 |
+
"model.layers.11.mlp.c_proj.weight": "model-00002-of-00007.safetensors",
|
| 62 |
+
"model.layers.11.post_attention_layernorm.bias": "model-00002-of-00007.safetensors",
|
| 63 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 64 |
+
"model.layers.11.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
| 65 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
| 66 |
+
"model.layers.11.self_attn.o_proj.bias": "model-00002-of-00007.safetensors",
|
| 67 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
| 68 |
+
"model.layers.11.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
| 69 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
| 70 |
+
"model.layers.11.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
| 71 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
| 72 |
+
"model.layers.12.input_layernorm.bias": "model-00003-of-00007.safetensors",
|
| 73 |
+
"model.layers.12.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 74 |
+
"model.layers.12.mlp.c_fc.bias": "model-00003-of-00007.safetensors",
|
| 75 |
+
"model.layers.12.mlp.c_fc.weight": "model-00003-of-00007.safetensors",
|
| 76 |
+
"model.layers.12.mlp.c_proj.bias": "model-00003-of-00007.safetensors",
|
| 77 |
+
"model.layers.12.mlp.c_proj.weight": "model-00003-of-00007.safetensors",
|
| 78 |
+
"model.layers.12.post_attention_layernorm.bias": "model-00003-of-00007.safetensors",
|
| 79 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 80 |
+
"model.layers.12.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
| 81 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
| 82 |
+
"model.layers.12.self_attn.o_proj.bias": "model-00003-of-00007.safetensors",
|
| 83 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
| 84 |
+
"model.layers.12.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
| 85 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
| 86 |
+
"model.layers.12.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
| 87 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
| 88 |
+
"model.layers.13.input_layernorm.bias": "model-00003-of-00007.safetensors",
|
| 89 |
+
"model.layers.13.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 90 |
+
"model.layers.13.mlp.c_fc.bias": "model-00003-of-00007.safetensors",
|
| 91 |
+
"model.layers.13.mlp.c_fc.weight": "model-00003-of-00007.safetensors",
|
| 92 |
+
"model.layers.13.mlp.c_proj.bias": "model-00003-of-00007.safetensors",
|
| 93 |
+
"model.layers.13.mlp.c_proj.weight": "model-00003-of-00007.safetensors",
|
| 94 |
+
"model.layers.13.post_attention_layernorm.bias": "model-00003-of-00007.safetensors",
|
| 95 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 96 |
+
"model.layers.13.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
| 97 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
| 98 |
+
"model.layers.13.self_attn.o_proj.bias": "model-00003-of-00007.safetensors",
|
| 99 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
| 100 |
+
"model.layers.13.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
| 101 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
| 102 |
+
"model.layers.13.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
| 103 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
| 104 |
+
"model.layers.14.input_layernorm.bias": "model-00003-of-00007.safetensors",
|
| 105 |
+
"model.layers.14.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 106 |
+
"model.layers.14.mlp.c_fc.bias": "model-00003-of-00007.safetensors",
|
| 107 |
+
"model.layers.14.mlp.c_fc.weight": "model-00003-of-00007.safetensors",
|
| 108 |
+
"model.layers.14.mlp.c_proj.bias": "model-00003-of-00007.safetensors",
|
| 109 |
+
"model.layers.14.mlp.c_proj.weight": "model-00003-of-00007.safetensors",
|
| 110 |
+
"model.layers.14.post_attention_layernorm.bias": "model-00003-of-00007.safetensors",
|
| 111 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 112 |
+
"model.layers.14.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
| 113 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
| 114 |
+
"model.layers.14.self_attn.o_proj.bias": "model-00003-of-00007.safetensors",
|
| 115 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
| 116 |
+
"model.layers.14.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
| 117 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
| 118 |
+
"model.layers.14.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
| 119 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
| 120 |
+
"model.layers.15.input_layernorm.bias": "model-00003-of-00007.safetensors",
|
| 121 |
+
"model.layers.15.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 122 |
+
"model.layers.15.mlp.c_fc.bias": "model-00003-of-00007.safetensors",
|
| 123 |
+
"model.layers.15.mlp.c_fc.weight": "model-00003-of-00007.safetensors",
|
| 124 |
+
"model.layers.15.mlp.c_proj.bias": "model-00003-of-00007.safetensors",
|
| 125 |
+
"model.layers.15.mlp.c_proj.weight": "model-00003-of-00007.safetensors",
|
| 126 |
+
"model.layers.15.post_attention_layernorm.bias": "model-00003-of-00007.safetensors",
|
| 127 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 128 |
+
"model.layers.15.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
| 129 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
| 130 |
+
"model.layers.15.self_attn.o_proj.bias": "model-00003-of-00007.safetensors",
|
| 131 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
| 132 |
+
"model.layers.15.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
| 133 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
| 134 |
+
"model.layers.15.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
| 135 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
| 136 |
+
"model.layers.16.input_layernorm.bias": "model-00003-of-00007.safetensors",
|
| 137 |
+
"model.layers.16.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 138 |
+
"model.layers.16.mlp.c_fc.bias": "model-00003-of-00007.safetensors",
|
| 139 |
+
"model.layers.16.mlp.c_fc.weight": "model-00003-of-00007.safetensors",
|
| 140 |
+
"model.layers.16.mlp.c_proj.bias": "model-00003-of-00007.safetensors",
|
| 141 |
+
"model.layers.16.mlp.c_proj.weight": "model-00003-of-00007.safetensors",
|
| 142 |
+
"model.layers.16.post_attention_layernorm.bias": "model-00003-of-00007.safetensors",
|
| 143 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 144 |
+
"model.layers.16.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
| 145 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
| 146 |
+
"model.layers.16.self_attn.o_proj.bias": "model-00003-of-00007.safetensors",
|
| 147 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
| 148 |
+
"model.layers.16.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
| 149 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
| 150 |
+
"model.layers.16.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
| 151 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
| 152 |
+
"model.layers.17.input_layernorm.bias": "model-00003-of-00007.safetensors",
|
| 153 |
+
"model.layers.17.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 154 |
+
"model.layers.17.mlp.c_fc.bias": "model-00003-of-00007.safetensors",
|
| 155 |
+
"model.layers.17.mlp.c_fc.weight": "model-00003-of-00007.safetensors",
|
| 156 |
+
"model.layers.17.mlp.c_proj.bias": "model-00003-of-00007.safetensors",
|
| 157 |
+
"model.layers.17.mlp.c_proj.weight": "model-00003-of-00007.safetensors",
|
| 158 |
+
"model.layers.17.post_attention_layernorm.bias": "model-00003-of-00007.safetensors",
|
| 159 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 160 |
+
"model.layers.17.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
| 161 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
| 162 |
+
"model.layers.17.self_attn.o_proj.bias": "model-00003-of-00007.safetensors",
|
| 163 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
| 164 |
+
"model.layers.17.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
| 165 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
| 166 |
+
"model.layers.17.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
| 167 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
| 168 |
+
"model.layers.18.input_layernorm.bias": "model-00004-of-00007.safetensors",
|
| 169 |
+
"model.layers.18.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 170 |
+
"model.layers.18.mlp.c_fc.bias": "model-00003-of-00007.safetensors",
|
| 171 |
+
"model.layers.18.mlp.c_fc.weight": "model-00003-of-00007.safetensors",
|
| 172 |
+
"model.layers.18.mlp.c_proj.bias": "model-00004-of-00007.safetensors",
|
| 173 |
+
"model.layers.18.mlp.c_proj.weight": "model-00004-of-00007.safetensors",
|
| 174 |
+
"model.layers.18.post_attention_layernorm.bias": "model-00004-of-00007.safetensors",
|
| 175 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 176 |
+
"model.layers.18.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
| 177 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
| 178 |
+
"model.layers.18.self_attn.o_proj.bias": "model-00003-of-00007.safetensors",
|
| 179 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
| 180 |
+
"model.layers.18.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
| 181 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
| 182 |
+
"model.layers.18.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
| 183 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
| 184 |
+
"model.layers.19.input_layernorm.bias": "model-00004-of-00007.safetensors",
|
| 185 |
+
"model.layers.19.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 186 |
+
"model.layers.19.mlp.c_fc.bias": "model-00004-of-00007.safetensors",
|
| 187 |
+
"model.layers.19.mlp.c_fc.weight": "model-00004-of-00007.safetensors",
|
| 188 |
+
"model.layers.19.mlp.c_proj.bias": "model-00004-of-00007.safetensors",
|
| 189 |
+
"model.layers.19.mlp.c_proj.weight": "model-00004-of-00007.safetensors",
|
| 190 |
+
"model.layers.19.post_attention_layernorm.bias": "model-00004-of-00007.safetensors",
|
| 191 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 192 |
+
"model.layers.19.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
| 193 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
| 194 |
+
"model.layers.19.self_attn.o_proj.bias": "model-00004-of-00007.safetensors",
|
| 195 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
| 196 |
+
"model.layers.19.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
| 197 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
| 198 |
+
"model.layers.19.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
| 199 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
| 200 |
+
"model.layers.2.input_layernorm.bias": "model-00001-of-00007.safetensors",
|
| 201 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 202 |
+
"model.layers.2.mlp.c_fc.bias": "model-00001-of-00007.safetensors",
|
| 203 |
+
"model.layers.2.mlp.c_fc.weight": "model-00001-of-00007.safetensors",
|
| 204 |
+
"model.layers.2.mlp.c_proj.bias": "model-00001-of-00007.safetensors",
|
| 205 |
+
"model.layers.2.mlp.c_proj.weight": "model-00001-of-00007.safetensors",
|
| 206 |
+
"model.layers.2.post_attention_layernorm.bias": "model-00001-of-00007.safetensors",
|
| 207 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 208 |
+
"model.layers.2.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
| 209 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
| 210 |
+
"model.layers.2.self_attn.o_proj.bias": "model-00001-of-00007.safetensors",
|
| 211 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
| 212 |
+
"model.layers.2.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
| 213 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
| 214 |
+
"model.layers.2.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
| 215 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
| 216 |
+
"model.layers.20.input_layernorm.bias": "model-00004-of-00007.safetensors",
|
| 217 |
+
"model.layers.20.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 218 |
+
"model.layers.20.mlp.c_fc.bias": "model-00004-of-00007.safetensors",
|
| 219 |
+
"model.layers.20.mlp.c_fc.weight": "model-00004-of-00007.safetensors",
|
| 220 |
+
"model.layers.20.mlp.c_proj.bias": "model-00004-of-00007.safetensors",
|
| 221 |
+
"model.layers.20.mlp.c_proj.weight": "model-00004-of-00007.safetensors",
|
| 222 |
+
"model.layers.20.post_attention_layernorm.bias": "model-00004-of-00007.safetensors",
|
| 223 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 224 |
+
"model.layers.20.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
| 225 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
| 226 |
+
"model.layers.20.self_attn.o_proj.bias": "model-00004-of-00007.safetensors",
|
| 227 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
| 228 |
+
"model.layers.20.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
| 229 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
| 230 |
+
"model.layers.20.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
| 231 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
| 232 |
+
"model.layers.21.input_layernorm.bias": "model-00004-of-00007.safetensors",
|
| 233 |
+
"model.layers.21.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 234 |
+
"model.layers.21.mlp.c_fc.bias": "model-00004-of-00007.safetensors",
|
| 235 |
+
"model.layers.21.mlp.c_fc.weight": "model-00004-of-00007.safetensors",
|
| 236 |
+
"model.layers.21.mlp.c_proj.bias": "model-00004-of-00007.safetensors",
|
| 237 |
+
"model.layers.21.mlp.c_proj.weight": "model-00004-of-00007.safetensors",
|
| 238 |
+
"model.layers.21.post_attention_layernorm.bias": "model-00004-of-00007.safetensors",
|
| 239 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 240 |
+
"model.layers.21.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
| 241 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
| 242 |
+
"model.layers.21.self_attn.o_proj.bias": "model-00004-of-00007.safetensors",
|
| 243 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
| 244 |
+
"model.layers.21.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
| 245 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
| 246 |
+
"model.layers.21.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
| 247 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
| 248 |
+
"model.layers.22.input_layernorm.bias": "model-00004-of-00007.safetensors",
|
| 249 |
+
"model.layers.22.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 250 |
+
"model.layers.22.mlp.c_fc.bias": "model-00004-of-00007.safetensors",
|
| 251 |
+
"model.layers.22.mlp.c_fc.weight": "model-00004-of-00007.safetensors",
|
| 252 |
+
"model.layers.22.mlp.c_proj.bias": "model-00004-of-00007.safetensors",
|
| 253 |
+
"model.layers.22.mlp.c_proj.weight": "model-00004-of-00007.safetensors",
|
| 254 |
+
"model.layers.22.post_attention_layernorm.bias": "model-00004-of-00007.safetensors",
|
| 255 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 256 |
+
"model.layers.22.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
| 257 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
| 258 |
+
"model.layers.22.self_attn.o_proj.bias": "model-00004-of-00007.safetensors",
|
| 259 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
| 260 |
+
"model.layers.22.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
| 261 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
| 262 |
+
"model.layers.22.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
| 263 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
| 264 |
+
"model.layers.23.input_layernorm.bias": "model-00004-of-00007.safetensors",
|
| 265 |
+
"model.layers.23.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 266 |
+
"model.layers.23.mlp.c_fc.bias": "model-00004-of-00007.safetensors",
|
| 267 |
+
"model.layers.23.mlp.c_fc.weight": "model-00004-of-00007.safetensors",
|
| 268 |
+
"model.layers.23.mlp.c_proj.bias": "model-00004-of-00007.safetensors",
|
| 269 |
+
"model.layers.23.mlp.c_proj.weight": "model-00004-of-00007.safetensors",
|
| 270 |
+
"model.layers.23.post_attention_layernorm.bias": "model-00004-of-00007.safetensors",
|
| 271 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 272 |
+
"model.layers.23.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
| 273 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
| 274 |
+
"model.layers.23.self_attn.o_proj.bias": "model-00004-of-00007.safetensors",
|
| 275 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
| 276 |
+
"model.layers.23.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
| 277 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
| 278 |
+
"model.layers.23.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
| 279 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
| 280 |
+
"model.layers.24.input_layernorm.bias": "model-00004-of-00007.safetensors",
|
| 281 |
+
"model.layers.24.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 282 |
+
"model.layers.24.mlp.c_fc.bias": "model-00004-of-00007.safetensors",
|
| 283 |
+
"model.layers.24.mlp.c_fc.weight": "model-00004-of-00007.safetensors",
|
| 284 |
+
"model.layers.24.mlp.c_proj.bias": "model-00004-of-00007.safetensors",
|
| 285 |
+
"model.layers.24.mlp.c_proj.weight": "model-00004-of-00007.safetensors",
|
| 286 |
+
"model.layers.24.post_attention_layernorm.bias": "model-00004-of-00007.safetensors",
|
| 287 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 288 |
+
"model.layers.24.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
| 289 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
| 290 |
+
"model.layers.24.self_attn.o_proj.bias": "model-00004-of-00007.safetensors",
|
| 291 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
| 292 |
+
"model.layers.24.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
| 293 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
| 294 |
+
"model.layers.24.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
| 295 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
| 296 |
+
"model.layers.25.input_layernorm.bias": "model-00005-of-00007.safetensors",
|
| 297 |
+
"model.layers.25.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 298 |
+
"model.layers.25.mlp.c_fc.bias": "model-00005-of-00007.safetensors",
|
| 299 |
+
"model.layers.25.mlp.c_fc.weight": "model-00005-of-00007.safetensors",
|
| 300 |
+
"model.layers.25.mlp.c_proj.bias": "model-00005-of-00007.safetensors",
|
| 301 |
+
"model.layers.25.mlp.c_proj.weight": "model-00005-of-00007.safetensors",
|
| 302 |
+
"model.layers.25.post_attention_layernorm.bias": "model-00005-of-00007.safetensors",
|
| 303 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 304 |
+
"model.layers.25.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
| 305 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
| 306 |
+
"model.layers.25.self_attn.o_proj.bias": "model-00005-of-00007.safetensors",
|
| 307 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
| 308 |
+
"model.layers.25.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
| 309 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
| 310 |
+
"model.layers.25.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
| 311 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
| 312 |
+
"model.layers.26.input_layernorm.bias": "model-00005-of-00007.safetensors",
|
| 313 |
+
"model.layers.26.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 314 |
+
"model.layers.26.mlp.c_fc.bias": "model-00005-of-00007.safetensors",
|
| 315 |
+
"model.layers.26.mlp.c_fc.weight": "model-00005-of-00007.safetensors",
|
| 316 |
+
"model.layers.26.mlp.c_proj.bias": "model-00005-of-00007.safetensors",
|
| 317 |
+
"model.layers.26.mlp.c_proj.weight": "model-00005-of-00007.safetensors",
|
| 318 |
+
"model.layers.26.post_attention_layernorm.bias": "model-00005-of-00007.safetensors",
|
| 319 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 320 |
+
"model.layers.26.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
| 321 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
| 322 |
+
"model.layers.26.self_attn.o_proj.bias": "model-00005-of-00007.safetensors",
|
| 323 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
| 324 |
+
"model.layers.26.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
| 325 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
| 326 |
+
"model.layers.26.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
| 327 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
| 328 |
+
"model.layers.27.input_layernorm.bias": "model-00005-of-00007.safetensors",
|
| 329 |
+
"model.layers.27.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 330 |
+
"model.layers.27.mlp.c_fc.bias": "model-00005-of-00007.safetensors",
|
| 331 |
+
"model.layers.27.mlp.c_fc.weight": "model-00005-of-00007.safetensors",
|
| 332 |
+
"model.layers.27.mlp.c_proj.bias": "model-00005-of-00007.safetensors",
|
| 333 |
+
"model.layers.27.mlp.c_proj.weight": "model-00005-of-00007.safetensors",
|
| 334 |
+
"model.layers.27.post_attention_layernorm.bias": "model-00005-of-00007.safetensors",
|
| 335 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 336 |
+
"model.layers.27.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
| 337 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
| 338 |
+
"model.layers.27.self_attn.o_proj.bias": "model-00005-of-00007.safetensors",
|
| 339 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
| 340 |
+
"model.layers.27.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
| 341 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
| 342 |
+
"model.layers.27.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
| 343 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
| 344 |
+
"model.layers.28.input_layernorm.bias": "model-00005-of-00007.safetensors",
|
| 345 |
+
"model.layers.28.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 346 |
+
"model.layers.28.mlp.c_fc.bias": "model-00005-of-00007.safetensors",
|
| 347 |
+
"model.layers.28.mlp.c_fc.weight": "model-00005-of-00007.safetensors",
|
| 348 |
+
"model.layers.28.mlp.c_proj.bias": "model-00005-of-00007.safetensors",
|
| 349 |
+
"model.layers.28.mlp.c_proj.weight": "model-00005-of-00007.safetensors",
|
| 350 |
+
"model.layers.28.post_attention_layernorm.bias": "model-00005-of-00007.safetensors",
|
| 351 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 352 |
+
"model.layers.28.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
| 353 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
| 354 |
+
"model.layers.28.self_attn.o_proj.bias": "model-00005-of-00007.safetensors",
|
| 355 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
| 356 |
+
"model.layers.28.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
| 357 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
| 358 |
+
"model.layers.28.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
| 359 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
| 360 |
+
"model.layers.29.input_layernorm.bias": "model-00005-of-00007.safetensors",
|
| 361 |
+
"model.layers.29.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 362 |
+
"model.layers.29.mlp.c_fc.bias": "model-00005-of-00007.safetensors",
|
| 363 |
+
"model.layers.29.mlp.c_fc.weight": "model-00005-of-00007.safetensors",
|
| 364 |
+
"model.layers.29.mlp.c_proj.bias": "model-00005-of-00007.safetensors",
|
| 365 |
+
"model.layers.29.mlp.c_proj.weight": "model-00005-of-00007.safetensors",
|
| 366 |
+
"model.layers.29.post_attention_layernorm.bias": "model-00005-of-00007.safetensors",
|
| 367 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 368 |
+
"model.layers.29.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
| 369 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
| 370 |
+
"model.layers.29.self_attn.o_proj.bias": "model-00005-of-00007.safetensors",
|
| 371 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
| 372 |
+
"model.layers.29.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
| 373 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
| 374 |
+
"model.layers.29.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
| 375 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
| 376 |
+
"model.layers.3.input_layernorm.bias": "model-00001-of-00007.safetensors",
|
| 377 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 378 |
+
"model.layers.3.mlp.c_fc.bias": "model-00001-of-00007.safetensors",
|
| 379 |
+
"model.layers.3.mlp.c_fc.weight": "model-00001-of-00007.safetensors",
|
| 380 |
+
"model.layers.3.mlp.c_proj.bias": "model-00001-of-00007.safetensors",
|
| 381 |
+
"model.layers.3.mlp.c_proj.weight": "model-00001-of-00007.safetensors",
|
| 382 |
+
"model.layers.3.post_attention_layernorm.bias": "model-00001-of-00007.safetensors",
|
| 383 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 384 |
+
"model.layers.3.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
| 385 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
| 386 |
+
"model.layers.3.self_attn.o_proj.bias": "model-00001-of-00007.safetensors",
|
| 387 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
| 388 |
+
"model.layers.3.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
| 389 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
| 390 |
+
"model.layers.3.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
| 391 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
| 392 |
+
"model.layers.30.input_layernorm.bias": "model-00005-of-00007.safetensors",
|
| 393 |
+
"model.layers.30.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 394 |
+
"model.layers.30.mlp.c_fc.bias": "model-00005-of-00007.safetensors",
|
| 395 |
+
"model.layers.30.mlp.c_fc.weight": "model-00005-of-00007.safetensors",
|
| 396 |
+
"model.layers.30.mlp.c_proj.bias": "model-00005-of-00007.safetensors",
|
| 397 |
+
"model.layers.30.mlp.c_proj.weight": "model-00005-of-00007.safetensors",
|
| 398 |
+
"model.layers.30.post_attention_layernorm.bias": "model-00005-of-00007.safetensors",
|
| 399 |
+
"model.layers.30.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 400 |
+
"model.layers.30.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
| 401 |
+
"model.layers.30.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
| 402 |
+
"model.layers.30.self_attn.o_proj.bias": "model-00005-of-00007.safetensors",
|
| 403 |
+
"model.layers.30.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
| 404 |
+
"model.layers.30.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
| 405 |
+
"model.layers.30.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
| 406 |
+
"model.layers.30.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
| 407 |
+
"model.layers.30.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
| 408 |
+
"model.layers.31.input_layernorm.bias": "model-00006-of-00007.safetensors",
|
| 409 |
+
"model.layers.31.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 410 |
+
"model.layers.31.mlp.c_fc.bias": "model-00005-of-00007.safetensors",
|
| 411 |
+
"model.layers.31.mlp.c_fc.weight": "model-00005-of-00007.safetensors",
|
| 412 |
+
"model.layers.31.mlp.c_proj.bias": "model-00006-of-00007.safetensors",
|
| 413 |
+
"model.layers.31.mlp.c_proj.weight": "model-00006-of-00007.safetensors",
|
| 414 |
+
"model.layers.31.post_attention_layernorm.bias": "model-00006-of-00007.safetensors",
|
| 415 |
+
"model.layers.31.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 416 |
+
"model.layers.31.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
| 417 |
+
"model.layers.31.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
| 418 |
+
"model.layers.31.self_attn.o_proj.bias": "model-00005-of-00007.safetensors",
|
| 419 |
+
"model.layers.31.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
| 420 |
+
"model.layers.31.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
| 421 |
+
"model.layers.31.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
| 422 |
+
"model.layers.31.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
| 423 |
+
"model.layers.31.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
| 424 |
+
"model.layers.32.input_layernorm.bias": "model-00006-of-00007.safetensors",
|
| 425 |
+
"model.layers.32.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 426 |
+
"model.layers.32.mlp.c_fc.bias": "model-00006-of-00007.safetensors",
|
| 427 |
+
"model.layers.32.mlp.c_fc.weight": "model-00006-of-00007.safetensors",
|
| 428 |
+
"model.layers.32.mlp.c_proj.bias": "model-00006-of-00007.safetensors",
|
| 429 |
+
"model.layers.32.mlp.c_proj.weight": "model-00006-of-00007.safetensors",
|
| 430 |
+
"model.layers.32.post_attention_layernorm.bias": "model-00006-of-00007.safetensors",
|
| 431 |
+
"model.layers.32.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 432 |
+
"model.layers.32.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
| 433 |
+
"model.layers.32.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
| 434 |
+
"model.layers.32.self_attn.o_proj.bias": "model-00006-of-00007.safetensors",
|
| 435 |
+
"model.layers.32.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
| 436 |
+
"model.layers.32.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 437 |
+
"model.layers.32.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 438 |
+
"model.layers.32.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 439 |
+
"model.layers.32.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
| 440 |
+
"model.layers.33.input_layernorm.bias": "model-00006-of-00007.safetensors",
|
| 441 |
+
"model.layers.33.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 442 |
+
"model.layers.33.mlp.c_fc.bias": "model-00006-of-00007.safetensors",
|
| 443 |
+
"model.layers.33.mlp.c_fc.weight": "model-00006-of-00007.safetensors",
|
| 444 |
+
"model.layers.33.mlp.c_proj.bias": "model-00006-of-00007.safetensors",
|
| 445 |
+
"model.layers.33.mlp.c_proj.weight": "model-00006-of-00007.safetensors",
|
| 446 |
+
"model.layers.33.post_attention_layernorm.bias": "model-00006-of-00007.safetensors",
|
| 447 |
+
"model.layers.33.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 448 |
+
"model.layers.33.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
| 449 |
+
"model.layers.33.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
| 450 |
+
"model.layers.33.self_attn.o_proj.bias": "model-00006-of-00007.safetensors",
|
| 451 |
+
"model.layers.33.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
| 452 |
+
"model.layers.33.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 453 |
+
"model.layers.33.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 454 |
+
"model.layers.33.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 455 |
+
"model.layers.33.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
| 456 |
+
"model.layers.34.input_layernorm.bias": "model-00006-of-00007.safetensors",
|
| 457 |
+
"model.layers.34.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 458 |
+
"model.layers.34.mlp.c_fc.bias": "model-00006-of-00007.safetensors",
|
| 459 |
+
"model.layers.34.mlp.c_fc.weight": "model-00006-of-00007.safetensors",
|
| 460 |
+
"model.layers.34.mlp.c_proj.bias": "model-00006-of-00007.safetensors",
|
| 461 |
+
"model.layers.34.mlp.c_proj.weight": "model-00006-of-00007.safetensors",
|
| 462 |
+
"model.layers.34.post_attention_layernorm.bias": "model-00006-of-00007.safetensors",
|
| 463 |
+
"model.layers.34.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 464 |
+
"model.layers.34.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
| 465 |
+
"model.layers.34.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
| 466 |
+
"model.layers.34.self_attn.o_proj.bias": "model-00006-of-00007.safetensors",
|
| 467 |
+
"model.layers.34.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
| 468 |
+
"model.layers.34.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 469 |
+
"model.layers.34.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 470 |
+
"model.layers.34.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 471 |
+
"model.layers.34.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
| 472 |
+
"model.layers.35.input_layernorm.bias": "model-00006-of-00007.safetensors",
|
| 473 |
+
"model.layers.35.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 474 |
+
"model.layers.35.mlp.c_fc.bias": "model-00006-of-00007.safetensors",
|
| 475 |
+
"model.layers.35.mlp.c_fc.weight": "model-00006-of-00007.safetensors",
|
| 476 |
+
"model.layers.35.mlp.c_proj.bias": "model-00006-of-00007.safetensors",
|
| 477 |
+
"model.layers.35.mlp.c_proj.weight": "model-00006-of-00007.safetensors",
|
| 478 |
+
"model.layers.35.post_attention_layernorm.bias": "model-00006-of-00007.safetensors",
|
| 479 |
+
"model.layers.35.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 480 |
+
"model.layers.35.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
| 481 |
+
"model.layers.35.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
| 482 |
+
"model.layers.35.self_attn.o_proj.bias": "model-00006-of-00007.safetensors",
|
| 483 |
+
"model.layers.35.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
| 484 |
+
"model.layers.35.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 485 |
+
"model.layers.35.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 486 |
+
"model.layers.35.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 487 |
+
"model.layers.35.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
| 488 |
+
"model.layers.36.input_layernorm.bias": "model-00006-of-00007.safetensors",
|
| 489 |
+
"model.layers.36.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 490 |
+
"model.layers.36.mlp.c_fc.bias": "model-00006-of-00007.safetensors",
|
| 491 |
+
"model.layers.36.mlp.c_fc.weight": "model-00006-of-00007.safetensors",
|
| 492 |
+
"model.layers.36.mlp.c_proj.bias": "model-00006-of-00007.safetensors",
|
| 493 |
+
"model.layers.36.mlp.c_proj.weight": "model-00006-of-00007.safetensors",
|
| 494 |
+
"model.layers.36.post_attention_layernorm.bias": "model-00006-of-00007.safetensors",
|
| 495 |
+
"model.layers.36.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 496 |
+
"model.layers.36.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
| 497 |
+
"model.layers.36.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
| 498 |
+
"model.layers.36.self_attn.o_proj.bias": "model-00006-of-00007.safetensors",
|
| 499 |
+
"model.layers.36.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
| 500 |
+
"model.layers.36.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 501 |
+
"model.layers.36.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 502 |
+
"model.layers.36.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 503 |
+
"model.layers.36.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
| 504 |
+
"model.layers.37.input_layernorm.bias": "model-00006-of-00007.safetensors",
|
| 505 |
+
"model.layers.37.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 506 |
+
"model.layers.37.mlp.c_fc.bias": "model-00006-of-00007.safetensors",
|
| 507 |
+
"model.layers.37.mlp.c_fc.weight": "model-00006-of-00007.safetensors",
|
| 508 |
+
"model.layers.37.mlp.c_proj.bias": "model-00006-of-00007.safetensors",
|
| 509 |
+
"model.layers.37.mlp.c_proj.weight": "model-00006-of-00007.safetensors",
|
| 510 |
+
"model.layers.37.post_attention_layernorm.bias": "model-00006-of-00007.safetensors",
|
| 511 |
+
"model.layers.37.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 512 |
+
"model.layers.37.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
| 513 |
+
"model.layers.37.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
| 514 |
+
"model.layers.37.self_attn.o_proj.bias": "model-00006-of-00007.safetensors",
|
| 515 |
+
"model.layers.37.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
| 516 |
+
"model.layers.37.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 517 |
+
"model.layers.37.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 518 |
+
"model.layers.37.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 519 |
+
"model.layers.37.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
| 520 |
+
"model.layers.38.input_layernorm.bias": "model-00007-of-00007.safetensors",
|
| 521 |
+
"model.layers.38.input_layernorm.weight": "model-00007-of-00007.safetensors",
|
| 522 |
+
"model.layers.38.mlp.c_fc.bias": "model-00007-of-00007.safetensors",
|
| 523 |
+
"model.layers.38.mlp.c_fc.weight": "model-00007-of-00007.safetensors",
|
| 524 |
+
"model.layers.38.mlp.c_proj.bias": "model-00007-of-00007.safetensors",
|
| 525 |
+
"model.layers.38.mlp.c_proj.weight": "model-00007-of-00007.safetensors",
|
| 526 |
+
"model.layers.38.post_attention_layernorm.bias": "model-00007-of-00007.safetensors",
|
| 527 |
+
"model.layers.38.post_attention_layernorm.weight": "model-00007-of-00007.safetensors",
|
| 528 |
+
"model.layers.38.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
| 529 |
+
"model.layers.38.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
| 530 |
+
"model.layers.38.self_attn.o_proj.bias": "model-00007-of-00007.safetensors",
|
| 531 |
+
"model.layers.38.self_attn.o_proj.weight": "model-00007-of-00007.safetensors",
|
| 532 |
+
"model.layers.38.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 533 |
+
"model.layers.38.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 534 |
+
"model.layers.38.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 535 |
+
"model.layers.38.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
| 536 |
+
"model.layers.39.input_layernorm.bias": "model-00007-of-00007.safetensors",
|
| 537 |
+
"model.layers.39.input_layernorm.weight": "model-00007-of-00007.safetensors",
|
| 538 |
+
"model.layers.39.mlp.c_fc.bias": "model-00007-of-00007.safetensors",
|
| 539 |
+
"model.layers.39.mlp.c_fc.weight": "model-00007-of-00007.safetensors",
|
| 540 |
+
"model.layers.39.mlp.c_proj.bias": "model-00007-of-00007.safetensors",
|
| 541 |
+
"model.layers.39.mlp.c_proj.weight": "model-00007-of-00007.safetensors",
|
| 542 |
+
"model.layers.39.post_attention_layernorm.bias": "model-00007-of-00007.safetensors",
|
| 543 |
+
"model.layers.39.post_attention_layernorm.weight": "model-00007-of-00007.safetensors",
|
| 544 |
+
"model.layers.39.self_attn.k_proj.bias": "model-00007-of-00007.safetensors",
|
| 545 |
+
"model.layers.39.self_attn.k_proj.weight": "model-00007-of-00007.safetensors",
|
| 546 |
+
"model.layers.39.self_attn.o_proj.bias": "model-00007-of-00007.safetensors",
|
| 547 |
+
"model.layers.39.self_attn.o_proj.weight": "model-00007-of-00007.safetensors",
|
| 548 |
+
"model.layers.39.self_attn.q_proj.bias": "model-00007-of-00007.safetensors",
|
| 549 |
+
"model.layers.39.self_attn.q_proj.weight": "model-00007-of-00007.safetensors",
|
| 550 |
+
"model.layers.39.self_attn.v_proj.bias": "model-00007-of-00007.safetensors",
|
| 551 |
+
"model.layers.39.self_attn.v_proj.weight": "model-00007-of-00007.safetensors",
|
| 552 |
+
"model.layers.4.input_layernorm.bias": "model-00001-of-00007.safetensors",
|
| 553 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 554 |
+
"model.layers.4.mlp.c_fc.bias": "model-00001-of-00007.safetensors",
|
| 555 |
+
"model.layers.4.mlp.c_fc.weight": "model-00001-of-00007.safetensors",
|
| 556 |
+
"model.layers.4.mlp.c_proj.bias": "model-00001-of-00007.safetensors",
|
| 557 |
+
"model.layers.4.mlp.c_proj.weight": "model-00001-of-00007.safetensors",
|
| 558 |
+
"model.layers.4.post_attention_layernorm.bias": "model-00001-of-00007.safetensors",
|
| 559 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 560 |
+
"model.layers.4.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
| 561 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
| 562 |
+
"model.layers.4.self_attn.o_proj.bias": "model-00001-of-00007.safetensors",
|
| 563 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
| 564 |
+
"model.layers.4.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
| 565 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
| 566 |
+
"model.layers.4.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
| 567 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
| 568 |
+
"model.layers.5.input_layernorm.bias": "model-00002-of-00007.safetensors",
|
| 569 |
+
"model.layers.5.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 570 |
+
"model.layers.5.mlp.c_fc.bias": "model-00001-of-00007.safetensors",
|
| 571 |
+
"model.layers.5.mlp.c_fc.weight": "model-00001-of-00007.safetensors",
|
| 572 |
+
"model.layers.5.mlp.c_proj.bias": "model-00002-of-00007.safetensors",
|
| 573 |
+
"model.layers.5.mlp.c_proj.weight": "model-00002-of-00007.safetensors",
|
| 574 |
+
"model.layers.5.post_attention_layernorm.bias": "model-00002-of-00007.safetensors",
|
| 575 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 576 |
+
"model.layers.5.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
| 577 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
| 578 |
+
"model.layers.5.self_attn.o_proj.bias": "model-00001-of-00007.safetensors",
|
| 579 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
| 580 |
+
"model.layers.5.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
| 581 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
| 582 |
+
"model.layers.5.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
| 583 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
| 584 |
+
"model.layers.6.input_layernorm.bias": "model-00002-of-00007.safetensors",
|
| 585 |
+
"model.layers.6.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 586 |
+
"model.layers.6.mlp.c_fc.bias": "model-00002-of-00007.safetensors",
|
| 587 |
+
"model.layers.6.mlp.c_fc.weight": "model-00002-of-00007.safetensors",
|
| 588 |
+
"model.layers.6.mlp.c_proj.bias": "model-00002-of-00007.safetensors",
|
| 589 |
+
"model.layers.6.mlp.c_proj.weight": "model-00002-of-00007.safetensors",
|
| 590 |
+
"model.layers.6.post_attention_layernorm.bias": "model-00002-of-00007.safetensors",
|
| 591 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 592 |
+
"model.layers.6.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
| 593 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
| 594 |
+
"model.layers.6.self_attn.o_proj.bias": "model-00002-of-00007.safetensors",
|
| 595 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
| 596 |
+
"model.layers.6.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
| 597 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
| 598 |
+
"model.layers.6.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
| 599 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
| 600 |
+
"model.layers.7.input_layernorm.bias": "model-00002-of-00007.safetensors",
|
| 601 |
+
"model.layers.7.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 602 |
+
"model.layers.7.mlp.c_fc.bias": "model-00002-of-00007.safetensors",
|
| 603 |
+
"model.layers.7.mlp.c_fc.weight": "model-00002-of-00007.safetensors",
|
| 604 |
+
"model.layers.7.mlp.c_proj.bias": "model-00002-of-00007.safetensors",
|
| 605 |
+
"model.layers.7.mlp.c_proj.weight": "model-00002-of-00007.safetensors",
|
| 606 |
+
"model.layers.7.post_attention_layernorm.bias": "model-00002-of-00007.safetensors",
|
| 607 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 608 |
+
"model.layers.7.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
| 609 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
| 610 |
+
"model.layers.7.self_attn.o_proj.bias": "model-00002-of-00007.safetensors",
|
| 611 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
| 612 |
+
"model.layers.7.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
| 613 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
| 614 |
+
"model.layers.7.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
| 615 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
| 616 |
+
"model.layers.8.input_layernorm.bias": "model-00002-of-00007.safetensors",
|
| 617 |
+
"model.layers.8.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 618 |
+
"model.layers.8.mlp.c_fc.bias": "model-00002-of-00007.safetensors",
|
| 619 |
+
"model.layers.8.mlp.c_fc.weight": "model-00002-of-00007.safetensors",
|
| 620 |
+
"model.layers.8.mlp.c_proj.bias": "model-00002-of-00007.safetensors",
|
| 621 |
+
"model.layers.8.mlp.c_proj.weight": "model-00002-of-00007.safetensors",
|
| 622 |
+
"model.layers.8.post_attention_layernorm.bias": "model-00002-of-00007.safetensors",
|
| 623 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 624 |
+
"model.layers.8.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
| 625 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
| 626 |
+
"model.layers.8.self_attn.o_proj.bias": "model-00002-of-00007.safetensors",
|
| 627 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
| 628 |
+
"model.layers.8.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
| 629 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
| 630 |
+
"model.layers.8.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
| 631 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
| 632 |
+
"model.layers.9.input_layernorm.bias": "model-00002-of-00007.safetensors",
|
| 633 |
+
"model.layers.9.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 634 |
+
"model.layers.9.mlp.c_fc.bias": "model-00002-of-00007.safetensors",
|
| 635 |
+
"model.layers.9.mlp.c_fc.weight": "model-00002-of-00007.safetensors",
|
| 636 |
+
"model.layers.9.mlp.c_proj.bias": "model-00002-of-00007.safetensors",
|
| 637 |
+
"model.layers.9.mlp.c_proj.weight": "model-00002-of-00007.safetensors",
|
| 638 |
+
"model.layers.9.post_attention_layernorm.bias": "model-00002-of-00007.safetensors",
|
| 639 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 640 |
+
"model.layers.9.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
| 641 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
| 642 |
+
"model.layers.9.self_attn.o_proj.bias": "model-00002-of-00007.safetensors",
|
| 643 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
| 644 |
+
"model.layers.9.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
| 645 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
| 646 |
+
"model.layers.9.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
| 647 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
| 648 |
+
"model.norm.bias": "model-00007-of-00007.safetensors",
|
| 649 |
+
"model.norm.weight": "model-00007-of-00007.safetensors"
|
| 650 |
+
}
|
| 651 |
+
}
|
output-00001-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:68a9424aa1f74ce67a6d454596522b524d0d53467aef30ab58e81500ef4effc6
|
| 3 |
+
size 8490911308
|
output-00002-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:57dd51f237bb2de859df224362ce15bfcb0e1cbfd713d45bd5f292b2bf6e9f9c
|
| 3 |
+
size 4879409672
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|endoftext|>",
|
| 4 |
+
"<fim_prefix>",
|
| 5 |
+
"<fim_middle>",
|
| 6 |
+
"<fim_suffix>",
|
| 7 |
+
"<fim_pad>",
|
| 8 |
+
"<repo_name>",
|
| 9 |
+
"<file_sep>",
|
| 10 |
+
"<issue_start>",
|
| 11 |
+
"<issue_comment>",
|
| 12 |
+
"<issue_closed>",
|
| 13 |
+
"<jupyter_start>",
|
| 14 |
+
"<jupyter_text>",
|
| 15 |
+
"<jupyter_code>",
|
| 16 |
+
"<jupyter_output>",
|
| 17 |
+
"<jupyter_script>",
|
| 18 |
+
"<empty_output>",
|
| 19 |
+
"<code_to_intermediate>",
|
| 20 |
+
"<intermediate_to_code>",
|
| 21 |
+
"<pr>",
|
| 22 |
+
"<pr_status>",
|
| 23 |
+
"<pr_is_merged>",
|
| 24 |
+
"<pr_base>",
|
| 25 |
+
"<pr_file>",
|
| 26 |
+
"<pr_base_code>",
|
| 27 |
+
"<pr_diff>",
|
| 28 |
+
"<pr_diff_hunk>",
|
| 29 |
+
"<pr_comment>",
|
| 30 |
+
"<pr_event_id>",
|
| 31 |
+
"<pr_review>",
|
| 32 |
+
"<pr_review_state>",
|
| 33 |
+
"<pr_review_comment>",
|
| 34 |
+
"<pr_in_reply_to_review_id>",
|
| 35 |
+
"<pr_in_reply_to_comment_id>",
|
| 36 |
+
"<pr_diff_hunk_comment_line>",
|
| 37 |
+
"<NAME>",
|
| 38 |
+
"<EMAIL>",
|
| 39 |
+
"<KEY>",
|
| 40 |
+
"<PASSWORD>"
|
| 41 |
+
],
|
| 42 |
+
"bos_token": {
|
| 43 |
+
"content": "<|endoftext|>",
|
| 44 |
+
"lstrip": false,
|
| 45 |
+
"normalized": false,
|
| 46 |
+
"rstrip": false,
|
| 47 |
+
"single_word": false
|
| 48 |
+
},
|
| 49 |
+
"eos_token": {
|
| 50 |
+
"content": "<|endoftext|>",
|
| 51 |
+
"lstrip": false,
|
| 52 |
+
"normalized": false,
|
| 53 |
+
"rstrip": false,
|
| 54 |
+
"single_word": false
|
| 55 |
+
},
|
| 56 |
+
"unk_token": {
|
| 57 |
+
"content": "<|endoftext|>",
|
| 58 |
+
"lstrip": false,
|
| 59 |
+
"normalized": false,
|
| 60 |
+
"rstrip": false,
|
| 61 |
+
"single_word": false
|
| 62 |
+
}
|
| 63 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,357 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"0": {
|
| 5 |
+
"content": "<|endoftext|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"1": {
|
| 13 |
+
"content": "<fim_prefix>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"2": {
|
| 21 |
+
"content": "<fim_middle>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
},
|
| 28 |
+
"3": {
|
| 29 |
+
"content": "<fim_suffix>",
|
| 30 |
+
"lstrip": false,
|
| 31 |
+
"normalized": false,
|
| 32 |
+
"rstrip": false,
|
| 33 |
+
"single_word": false,
|
| 34 |
+
"special": true
|
| 35 |
+
},
|
| 36 |
+
"4": {
|
| 37 |
+
"content": "<fim_pad>",
|
| 38 |
+
"lstrip": false,
|
| 39 |
+
"normalized": false,
|
| 40 |
+
"rstrip": false,
|
| 41 |
+
"single_word": false,
|
| 42 |
+
"special": true
|
| 43 |
+
},
|
| 44 |
+
"5": {
|
| 45 |
+
"content": "<repo_name>",
|
| 46 |
+
"lstrip": false,
|
| 47 |
+
"normalized": false,
|
| 48 |
+
"rstrip": false,
|
| 49 |
+
"single_word": false,
|
| 50 |
+
"special": true
|
| 51 |
+
},
|
| 52 |
+
"6": {
|
| 53 |
+
"content": "<file_sep>",
|
| 54 |
+
"lstrip": false,
|
| 55 |
+
"normalized": false,
|
| 56 |
+
"rstrip": false,
|
| 57 |
+
"single_word": false,
|
| 58 |
+
"special": true
|
| 59 |
+
},
|
| 60 |
+
"7": {
|
| 61 |
+
"content": "<issue_start>",
|
| 62 |
+
"lstrip": false,
|
| 63 |
+
"normalized": false,
|
| 64 |
+
"rstrip": false,
|
| 65 |
+
"single_word": false,
|
| 66 |
+
"special": true
|
| 67 |
+
},
|
| 68 |
+
"8": {
|
| 69 |
+
"content": "<issue_comment>",
|
| 70 |
+
"lstrip": false,
|
| 71 |
+
"normalized": false,
|
| 72 |
+
"rstrip": false,
|
| 73 |
+
"single_word": false,
|
| 74 |
+
"special": true
|
| 75 |
+
},
|
| 76 |
+
"9": {
|
| 77 |
+
"content": "<issue_closed>",
|
| 78 |
+
"lstrip": false,
|
| 79 |
+
"normalized": false,
|
| 80 |
+
"rstrip": false,
|
| 81 |
+
"single_word": false,
|
| 82 |
+
"special": true
|
| 83 |
+
},
|
| 84 |
+
"10": {
|
| 85 |
+
"content": "<jupyter_start>",
|
| 86 |
+
"lstrip": false,
|
| 87 |
+
"normalized": false,
|
| 88 |
+
"rstrip": false,
|
| 89 |
+
"single_word": false,
|
| 90 |
+
"special": true
|
| 91 |
+
},
|
| 92 |
+
"11": {
|
| 93 |
+
"content": "<jupyter_text>",
|
| 94 |
+
"lstrip": false,
|
| 95 |
+
"normalized": false,
|
| 96 |
+
"rstrip": false,
|
| 97 |
+
"single_word": false,
|
| 98 |
+
"special": true
|
| 99 |
+
},
|
| 100 |
+
"12": {
|
| 101 |
+
"content": "<jupyter_code>",
|
| 102 |
+
"lstrip": false,
|
| 103 |
+
"normalized": false,
|
| 104 |
+
"rstrip": false,
|
| 105 |
+
"single_word": false,
|
| 106 |
+
"special": true
|
| 107 |
+
},
|
| 108 |
+
"13": {
|
| 109 |
+
"content": "<jupyter_output>",
|
| 110 |
+
"lstrip": false,
|
| 111 |
+
"normalized": false,
|
| 112 |
+
"rstrip": false,
|
| 113 |
+
"single_word": false,
|
| 114 |
+
"special": true
|
| 115 |
+
},
|
| 116 |
+
"14": {
|
| 117 |
+
"content": "<jupyter_script>",
|
| 118 |
+
"lstrip": false,
|
| 119 |
+
"normalized": false,
|
| 120 |
+
"rstrip": false,
|
| 121 |
+
"single_word": false,
|
| 122 |
+
"special": true
|
| 123 |
+
},
|
| 124 |
+
"15": {
|
| 125 |
+
"content": "<empty_output>",
|
| 126 |
+
"lstrip": false,
|
| 127 |
+
"normalized": false,
|
| 128 |
+
"rstrip": false,
|
| 129 |
+
"single_word": false,
|
| 130 |
+
"special": true
|
| 131 |
+
},
|
| 132 |
+
"16": {
|
| 133 |
+
"content": "<code_to_intermediate>",
|
| 134 |
+
"lstrip": false,
|
| 135 |
+
"normalized": false,
|
| 136 |
+
"rstrip": false,
|
| 137 |
+
"single_word": false,
|
| 138 |
+
"special": true
|
| 139 |
+
},
|
| 140 |
+
"17": {
|
| 141 |
+
"content": "<intermediate_to_code>",
|
| 142 |
+
"lstrip": false,
|
| 143 |
+
"normalized": false,
|
| 144 |
+
"rstrip": false,
|
| 145 |
+
"single_word": false,
|
| 146 |
+
"special": true
|
| 147 |
+
},
|
| 148 |
+
"18": {
|
| 149 |
+
"content": "<pr>",
|
| 150 |
+
"lstrip": false,
|
| 151 |
+
"normalized": false,
|
| 152 |
+
"rstrip": false,
|
| 153 |
+
"single_word": false,
|
| 154 |
+
"special": true
|
| 155 |
+
},
|
| 156 |
+
"19": {
|
| 157 |
+
"content": "<pr_status>",
|
| 158 |
+
"lstrip": false,
|
| 159 |
+
"normalized": false,
|
| 160 |
+
"rstrip": false,
|
| 161 |
+
"single_word": false,
|
| 162 |
+
"special": true
|
| 163 |
+
},
|
| 164 |
+
"20": {
|
| 165 |
+
"content": "<pr_is_merged>",
|
| 166 |
+
"lstrip": false,
|
| 167 |
+
"normalized": false,
|
| 168 |
+
"rstrip": false,
|
| 169 |
+
"single_word": false,
|
| 170 |
+
"special": true
|
| 171 |
+
},
|
| 172 |
+
"21": {
|
| 173 |
+
"content": "<pr_base>",
|
| 174 |
+
"lstrip": false,
|
| 175 |
+
"normalized": false,
|
| 176 |
+
"rstrip": false,
|
| 177 |
+
"single_word": false,
|
| 178 |
+
"special": true
|
| 179 |
+
},
|
| 180 |
+
"22": {
|
| 181 |
+
"content": "<pr_file>",
|
| 182 |
+
"lstrip": false,
|
| 183 |
+
"normalized": false,
|
| 184 |
+
"rstrip": false,
|
| 185 |
+
"single_word": false,
|
| 186 |
+
"special": true
|
| 187 |
+
},
|
| 188 |
+
"23": {
|
| 189 |
+
"content": "<pr_base_code>",
|
| 190 |
+
"lstrip": false,
|
| 191 |
+
"normalized": false,
|
| 192 |
+
"rstrip": false,
|
| 193 |
+
"single_word": false,
|
| 194 |
+
"special": true
|
| 195 |
+
},
|
| 196 |
+
"24": {
|
| 197 |
+
"content": "<pr_diff>",
|
| 198 |
+
"lstrip": false,
|
| 199 |
+
"normalized": false,
|
| 200 |
+
"rstrip": false,
|
| 201 |
+
"single_word": false,
|
| 202 |
+
"special": true
|
| 203 |
+
},
|
| 204 |
+
"25": {
|
| 205 |
+
"content": "<pr_diff_hunk>",
|
| 206 |
+
"lstrip": false,
|
| 207 |
+
"normalized": false,
|
| 208 |
+
"rstrip": false,
|
| 209 |
+
"single_word": false,
|
| 210 |
+
"special": true
|
| 211 |
+
},
|
| 212 |
+
"26": {
|
| 213 |
+
"content": "<pr_comment>",
|
| 214 |
+
"lstrip": false,
|
| 215 |
+
"normalized": false,
|
| 216 |
+
"rstrip": false,
|
| 217 |
+
"single_word": false,
|
| 218 |
+
"special": true
|
| 219 |
+
},
|
| 220 |
+
"27": {
|
| 221 |
+
"content": "<pr_event_id>",
|
| 222 |
+
"lstrip": false,
|
| 223 |
+
"normalized": false,
|
| 224 |
+
"rstrip": false,
|
| 225 |
+
"single_word": false,
|
| 226 |
+
"special": true
|
| 227 |
+
},
|
| 228 |
+
"28": {
|
| 229 |
+
"content": "<pr_review>",
|
| 230 |
+
"lstrip": false,
|
| 231 |
+
"normalized": false,
|
| 232 |
+
"rstrip": false,
|
| 233 |
+
"single_word": false,
|
| 234 |
+
"special": true
|
| 235 |
+
},
|
| 236 |
+
"29": {
|
| 237 |
+
"content": "<pr_review_state>",
|
| 238 |
+
"lstrip": false,
|
| 239 |
+
"normalized": false,
|
| 240 |
+
"rstrip": false,
|
| 241 |
+
"single_word": false,
|
| 242 |
+
"special": true
|
| 243 |
+
},
|
| 244 |
+
"30": {
|
| 245 |
+
"content": "<pr_review_comment>",
|
| 246 |
+
"lstrip": false,
|
| 247 |
+
"normalized": false,
|
| 248 |
+
"rstrip": false,
|
| 249 |
+
"single_word": false,
|
| 250 |
+
"special": true
|
| 251 |
+
},
|
| 252 |
+
"31": {
|
| 253 |
+
"content": "<pr_in_reply_to_review_id>",
|
| 254 |
+
"lstrip": false,
|
| 255 |
+
"normalized": false,
|
| 256 |
+
"rstrip": false,
|
| 257 |
+
"single_word": false,
|
| 258 |
+
"special": true
|
| 259 |
+
},
|
| 260 |
+
"32": {
|
| 261 |
+
"content": "<pr_in_reply_to_comment_id>",
|
| 262 |
+
"lstrip": false,
|
| 263 |
+
"normalized": false,
|
| 264 |
+
"rstrip": false,
|
| 265 |
+
"single_word": false,
|
| 266 |
+
"special": true
|
| 267 |
+
},
|
| 268 |
+
"33": {
|
| 269 |
+
"content": "<pr_diff_hunk_comment_line>",
|
| 270 |
+
"lstrip": false,
|
| 271 |
+
"normalized": false,
|
| 272 |
+
"rstrip": false,
|
| 273 |
+
"single_word": false,
|
| 274 |
+
"special": true
|
| 275 |
+
},
|
| 276 |
+
"34": {
|
| 277 |
+
"content": "<NAME>",
|
| 278 |
+
"lstrip": false,
|
| 279 |
+
"normalized": false,
|
| 280 |
+
"rstrip": false,
|
| 281 |
+
"single_word": false,
|
| 282 |
+
"special": true
|
| 283 |
+
},
|
| 284 |
+
"35": {
|
| 285 |
+
"content": "<EMAIL>",
|
| 286 |
+
"lstrip": false,
|
| 287 |
+
"normalized": false,
|
| 288 |
+
"rstrip": false,
|
| 289 |
+
"single_word": false,
|
| 290 |
+
"special": true
|
| 291 |
+
},
|
| 292 |
+
"36": {
|
| 293 |
+
"content": "<KEY>",
|
| 294 |
+
"lstrip": false,
|
| 295 |
+
"normalized": false,
|
| 296 |
+
"rstrip": false,
|
| 297 |
+
"single_word": false,
|
| 298 |
+
"special": true
|
| 299 |
+
},
|
| 300 |
+
"37": {
|
| 301 |
+
"content": "<PASSWORD>",
|
| 302 |
+
"lstrip": false,
|
| 303 |
+
"normalized": false,
|
| 304 |
+
"rstrip": false,
|
| 305 |
+
"single_word": false,
|
| 306 |
+
"special": true
|
| 307 |
+
}
|
| 308 |
+
},
|
| 309 |
+
"additional_special_tokens": [
|
| 310 |
+
"<|endoftext|>",
|
| 311 |
+
"<fim_prefix>",
|
| 312 |
+
"<fim_middle>",
|
| 313 |
+
"<fim_suffix>",
|
| 314 |
+
"<fim_pad>",
|
| 315 |
+
"<repo_name>",
|
| 316 |
+
"<file_sep>",
|
| 317 |
+
"<issue_start>",
|
| 318 |
+
"<issue_comment>",
|
| 319 |
+
"<issue_closed>",
|
| 320 |
+
"<jupyter_start>",
|
| 321 |
+
"<jupyter_text>",
|
| 322 |
+
"<jupyter_code>",
|
| 323 |
+
"<jupyter_output>",
|
| 324 |
+
"<jupyter_script>",
|
| 325 |
+
"<empty_output>",
|
| 326 |
+
"<code_to_intermediate>",
|
| 327 |
+
"<intermediate_to_code>",
|
| 328 |
+
"<pr>",
|
| 329 |
+
"<pr_status>",
|
| 330 |
+
"<pr_is_merged>",
|
| 331 |
+
"<pr_base>",
|
| 332 |
+
"<pr_file>",
|
| 333 |
+
"<pr_base_code>",
|
| 334 |
+
"<pr_diff>",
|
| 335 |
+
"<pr_diff_hunk>",
|
| 336 |
+
"<pr_comment>",
|
| 337 |
+
"<pr_event_id>",
|
| 338 |
+
"<pr_review>",
|
| 339 |
+
"<pr_review_state>",
|
| 340 |
+
"<pr_review_comment>",
|
| 341 |
+
"<pr_in_reply_to_review_id>",
|
| 342 |
+
"<pr_in_reply_to_comment_id>",
|
| 343 |
+
"<pr_diff_hunk_comment_line>",
|
| 344 |
+
"<NAME>",
|
| 345 |
+
"<EMAIL>",
|
| 346 |
+
"<KEY>",
|
| 347 |
+
"<PASSWORD>"
|
| 348 |
+
],
|
| 349 |
+
"bos_token": "<|endoftext|>",
|
| 350 |
+
"chat_template": "{{bos_token}}{{'You are an exceptionally intelligent coding assistant that consistently delivers accurate and reliable responses to user instructions.\n\n'}}\n{%- for message in messages %}\n {%- if message['role'] == 'system' %}\n {{ raise_exception('System messages are not allowed in this template.') }}\n {%- else %}\n {%- if message['role'] == 'user' %}\n{{'### Instruction\n' + message['content'] + '\n\n'}}\n {%- else %}\n{{'### Response\n' + message['content'] + eos_token + '\n\n'}}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{{'### Response\n'}}",
|
| 351 |
+
"clean_up_tokenization_spaces": true,
|
| 352 |
+
"eos_token": "<|endoftext|>",
|
| 353 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 354 |
+
"tokenizer_class": "GPT2Tokenizer",
|
| 355 |
+
"unk_token": "<|endoftext|>",
|
| 356 |
+
"vocab_size": 49152
|
| 357 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|